 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinite Mask Diffusion for Few-Step Distillation
May 11, 2026Masked Diffusion Models (MDMs) have emerged as a promising alternative to autoregressive models in language modeling, offering the advantages of parallel decoding and bidirectional context processing within a simple yet effective framework. Specifically, their explicit distinction between masked tokens and data underlies their simple framework and effective conditional generation. However, MDMs typically require many sampling iterations due to factorization errors stemming from simultaneous token updates. We observe that a theoretical lower bound of the factorization error exists, which standard MDMs cannot reduce due to their use of a deterministic single-state mask. In this paper, we propose the Infinite Mask Diffusion Model (IMDM), which introduces a stochastic infinite-state mask to mitigate the theoretical bound while directly inheriting the benefits of MDMs, including the compatibility with pre-trained weights. We empirically demonstrate that MDM fails to perform few-step generation even in a simple synthetic task due to the factorization error bound, whereas IMDM can find an efficient solution for the same task. Finally, when equipped with appropriate distillation methods, IMDM surpasses existing few-step distillation methods at small step counts on LM1B and OpenWebText. Code is available at https://Ugness.github.io/official_imdm.
Training-Free Refinement of Flow Matching with Divergence-based Sampling
Apr 06, 2026Flow-based models learn a target distribution by modeling a marginal velocity field, defined as the average of sample-wise velocities connecting each sample from a simple prior to the target data. When sample-wise velocities conflict at the same intermediate state, however, this averaged velocity can misguide samples toward low-density regions, degrading generation quality. To address this issue, we propose the Flow Divergence Sampler (FDS), a training-free framework that refines intermediate states before each solver step. Our key finding reveals that the severity of this misguidance is quantified by the divergence of the marginal velocity field that is readily computable during inference with a well-optimized model. FDS exploits this signal to steer states toward less ambiguous regions. As a plug-and-play framework compatible with standard solvers and off-the-shelf flow backbones, FDS consistently improves fidelity across various generation tasks including text-to-image synthesis, and inverse problems.
When Sinks Help or Hurt: Unified Framework for Attention Sink in Large Vision-Language Models
Apr 01, 2026Attention sinks are defined as tokens that attract disproportionate attention. While these have been studied in single modality transformers, their cross-modal impact in Large Vision-Language Models (LVLM) remains largely unexplored: are they redundant artifacts or essential global priors? This paper first categorizes visual sinks into two distinct categories: ViT-emerged sinks (V-sinks), which propagate from the vision encoder, and LLM-emerged sinks (L-sinks), which arise within deep LLM layers. Based on the new definition, our analysis reveals a fundamental performance trade-off: while sinks effectively encode global scene-level priors, their dominance can suppress the fine-grained visual evidence required for local perception. Furthermore, we identify specific functional layers where modulating these sinks most significantly impacts downstream performance. To leverage these insights, we propose Layer-wise Sink Gating (LSG), a lightweight, plug-and-play module that dynamically scales the attention contributions of V-sink and the rest visual tokens. LSG is trained via standard next-token prediction, requiring no task-specific supervision while keeping the LVLM backbone frozen. In most layers, LSG yields improvements on representative multimodal benchmarks, effectively balancing global reasoning and precise local evidence.
One-step Language Modeling via Continuous Denoising
Feb 18, 2026Language models based on discrete diffusion have attracted widespread interest for their potential to provide faster generation than autoregressive models. In practice, however, they exhibit a sharp degradation of sample quality in the few-step regime, failing to realize this promise. Here we show that language models leveraging flow-based continuous denoising can outperform discrete diffusion in both quality and speed. By revisiting the fundamentals of flows over discrete modalities, we build a flow-based language model (FLM) that performs Euclidean denoising over one-hot token encodings. We show that the model can be trained by predicting the clean data via a cross entropy objective, where we introduce a simple time reparameterization that greatly improves training stability and generation quality. By distilling FLM into its associated flow map, we obtain a distilled flow map language model (FMLM) capable of few-step generation. On the LM1B and OWT language datasets, FLM attains generation quality matching state-of-the-art discrete diffusion models. With FMLM, our approach outperforms recent few-step language models across the board, with one-step generation exceeding their 8-step quality. Our work calls into question the widely held hypothesis that discrete diffusion processes are necessary for generative modeling over discrete modalities, and paves the way toward accelerated flow-based language modeling at scale. Code is available at https://github.com/david3684/flm.
