 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaLM-Reranker-V1: Fast but Not Late Interaction for Compressed Document Reranking
Jun 22, 2026As retrieval systems scale, high-quality reranking becomes increasingly important. However, most existing rerankers, whether encoder-based or decoder-based, jointly encode the query and passage, tightly coupling their computation and limiting deployment efficiency as well as flexibility. We present KaLM-Reranker-V1, a fast but not late-interaction (FBNL) reranker that decouples query and passage computation while retaining expressive relevance modeling. Built on an encoder-decoder architecture, KaLM-Reranker-V1 uses the encoder to pre-encode passages with Matryoshka embedding pooling, while the decoder models the system instruction, user instruction, and query intent; cross-attention then captures relevance between the query context and passage representations. This design makes KaLM-Reranker-V1 efficient through decoupled passage encoding, yet not late interaction, by preserving rich relevance modeling through cross-attention. We instantiate KaLM-Reranker-V1 in three sizes, Nano, Small, and Large, with 0.27B, 1B, and 4B activated parameters, respectively. Extensive experiments on BEIR, MIRACL, and LMEB demonstrate that KaLM-Reranker-V1 achieves strong reranking performance with superior efficiency. On BEIR, KaLM-Reranker-V1 achieves state-of-the-art performance, on par with strong industrial models such as the Qwen3-Reranker series; on MIRACL, despite not being extensively trained on multilingual data, KaLM-Reranker-V1 still shows excellent reranking performance. Moreover, on LMEB, reranking models demonstrate a clear advantage, with even the 0.27B Nano model remaining competitive with 7-12B embedding models.
ToolOmni: Enabling Open-World Tool Use via Agentic learning with Proactive Retrieval and Grounded Execution
Apr 15, 2026Large Language Models (LLMs) enhance their problem-solving capability by utilizing external tools. However, in open-world scenarios with massive and evolving tool repositories, existing methods relying on static embedding retrieval or parameter memorization of tools struggle to align user intent with tool semantics or generalize to unseen tools, respectively, leading to suboptimal accuracy of open-world tool retrieval and execution. To address these, we present ToolOmni, a unified agentic framework that enables LLMs for open-world tool use by proactive retrieval and grounded execution within a reasoning loop. First, we construct a cold-start multi-turn interaction dataset to instill foundational agentic capabilities via Supervised Fine-Tuning (SFT). Then, we introduce open-world tool learning based on a Decoupled Multi-Objective GRPO algorithm, which simultaneously optimizes LLMs for both tool retrieval accuracy and execution efficacy in online environments. Extensive experiments demonstrate that ToolOmni achieves state-of-the-art performance both in retrieval and execution, surpassing strong baselines by a significant margin of +10.8% in end-to-end execution success rate, while exhibiting exceptional robustness and generalization capabilities.
On The Role of Pretrained Language Models in General-Purpose Text Embeddings: A Survey
Jul 28, 2025Text embeddings have attracted growing interest due to their effectiveness across a wide range of natural language processing (NLP) tasks, such as retrieval, classification, clustering, bitext mining, and summarization. With the emergence of pretrained language models (PLMs), general-purpose text embeddings (GPTE) have gained significant traction for their ability to produce rich, transferable representations. The general architecture of GPTE typically leverages PLMs to derive dense text representations, which are then optimized through contrastive learning on large-scale pairwise datasets. In this survey, we provide a comprehensive overview of GPTE in the era of PLMs, focusing on the roles PLMs play in driving its development. We first examine the fundamental architecture and describe the basic roles of PLMs in GPTE, i.e., embedding extraction, expressivity enhancement, training strategies, learning objectives, and data construction. Then, we describe advanced roles enabled by PLMs, such as multilingual support, multimodal integration, code understanding, and scenario-specific adaptation. Finally, we highlight potential future research directions that move beyond traditional improvement goals, including ranking integration, safety considerations, bias mitigation, structural information incorporation, and the cognitive extension of embeddings. This survey aims to serve as a valuable reference for both newcomers and established researchers seeking to understand the current state and future potential of GPTE.
KaLM-Embedding-V2: Superior Training Techniques and Data Inspire A Versatile Embedding Model
Jun 26, 2025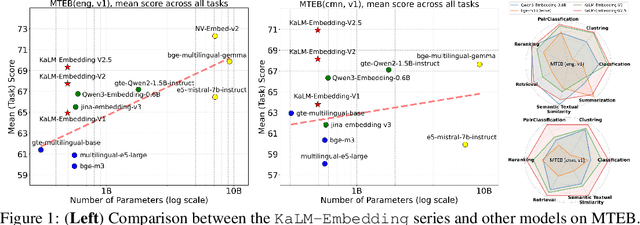
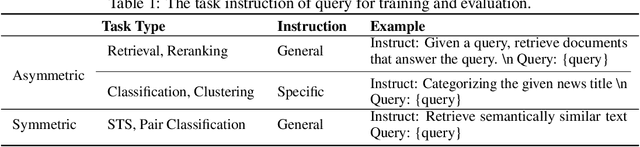

