 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERF-BA-TFD+: A Multimodal Model for Audio-Visual Deepfake Detection
Aug 24, 2025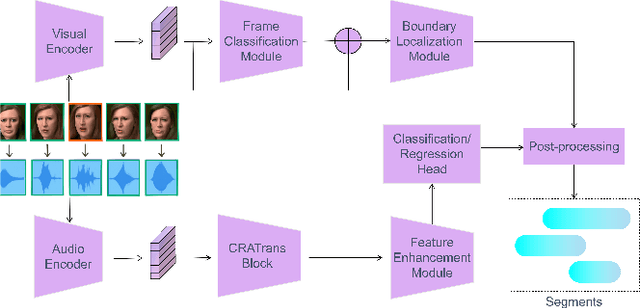
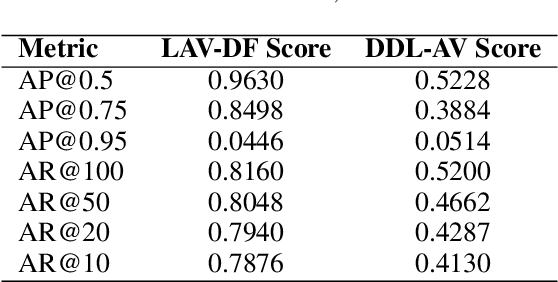
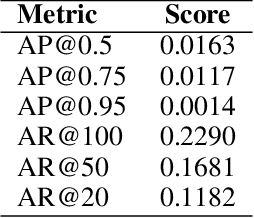
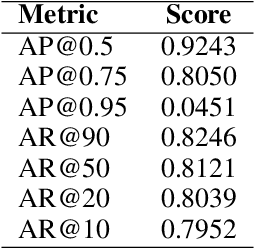
Deepfake detection is a critical task in identifying manipulated multimedia content. In real-world scenarios, deepfake content can manifest across multiple modalities, including audio and video. To address this challenge, we present ERF-BA-TFD+, a novel multimodal deepfake detection model that combines enhanced receptive field (ERF) and audio-visual fusion. Our model processes both audio and video features simultaneously, leveraging their complementary information to improve detection accuracy and robustness. The key innovation of ERF-BA-TFD+ lies in its ability to model long-range dependencies within the audio-visual input, allowing it to better capture subtle discrepancies between real and fake content. In our experiments, we evaluate ERF-BA-TFD+ on the DDL-AV dataset, which consists of both segmented and full-length video clips. Unlike previous benchmarks, which focused primarily on isolated segments, the DDL-AV dataset allows us to assess the model's performance in a more comprehensive and realistic setting. Our method achieves state-of-the-art results on this dataset, outperforming existing techniques in terms of both accuracy and processing speed. The ERF-BA-TFD+ model demonstrated its effectiveness in the "Workshop on Deepfake Detection, Localization, and Interpretability," Track 2: Audio-Visual Detection and Localization (DDL-AV), and won first place in this competition.
Safe Semantics, Unsafe Interpretations: Tackling Implicit Reasoning Safety in Large Vision-Language Models
Aug 12, 2025Large Vision-Language Models face growing safety challenges with multimodal inputs. This paper introduces the concept of Implicit Reasoning Safety, a vulnerability in LVLMs. Benign combined inputs trigger unsafe LVLM outputs due to flawed or hidden reasoning. To showcase this, we developed Safe Semantics, Unsafe Interpretations, the first dataset for this critical issue. Our demonstrations show that even simple In-Context Learning with SSUI significantly mitigates these implicit multimodal threats, underscoring the urgent need to improve cross-modal implicit reasoning.
Mimic In-Context Learning for Multimodal Tasks
Apr 11, 2025Recently, In-context Learning (ICL) has become a significant inference paradigm in Large Multimodal Models (LMMs), utilizing a few in-context demonstrations (ICDs) to prompt LMMs for new tasks. However, the synergistic effects in multimodal data increase the sensitivity of ICL performance to the configurations of ICDs, stimulating the need for a more stable and general mapping function. Mathematically, in Transformer-based models, ICDs act as ``shift vectors'' added to the hidden states of query tokens. Inspired by this, we introduce Mimic In-Context Learning (MimIC) to learn stable and generalizable shift effects from ICDs. Specifically, compared with some previous shift vector-based methods, MimIC more strictly approximates the shift effects by integrating lightweight learnable modules into LMMs with four key enhancements: 1) inserting shift vectors after attention layers, 2) assigning a shift vector to each attention head, 3) making shift magnitude query-dependent, and 4) employing a layer-wise alignment loss. Extensive experiments on two LMMs (Idefics-9b and Idefics2-8b-base) across three multimodal tasks (VQAv2, OK-VQA, Captioning) demonstrate that MimIC outperforms existing shift vector-based methods. The code is available at https://github.com/Kamichanw/MimIC.