Inverting Data Transformations via Diffusion Sampling
Feb 09, 2026We study the problem of transformation inversion on general Lie groups: a datum is transformed by an unknown group element, and the goal is to recover an inverse transformation that maps it back to the original data distribution. Such unknown transformations arise widely in machine learning and scientific modeling, where they can significantly distort observations. We take a probabilistic view and model the posterior over transformations as a Boltzmann distribution defined by an energy function on data space. To sample from this posterior, we introduce a diffusion process on Lie groups that keeps all updates on-manifold and only requires computations in the associated Lie algebra. Our method, Transformation-Inverting Energy Diffusion (TIED), relies on a new trivialized target-score identity that enables efficient score-based sampling of the transformation posterior. As a key application, we focus on test-time equivariance, where the objective is to improve the robustness of pretrained neural networks to input transformations. Experiments on image homographies and PDE symmetries demonstrate that TIED can restore transformed inputs to the training distribution at test time, showing improved performance over strong canonicalization and sampling baselines. Code is available at https://github.com/jw9730/tied.
FlowBind: Efficient Any-to-Any Generation with Bidirectional Flows
Dec 17, 2025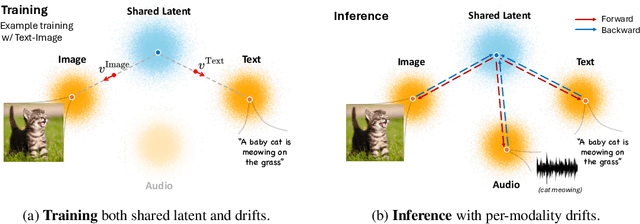

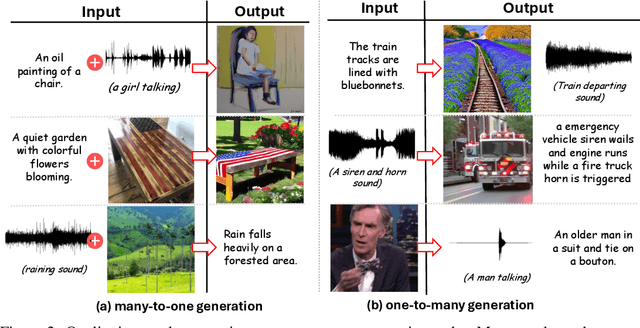
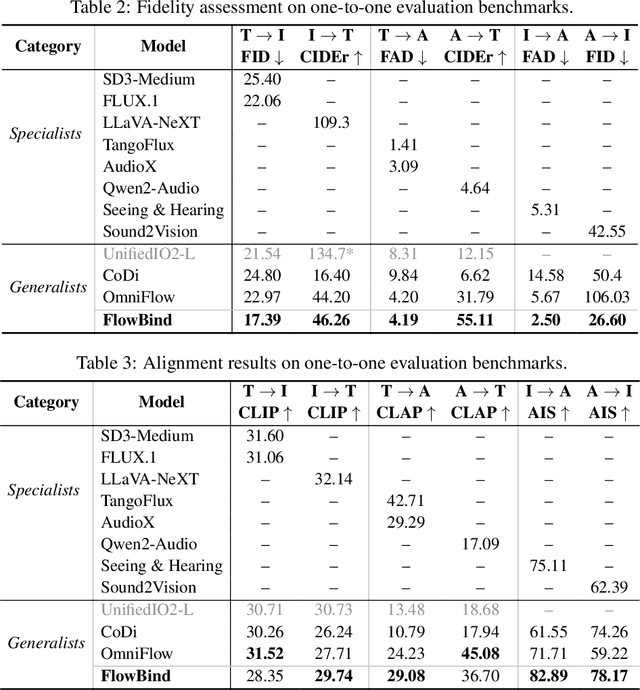
Any-to-any generation seeks to translate between arbitrary subsets of modalities, enabling flexible cross-modal synthesis. Despite recent success, existing flow-based approaches are challenged by their inefficiency, as they require large-scale datasets often with restrictive pairing constraints, incur high computational cost from modeling joint distribution, and rely on complex multi-stage training. We propose FlowBind, an efficient framework for any-to-any generation. Our approach is distinguished by its simplicity: it learns a shared latent space capturing cross-modal information, with modality-specific invertible flows bridging this latent to each modality. Both components are optimized jointly under a single flow-matching objective, and at inference the invertible flows act as encoders and decoders for direct translation across modalities. By factorizing interactions through the shared latent, FlowBind naturally leverages arbitrary subsets of modalities for training, and achieves competitive generation quality while substantially reducing data requirements and computational cost. Experiments on text, image, and audio demonstrate that FlowBind attains comparable quality while requiring up to 6x fewer parameters and training 10x faster than prior methods. The project page with code is available at https://yeonwoo378.github.io/official_flowbind.