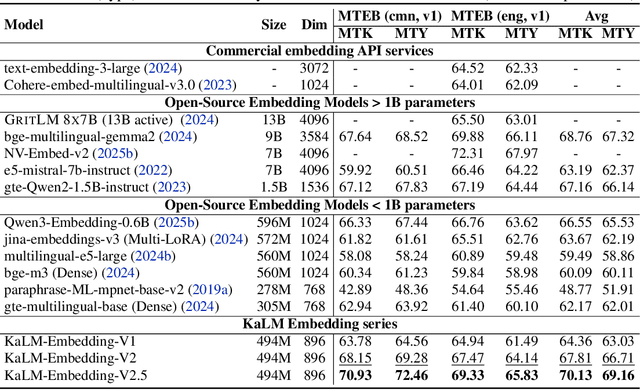
In this paper, we propose KaLM-Embedding-V2, a versatile and compact embedding model, which achieves impressive performance in general-purpose text embedding tasks by leveraging superior training techniques and data. Our key innovations include: (1) To better align the architecture with representation learning, we remove the causal attention mask and adopt a fully bidirectional transformer with simple yet effective mean-pooling to produce fixed-length embeddings; (2) We employ a multi-stage training pipeline: (i) pre-training on large-scale weakly supervised open-source corpora; (ii) fine-tuning on high-quality retrieval and non-retrieval datasets; and (iii) model-soup parameter averaging for robust generalization. Besides, we introduce a focal-style reweighting mechanism that concentrates learning on difficult samples and an online hard-negative mixing strategy to continuously enrich hard negatives without expensive offline mining; (3) We collect over 20 categories of data for pre-training and 100 categories of data for fine-tuning, to boost both the performance and generalization of the embedding model. Extensive evaluations on the Massive Text Embedding Benchmark (MTEB) Chinese and English show that our model significantly outperforms others of comparable size, and competes with 3x, 14x, 18x, and 26x larger embedding models, setting a new standard for a versatile and compact embedding model with less than 1B parameters.
Perception, Reason, Think, and Plan: A Survey on Large Multimodal Reasoning Models
May 08, 2025



Reasoning lies at the heart of intelligence, shaping the ability to make decisions, draw conclusions, and generalize across domains. In artificial intelligence, as systems increasingly operate in open, uncertain, and multimodal environments, reasoning becomes essential for enabling robust and adaptive behavior. Large Multimodal Reasoning Models (LMRMs) have emerged as a promising paradigm, integrating modalities such as text, images, audio, and video to support complex reasoning capabilities and aiming to achieve comprehensive perception, precise understanding, and deep reasoning. As research advances, multimodal reasoning has rapidly evolved from modular, perception-driven pipelines to unified, language-centric frameworks that offer more coherent cross-modal understanding. While instruction tuning and reinforcement learning have improved model reasoning, significant challenges remain in omni-modal generalization, reasoning depth, and agentic behavior. To address these issues, we present a comprehensive and structured survey of multimodal reasoning research, organized around a four-stage developmental roadmap that reflects the field's shifting design philosophies and emerging capabilities. First, we review early efforts based on task-specific modules, where reasoning was implicitly embedded across stages of representation, alignment, and fusion. Next, we examine recent approaches that unify reasoning into multimodal LLMs, with advances such as Multimodal Chain-of-Thought (MCoT) and multimodal reinforcement learning enabling richer and more structured reasoning chains. Finally, drawing on empirical insights from challenging benchmarks and experimental cases of OpenAI O3 and O4-mini, we discuss the conceptual direction of native large multimodal reasoning models (N-LMRMs), which aim to support scalable, agentic, and adaptive reasoning and planning in complex, real-world environments.
RaSeRec: Retrieval-Augmented Sequential Recommendation
Dec 24, 2024



Although prevailing supervised and self-supervised learning (SSL)-augmented sequential recommendation (SeRec) models have achieved improved performance with powerful neural network architectures, we argue that they still suffer from two limitations: (1) Preference Drift, where models trained on past data can hardly accommodate evolving user preference; and (2) Implicit Memory, where head patterns dominate parametric learning, making it harder to recall long tails. In this work, we explore retrieval augmentation in SeRec, to address these limitations. To this end, we propose a Retrieval-Augmented Sequential Recommendation framework, named RaSeRec, the main idea of which is to maintain a dynamic memory bank to accommodate preference drifts and retrieve relevant memories to augment user modeling explicitly. It consists of two stages: (i) collaborative-based pre-training, which learns to recommend and retrieve; (ii) retrieval-augmented fine-tuning, which learns to leverage retrieved memories. Extensive experiments on three datasets fully demonstrate the superiority and effectiveness of RaSeRec.