 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergistic Global-space Camera and Human Reconstruction from Videos
May 23, 2024



Remarkable strides have been made in reconstructing static scenes or human bodies from monocular videos. Yet, the two problems have largely been approached independently, without much synergy. Most visual SLAM methods can only reconstruct camera trajectories and scene structures up to scale, while most HMR methods reconstruct human meshes in metric scale but fall short in reasoning with cameras and scenes. This work introduces Synergistic Camera and Human Reconstruction (SynCHMR) to marry the best of both worlds. Specifically, we design Human-aware Metric SLAM to reconstruct metric-scale camera poses and scene point clouds using camera-frame HMR as a strong prior, addressing depth, scale, and dynamic ambiguities. Conditioning on the dense scene recovered, we further learn a Scene-aware SMPL Denoiser to enhance world-frame HMR by incorporating spatio-temporal coherency and dynamic scene constraints. Together, they lead to consistent reconstructions of camera trajectories, human meshes, and dense scene point clouds in a common world frame. Project page: https://paulchhuang.github.io/synchmr
Customize-A-Video: One-Shot Motion Customization of Text-to-Video Diffusion Models
Feb 22, 2024



Image customization has been extensively studied in text-to-image (T2I) diffusion models, leading to impressive outcomes and applications. With the emergence of text-to-video (T2V) diffusion models, its temporal counterpart, motion customization, has not yet been well investigated. To address the challenge of one-shot motion customization, we propose Customize-A-Video that models the motion from a single reference video and adapting it to new subjects and scenes with both spatial and temporal varieties. It leverages low-rank adaptation (LoRA) on temporal attention layers to tailor the pre-trained T2V diffusion model for specific motion modeling from the reference videos. To disentangle the spatial and temporal information during the training pipeline, we introduce a novel concept of appearance absorbers that detach the original appearance from the single reference video prior to motion learning. Our proposed method can be easily extended to various downstream tasks, including custom video generation and editing, video appearance customization, and multiple motion combination, in a plug-and-play fashion. Our project page can be found at https://anonymous-314.github.io.
Single-View 3D Human Digitalization with Large Reconstruction Models
Jan 22, 2024



In this paper, we introduce Human-LRM, a single-stage feed-forward Large Reconstruction Model designed to predict human Neural Radiance Fields (NeRF) from a single image. Our approach demonstrates remarkable adaptability in training using extensive datasets containing 3D scans and multi-view capture. Furthermore, to enhance the model's applicability for in-the-wild scenarios especially with occlusions, we propose a novel strategy that distills multi-view reconstruction into single-view via a conditional triplane diffusion model. This generative extension addresses the inherent variations in human body shapes when observed from a single view, and makes it possible to reconstruct the full body human from an occluded image. Through extensive experiments, we show that Human-LRM surpasses previous methods by a significant margin on several benchmarks.
ActAnywhere: Subject-Aware Video Background Generation
Jan 19, 2024Generating video background that tailors to foreground subject motion is an important problem for the movie industry and visual effects community. This task involves synthesizing background that aligns with the motion and appearance of the foreground subject, while also complies with the artist's creative intention. We introduce ActAnywhere, a generative model that automates this process which traditionally requires tedious manual efforts. Our model leverages the power of large-scale video diffusion models, and is specifically tailored for this task. ActAnywhere takes a sequence of foreground subject segmentation as input and an image that describes the desired scene as condition, to produce a coherent video with realistic foreground-background interactions while adhering to the condition frame. We train our model on a large-scale dataset of human-scene interaction videos. Extensive evaluations demonstrate the superior performance of our model, significantly outperforming baselines. Moreover, we show that ActAnywhere generalizes to diverse out-of-distribution samples, including non-human subjects. Please visit our project webpage at https://actanywhere.github.io.
ContactGen: Generative Contact Modeling for Grasp Generation
Oct 05, 2023



This paper presents a novel object-centric contact representation ContactGen for hand-object interaction. The ContactGen comprises three components: a contact map indicates the contact location, a part map represents the contact hand part, and a direction map tells the contact direction within each part. Given an input object, we propose a conditional generative model to predict ContactGen and adopt model-based optimization to predict diverse and geometrically feasible grasps. Experimental results demonstrate our method can generate high-fidelity and diverse human grasps for various objects. Project page: https://stevenlsw.github.io/contactgen/
Putting People in Their Place: Affordance-Aware Human Insertion into Scenes
Apr 27, 2023
We study the problem of inferring scene affordances by presenting a method for realistically inserting people into scenes. Given a scene image with a marked region and an image of a person, we insert the person into the scene while respecting the scene affordances. Our model can infer the set of realistic poses given the scene context, re-pose the reference person, and harmonize the composition. We set up the task in a self-supervised fashion by learning to re-pose humans in video clips. We train a large-scale diffusion model on a dataset of 2.4M video clips that produces diverse plausible poses while respecting the scene context. Given the learned human-scene composition, our model can also hallucinate realistic people and scenes when prompted without conditioning and also enables interactive editing. A quantitative evaluation shows that our method synthesizes more realistic human appearance and more natural human-scene interactions than prior work.
Normal-guided Garment UV Prediction for Human Re-texturing
Mar 11, 2023



