 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMT-VAE: Learning Motion Transformations to Generate Multimodal Human Dynamics
Paper and Code
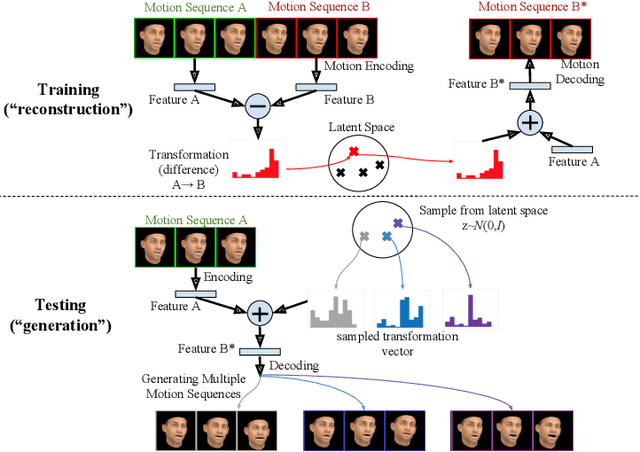
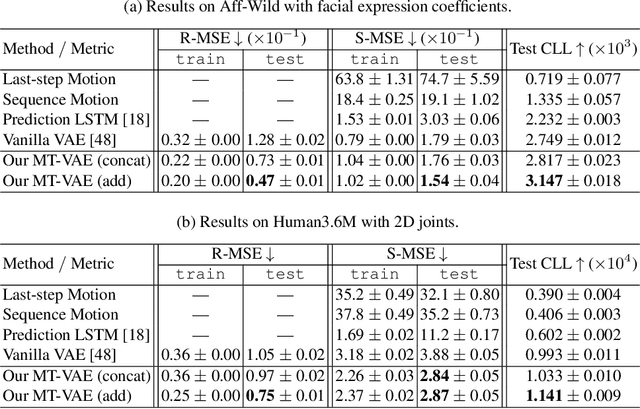
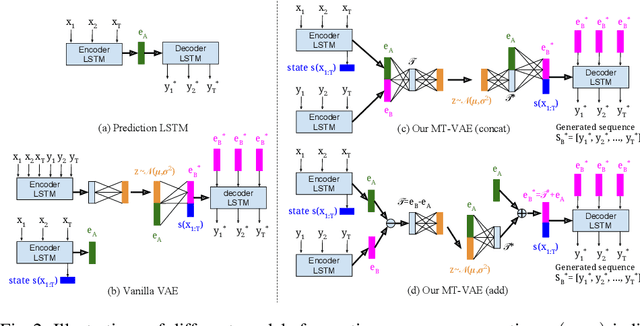

Long-term human motion can be represented as a series of motion modes---motion sequences that capture short-term temporal dynamics---with transitions between them. We leverage this structure and present a novel Motion Transformation Variational Auto-Encoders (MT-VAE) for learning motion sequence generation. Our model jointly learns a feature embedding for motion modes (that the motion sequence can be reconstructed from) and a feature transformation that represents the transition of one motion mode to the next motion mode. Our model is able to generate multiple diverse and plausible motion sequences in the future from the same input. We apply our approach to both facial and full body motion, and demonstrate applications like analogy-based motion transfer and video synthesis.