 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePVMark: Enabling Public Verifiability for LLM Watermarking Schemes
Oct 30, 2025Watermarking schemes for large language models (LLMs) have been proposed to identify the source of the generated text, mitigating the potential threats emerged from model theft. However, current watermarking solutions hardly resolve the trust issue: the non-public watermark detection cannot prove itself faithfully conducting the detection. We observe that it is attributed to the secret key mostly used in the watermark detection -- it cannot be public, or the adversary may launch removal attacks provided the key; nor can it be private, or the watermarking detection is opaque to the public. To resolve the dilemma, we propose PVMark, a plugin based on zero-knowledge proof (ZKP), enabling the watermark detection process to be publicly verifiable by third parties without disclosing any secret key. PVMark hinges upon the proof of `correct execution' of watermark detection on which a set of ZKP constraints are built, including mapping, random number generation, comparison, and summation. We implement multiple variants of PVMark in Python, Rust and Circom, covering combinations of three watermarking schemes, three hash functions, and four ZKP protocols, to show our approach effectively works under a variety of circumstances. By experimental results, PVMark efficiently enables public verifiability on the state-of-the-art LLM watermarking schemes yet without compromising the watermarking performance, promising to be deployed in practice.
CityRiSE: Reasoning Urban Socio-Economic Status in Vision-Language Models via Reinforcement Learning
Oct 25, 2025Harnessing publicly available, large-scale web data, such as street view and satellite imagery, urban socio-economic sensing is of paramount importance for achieving global sustainable development goals. With the emergence of Large Vision-Language Models (LVLMs), new opportunities have arisen to solve this task by treating it as a multi-modal perception and understanding problem. However, recent studies reveal that LVLMs still struggle with accurate and interpretable socio-economic predictions from visual data. To address these limitations and maximize the potential of LVLMs, we introduce \textbf{CityRiSE}, a novel framework for \textbf{R}eason\textbf{i}ng urban \textbf{S}ocio-\textbf{E}conomic status in LVLMs through pure reinforcement learning (RL). With carefully curated multi-modal data and verifiable reward design, our approach guides the LVLM to focus on semantically meaningful visual cues, enabling structured and goal-oriented reasoning for generalist socio-economic status prediction. Experiments demonstrate that CityRiSE with emergent reasoning process significantly outperforms existing baselines, improving both prediction accuracy and generalization across diverse urban contexts, particularly for prediction on unseen cities and unseen indicators. This work highlights the promise of combining RL and LVLMs for interpretable and generalist urban socio-economic sensing.
CCrepairBench: A High-Fidelity Benchmark and Reinforcement Learning Framework for C++ Compilation Repair
Sep 19, 2025



The automated repair of C++ compilation errors presents a significant challenge, the resolution of which is critical for developer productivity. Progress in this domain is constrained by two primary factors: the scarcity of large-scale, high-fidelity datasets and the limitations of conventional supervised methods, which often fail to generate semantically correct patches.This paper addresses these gaps by introducing a comprehensive framework with three core contributions. First, we present CCrepair, a novel, large-scale C++ compilation error dataset constructed through a sophisticated generate-and-verify pipeline. Second, we propose a Reinforcement Learning (RL) paradigm guided by a hybrid reward signal, shifting the focus from mere compilability to the semantic quality of the fix. Finally, we establish the robust, two-stage evaluation system providing this signal, centered on an LLM-as-a-Judge whose reliability has been rigorously validated against the collective judgments of a panel of human experts. This integrated approach aligns the training objective with generating high-quality, non-trivial patches that are both syntactically and semantically correct. The effectiveness of our approach was demonstrated experimentally. Our RL-trained Qwen2.5-1.5B-Instruct model achieved performance comparable to a Qwen2.5-14B-Instruct model, validating the efficiency of our training paradigm. Our work provides the research community with a valuable new dataset and a more effective paradigm for training and evaluating robust compilation repair models, paving the way for more practical and reliable automated programming assistants.
RPG: A Repository Planning Graph for Unified and Scalable Codebase Generation
Sep 19, 2025



Large language models excel at function- and file-level code generation, yet generating complete repositories from scratch remains a fundamental challenge. This process demands coherent and reliable planning across proposal- and implementation-level stages, while natural language, due to its ambiguity and verbosity, is ill-suited for faithfully representing complex software structures. To address this, we introduce the Repository Planning Graph (RPG), a persistent representation that unifies proposal- and implementation-level planning by encoding capabilities, file structures, data flows, and functions in one graph. RPG replaces ambiguous natural language with an explicit blueprint, enabling long-horizon planning and scalable repository generation. Building on RPG, we develop ZeroRepo, a graph-driven framework for repository generation from scratch. It operates in three stages: proposal-level planning and implementation-level refinement to construct the graph, followed by graph-guided code generation with test validation. To evaluate this setting, we construct RepoCraft, a benchmark of six real-world projects with 1,052 tasks. On RepoCraft, ZeroRepo produces repositories averaging nearly 36K LOC, roughly 3.9$\times$ the strongest baseline (Claude Code) and about 64$\times$ other baselines. It attains 81.5% functional coverage and a 69.7% pass rate, exceeding Claude Code by 27.3 and 35.8 percentage points, respectively. Further analysis shows that RPG models complex dependencies, enables progressively more sophisticated planning through near-linear scaling, and enhances LLM understanding of repositories, thereby accelerating agent localization.