Clothes undergo complex geometric deformations, which lead to appearance changes. To edit human videos in a physically plausible way, a texture map must take into account not only the garment transformation induced by the body movements and clothes fitting, but also its 3D fine-grained surface geometry. This poses, however, a new challenge of 3D reconstruction of dynamic clothes from an image or a video. In this paper, we show that it is possible to edit dressed human images and videos without 3D reconstruction. We estimate a geometry aware texture map between the garment region in an image and the texture space, a.k.a, UV map. Our UV map is designed to preserve isometry with respect to the underlying 3D surface by making use of the 3D surface normals predicted from the image. Our approach captures the underlying geometry of the garment in a self-supervised way, requiring no ground truth annotation of UV maps and can be readily extended to predict temporally coherent UV maps. We demonstrate that our method outperforms the state-of-the-art human UV map estimation approaches on both real and synthetic data.
Learning Visibility for Robust Dense Human Body Estimation
Aug 23, 2022
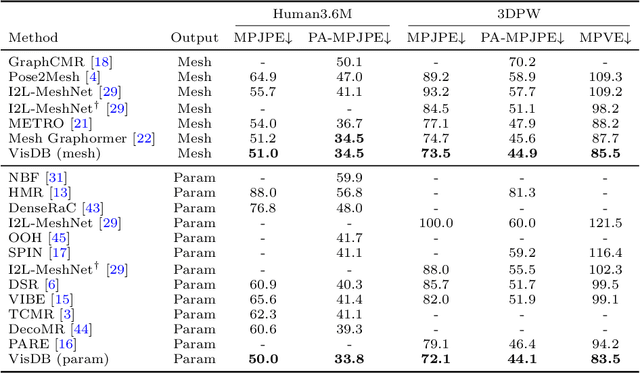
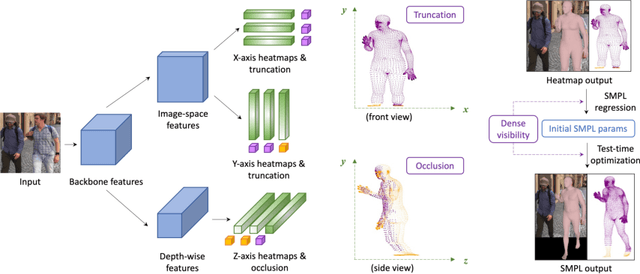

Estimating 3D human pose and shape from 2D images is a crucial yet challenging task. While prior methods with model-based representations can perform reasonably well on whole-body images, they often fail when parts of the body are occluded or outside the frame. Moreover, these results usually do not faithfully capture the human silhouettes due to their limited representation power of deformable models (e.g., representing only the naked body). An alternative approach is to estimate dense vertices of a predefined template body in the image space. Such representations are effective in localizing vertices within an image but cannot handle out-of-frame body parts. In this work, we learn dense human body estimation that is robust to partial observations. We explicitly model the visibility of human joints and vertices in the x, y, and z axes separately. The visibility in x and y axes help distinguishing out-of-frame cases, and the visibility in depth axis corresponds to occlusions (either self-occlusions or occlusions by other objects). We obtain pseudo ground-truths of visibility labels from dense UV correspondences and train a neural network to predict visibility along with 3D coordinates. We show that visibility can serve as 1) an additional signal to resolve depth ordering ambiguities of self-occluded vertices and 2) a regularization term when fitting a human body model to the predictions. Extensive experiments on multiple 3D human datasets demonstrate that visibility modeling significantly improves the accuracy of human body estimation, especially for partial-body cases. Our project page with code is at: https://github.com/chhankyao/visdb.
Skeleton-free Pose Transfer for Stylized 3D Characters
Jul 28, 2022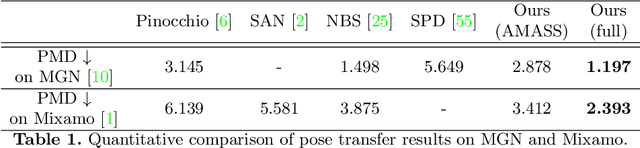
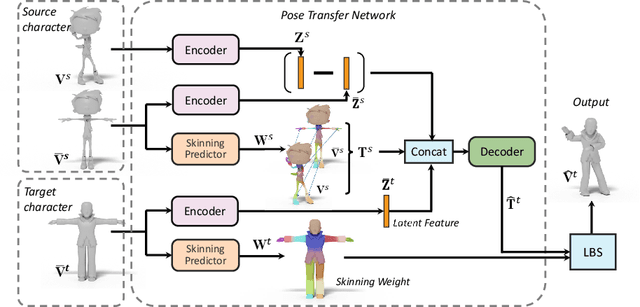
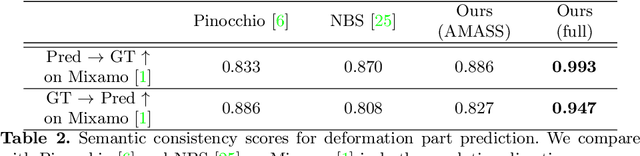

