 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemanticAdv: Generating Adversarial Examples via Attribute-conditional Image Editing
Paper and Code


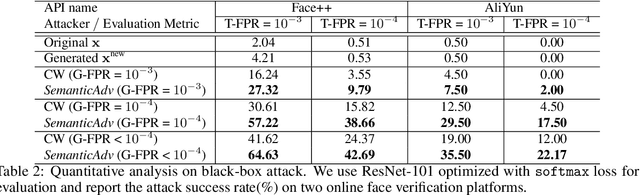
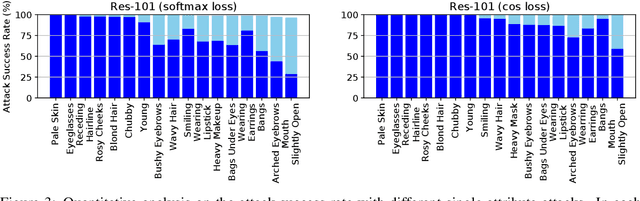
Deep neural networks (DNNs) have achieved great success in various applications due to their strong expressive power. However, recent studies have shown that DNNs are vulnerable to adversarial examples which are manipulated instances targeting to mislead DNNs to make incorrect predictions. Currently, most such adversarial examples try to guarantee "subtle perturbation" by limiting its $L_p$ norm. In this paper, we aim to explore the impact of semantic manipulation on DNNs predictions by manipulating the semantic attributes of images and generate "unrestricted adversarial examples". Such semantic based perturbation is more practical compared with pixel level manipulation. In particular, we propose an algorithm SemanticAdv which leverages disentangled semantic factors to generate adversarial perturbation via altering either single or a combination of semantic attributes. We conduct extensive experiments to show that the semantic based adversarial examples can not only fool different learning tasks such as face verification and landmark detection, but also achieve high attack success rate against real-world black-box services such as Azure face verification service. Such structured adversarial examples with controlled semantic manipulation can shed light on further understanding about vulnerabilities of DNNs as well as potential defensive approaches.