Human Motion Video Generation: A Survey
Sep 04, 2025Human motion video generation has garnered significant research interest due to its broad applications, enabling innovations such as photorealistic singing heads or dynamic avatars that seamlessly dance to music. However, existing surveys in this field focus on individual methods, lacking a comprehensive overview of the entire generative process. This paper addresses this gap by providing an in-depth survey of human motion video generation, encompassing over ten sub-tasks, and detailing the five key phases of the generation process: input, motion planning, motion video generation, refinement, and output. Notably, this is the first survey that discusses the potential of large language models in enhancing human motion video generation. Our survey reviews the latest developments and technological trends in human motion video generation across three primary modalities: vision, text, and audio. By covering over two hundred papers, we offer a thorough overview of the field and highlight milestone works that have driven significant technological breakthroughs. Our goal for this survey is to unveil the prospects of human motion video generation and serve as a valuable resource for advancing the comprehensive applications of digital humans. A complete list of the models examined in this survey is available in Our Repository https://github.com/Winn1y/Awesome-Human-Motion-Video-Generation.
* Accepted by TPAMI. Github Repo: https://github.com/Winn1y/Awesome-Human-Motion-Video-Generation IEEE Access: https://ieeexplore.ieee.org/document/11106267
ERF-BA-TFD+: A Multimodal Model for Audio-Visual Deepfake Detection
Aug 24, 2025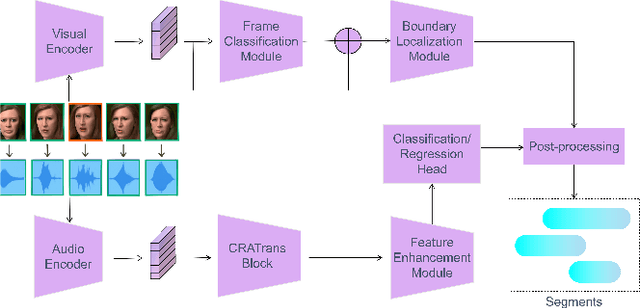
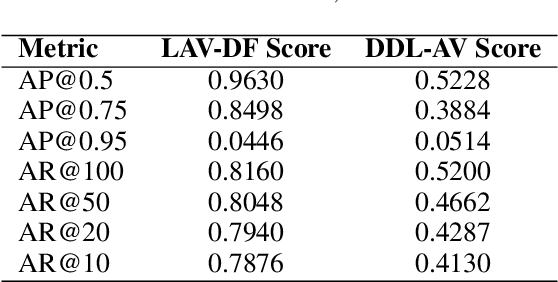
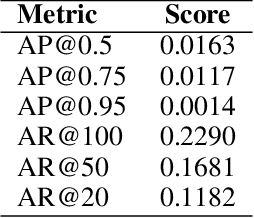
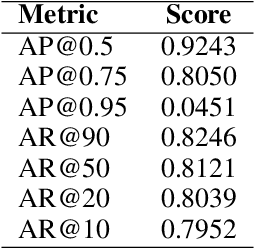
Deepfake detection is a critical task in identifying manipulated multimedia content. In real-world scenarios, deepfake content can manifest across multiple modalities, including audio and video. To address this challenge, we present ERF-BA-TFD+, a novel multimodal deepfake detection model that combines enhanced receptive field (ERF) and audio-visual fusion. Our model processes both audio and video features simultaneously, leveraging their complementary information to improve detection accuracy and robustness. The key innovation of ERF-BA-TFD+ lies in its ability to model long-range dependencies within the audio-visual input, allowing it to better capture subtle discrepancies between real and fake content. In our experiments, we evaluate ERF-BA-TFD+ on the DDL-AV dataset, which consists of both segmented and full-length video clips. Unlike previous benchmarks, which focused primarily on isolated segments, the DDL-AV dataset allows us to assess the model's performance in a more comprehensive and realistic setting. Our method achieves state-of-the-art results on this dataset, outperforming existing techniques in terms of both accuracy and processing speed. The ERF-BA-TFD+ model demonstrated its effectiveness in the "Workshop on Deepfake Detection, Localization, and Interpretability," Track 2: Audio-Visual Detection and Localization (DDL-AV), and won first place in this competition.