We present the first method that automatically transfers poses between stylized 3D characters without skeletal rigging. In contrast to previous attempts to learn pose transformations on fixed or topology-equivalent skeleton templates, our method focuses on a novel scenario to handle skeleton-free characters with diverse shapes, topologies, and mesh connectivities. The key idea of our method is to represent the characters in a unified articulation model so that the pose can be transferred through the correspondent parts. To achieve this, we propose a novel pose transfer network that predicts the character skinning weights and deformation transformations jointly to articulate the target character to match the desired pose. Our method is trained in a semi-supervised manner absorbing all existing character data with paired/unpaired poses and stylized shapes. It generalizes well to unseen stylized characters and inanimate objects. We conduct extensive experiments and demonstrate the effectiveness of our method on this novel task.
Audio-driven Neural Gesture Reenactment with Video Motion Graphs
Jul 23, 2022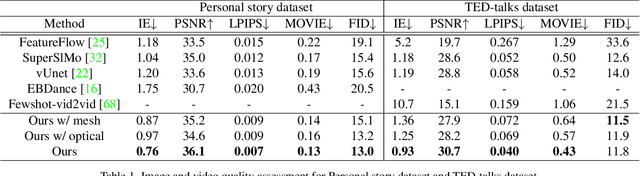
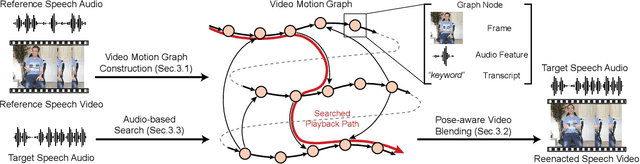
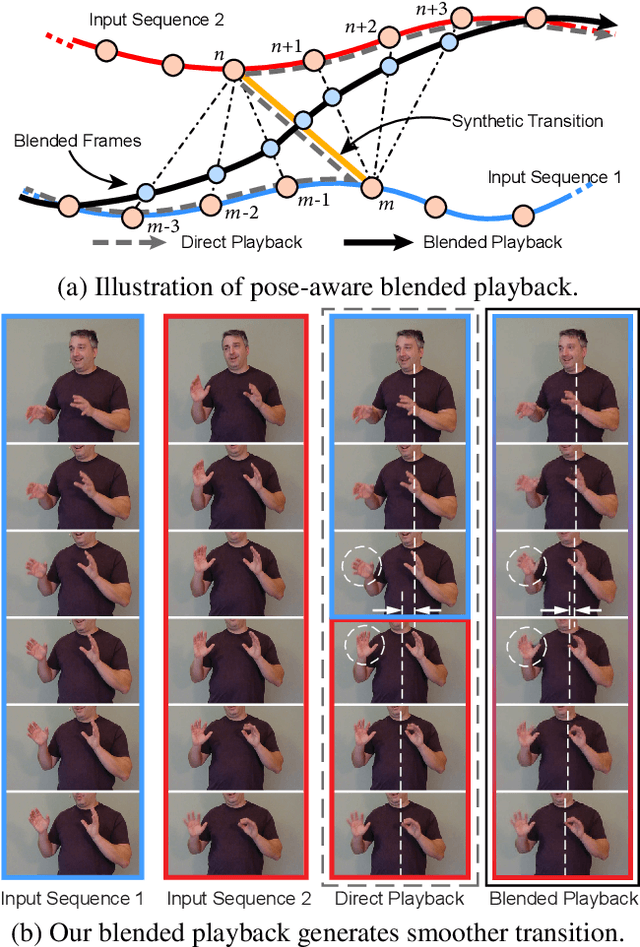
Human speech is often accompanied by body gestures including arm and hand gestures. We present a method that reenacts a high-quality video with gestures matching a target speech audio. The key idea of our method is to split and re-assemble clips from a reference video through a novel video motion graph encoding valid transitions between clips. To seamlessly connect different clips in the reenactment, we propose a pose-aware video blending network which synthesizes video frames around the stitched frames between two clips. Moreover, we developed an audio-based gesture searching algorithm to find the optimal order of the reenacted frames. Our system generates reenactments that are consistent with both the audio rhythms and the speech content. We evaluate our synthesized video quality quantitatively, qualitatively, and with user studies, demonstrating that our method produces videos of much higher quality and consistency with the target audio compared to previous work and baselines.