Flock: A Knowledge Graph Foundation Model via Learning on Random Walks
Oct 01, 2025We study the problem of zero-shot link prediction on knowledge graphs (KGs), which requires models to generalize over novel entities and novel relations. Knowledge graph foundation models (KGFMs) address this task by enforcing equivariance over both nodes and relations, learning from structural properties of nodes and relations, which are then transferable to novel graphs with similar structural properties. However, the conventional notion of deterministic equivariance imposes inherent limits on the expressive power of KGFMs, preventing them from distinguishing structurally similar but semantically distinct relations. To overcome this limitation, we introduce probabilistic node-relation equivariance, which preserves equivariance in distribution while incorporating a principled randomization to break symmetries during inference. Building on this principle, we present Flock, a KGFM that iteratively samples random walks, encodes them into sequences via a recording protocol, embeds them with a sequence model, and aggregates representations of nodes and relations via learned pooling. Crucially, Flock respects probabilistic node-relation equivariance and is a universal approximator for isomorphism-invariant link-level functions over KGs. Empirically, Flock perfectly solves our new diagnostic dataset Petals where current KGFMs fail, and achieves state-of-the-art performances on entity- and relation prediction tasks on 54 KGs from diverse domains.
Universal Few-Shot Spatial Control for Diffusion Models
Sep 09, 2025



Spatial conditioning in pretrained text-to-image diffusion models has significantly improved fine-grained control over the structure of generated images. However, existing control adapters exhibit limited adaptability and incur high training costs when encountering novel spatial control conditions that differ substantially from the training tasks. To address this limitation, we propose Universal Few-Shot Control (UFC), a versatile few-shot control adapter capable of generalizing to novel spatial conditions. Given a few image-condition pairs of an unseen task and a query condition, UFC leverages the analogy between query and support conditions to construct task-specific control features, instantiated by a matching mechanism and an update on a small set of task-specific parameters. Experiments on six novel spatial control tasks show that UFC, fine-tuned with only 30 annotated examples of novel tasks, achieves fine-grained control consistent with the spatial conditions. Notably, when fine-tuned with 0.1% of the full training data, UFC achieves competitive performance with the fully supervised baselines in various control tasks. We also show that UFC is applicable agnostically to various diffusion backbones and demonstrate its effectiveness on both UNet and DiT architectures. Code is available at https://github.com/kietngt00/UFC.
HyperFlow: Gradient-Free Emulation of Few-Shot Fine-Tuning
Apr 21, 2025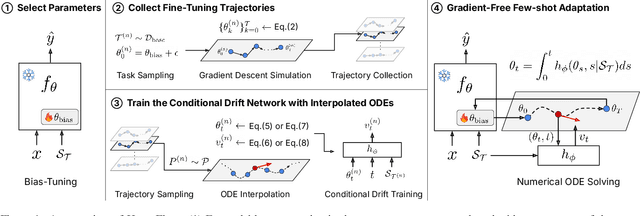



While test-time fine-tuning is beneficial in few-shot learning, the need for multiple backpropagation steps can be prohibitively expensive in real-time or low-resource scenarios. To address this limitation, we propose an approach that emulates gradient descent without computing gradients, enabling efficient test-time adaptation. Specifically, we formulate gradient descent as an Euler discretization of an ordinary differential equation (ODE) and train an auxiliary network to predict the task-conditional drift using only the few-shot support set. The adaptation then reduces to a simple numerical integration (e.g., via the Euler method), which requires only a few forward passes of the auxiliary network -- no gradients or forward passes of the target model are needed. In experiments on cross-domain few-shot classification using the Meta-Dataset and CDFSL benchmarks, our method significantly improves out-of-domain performance over the non-fine-tuned baseline while incurring only 6\% of the memory cost and 0.02\% of the computation time of standard fine-tuning, thus establishing a practical middle ground between direct transfer and fully fine-tuned approaches.
AdaRank: Adaptive Rank Pruning for Enhanced Model Merging
Mar 28, 2025



Model merging has emerged as a promising approach for unifying independently fine-tuned models into an integrated framework, significantly enhancing computational efficiency in multi-task learning. Recently, several SVD-based techniques have been introduced to exploit low-rank structures for enhanced merging, but their reliance on such manually designed rank selection often leads to cross-task interference and suboptimal performance. In this paper, we propose AdaRank, a novel model merging framework that adaptively selects the most beneficial singular directions of task vectors to merge multiple models. We empirically show that the dominant singular components of task vectors can cause critical interference with other tasks, and that naive truncation across tasks and layers degrades performance. In contrast, AdaRank dynamically prunes the singular components that cause interference and offers an optimal amount of information to each task vector by learning to prune ranks during test-time via entropy minimization. Our analysis demonstrates that such method mitigates detrimental overlaps among tasks, while empirical results show that AdaRank consistently achieves state-of-the-art performance with various backbones and number of tasks, reducing the performance gap between fine-tuned models to nearly 1%.