Condition Weaving Meets Expert Modulation: Towards Universal and Controllable Image Generation
Aug 24, 2025The image-to-image generation task aims to produce controllable images by leveraging conditional inputs and prompt instructions. However, existing methods often train separate control branches for each type of condition, leading to redundant model structures and inefficient use of computational resources. To address this, we propose a Unified image-to-image Generation (UniGen) framework that supports diverse conditional inputs while enhancing generation efficiency and expressiveness. Specifically, to tackle the widely existing parameter redundancy and computational inefficiency in controllable conditional generation architectures, we propose the Condition Modulated Expert (CoMoE) module. This module aggregates semantically similar patch features and assigns them to dedicated expert modules for visual representation and conditional modeling. By enabling independent modeling of foreground features under different conditions, CoMoE effectively mitigates feature entanglement and redundant computation in multi-condition scenarios. Furthermore, to bridge the information gap between the backbone and control branches, we propose WeaveNet, a dynamic, snake-like connection mechanism that enables effective interaction between global text-level control from the backbone and fine-grained control from conditional branches. Extensive experiments on the Subjects-200K and MultiGen-20M datasets across various conditional image generation tasks demonstrate that our method consistently achieves state-of-the-art performance, validating its advantages in both versatility and effectiveness. The code has been uploaded to https://github.com/gavin-gqzhang/UniGen.
Deep Learning for Taxol Exposure Analysis: A New Cell Image Dataset and Attention-Based Baseline Model
Aug 20, 2025Monitoring the effects of the chemotherapeutic agent Taxol at the cellular level is critical for both clinical evaluation and biomedical research. However, existing detection methods require specialized equipment, skilled personnel, and extensive sample preparation, making them expensive, labor-intensive, and unsuitable for high-throughput or real-time analysis. Deep learning approaches have shown great promise in medical and biological image analysis, enabling automated, high-throughput assessment of cellular morphology. Yet, no publicly available dataset currently exists for automated morphological analysis of cellular responses to Taxol exposure. To address this gap, we introduce a new microscopy image dataset capturing C6 glioma cells treated with varying concentrations of Taxol. To provide an effective solution for Taxol concentration classification and establish a benchmark for future studies on this dataset, we propose a baseline model named ResAttention-KNN, which combines a ResNet-50 with Convolutional Block Attention Modules and uses a k-Nearest Neighbors classifier in the learned embedding space. This model integrates attention-based refinement and non-parametric classification to enhance robustness and interpretability. Both the dataset and implementation are publicly released to support reproducibility and facilitate future research in vision-based biomedical analysis.
Two-dimensional Sparse Parallelism for Large Scale Deep Learning Recommendation Model Training
Aug 05, 2025The increasing complexity of deep learning recommendation models (DLRM) has led to a growing need for large-scale distributed systems that can efficiently train vast amounts of data. In DLRM, the sparse embedding table is a crucial component for managing sparse categorical features. Typically, these tables in industrial DLRMs contain trillions of parameters, necessitating model parallelism strategies to address memory constraints. However, as training systems expand with massive GPUs, the traditional fully parallelism strategies for embedding table post significant scalability challenges, including imbalance and straggler issues, intensive lookup communication, and heavy embedding activation memory. To overcome these limitations, we propose a novel two-dimensional sparse parallelism approach. Rather than fully sharding tables across all GPUs, our solution introduces data parallelism on top of model parallelism. This enables efficient all-to-all communication and reduces peak memory consumption. Additionally, we have developed the momentum-scaled row-wise AdaGrad algorithm to mitigate performance losses associated with the shift in training paradigms. Our extensive experiments demonstrate that the proposed approach significantly enhances training efficiency while maintaining model performance parity. It achieves nearly linear training speed scaling up to 4K GPUs, setting a new state-of-the-art benchmark for recommendation model training.
On The Role of Pretrained Language Models in General-Purpose Text Embeddings: A Survey
Jul 28, 2025Text embeddings have attracted growing interest due to their effectiveness across a wide range of natural language processing (NLP) tasks, such as retrieval, classification, clustering, bitext mining, and summarization. With the emergence of pretrained language models (PLMs), general-purpose text embeddings (GPTE) have gained significant traction for their ability to produce rich, transferable representations. The general architecture of GPTE typically leverages PLMs to derive dense text representations, which are then optimized through contrastive learning on large-scale pairwise datasets. In this survey, we provide a comprehensive overview of GPTE in the era of PLMs, focusing on the roles PLMs play in driving its development. We first examine the fundamental architecture and describe the basic roles of PLMs in GPTE, i.e., embedding extraction, expressivity enhancement, training strategies, learning objectives, and data construction. Then, we describe advanced roles enabled by PLMs, such as multilingual support, multimodal integration, code understanding, and scenario-specific adaptation. Finally, we highlight potential future research directions that move beyond traditional improvement goals, including ranking integration, safety considerations, bias mitigation, structural information incorporation, and the cognitive extension of embeddings. This survey aims to serve as a valuable reference for both newcomers and established researchers seeking to understand the current state and future potential of GPTE.