 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePvP: Data-Efficient Humanoid Robot Learning with Proprioceptive-Privileged Contrastive Representations
Dec 15, 2025Achieving efficient and robust whole-body control (WBC) is essential for enabling humanoid robots to perform complex tasks in dynamic environments. Despite the success of reinforcement learning (RL) in this domain, its sample inefficiency remains a significant challenge due to the intricate dynamics and partial observability of humanoid robots. To address this limitation, we propose PvP, a Proprioceptive-Privileged contrastive learning framework that leverages the intrinsic complementarity between proprioceptive and privileged states. PvP learns compact and task-relevant latent representations without requiring hand-crafted data augmentations, enabling faster and more stable policy learning. To support systematic evaluation, we develop SRL4Humanoid, the first unified and modular framework that provides high-quality implementations of representative state representation learning (SRL) methods for humanoid robot learning. Extensive experiments on the LimX Oli robot across velocity tracking and motion imitation tasks demonstrate that PvP significantly improves sample efficiency and final performance compared to baseline SRL methods. Our study further provides practical insights into integrating SRL with RL for humanoid WBC, offering valuable guidance for data-efficient humanoid robot learning.
WarmServe: Enabling One-for-Many GPU Prewarming for Multi-LLM Serving
Dec 10, 2025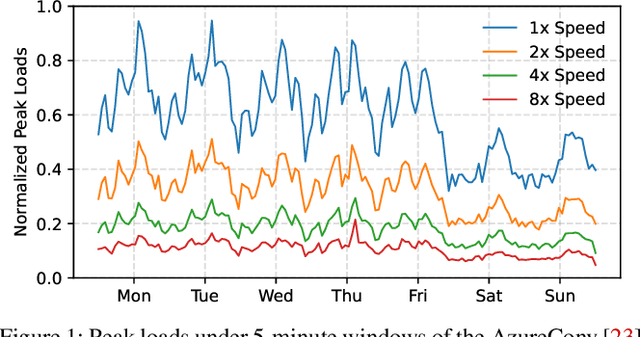
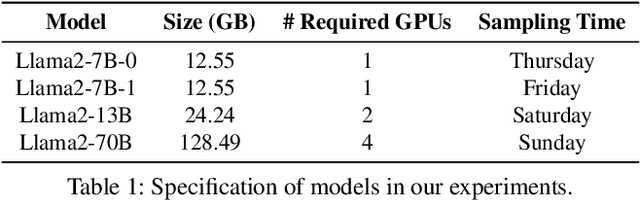
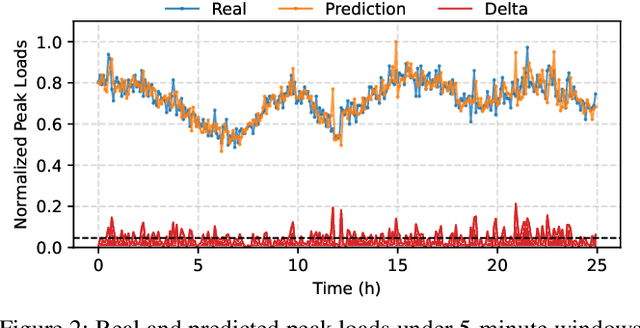
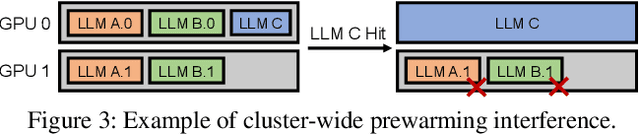
Deploying multiple models within shared GPU clusters is promising for improving resource efficiency in large language model (LLM) serving. Existing multi-LLM serving systems optimize GPU utilization at the cost of worse inference performance, especially time-to-first-token (TTFT). We identify the root cause of such compromise as their unawareness of future workload characteristics. In contrast, recent analysis on real-world traces has shown the high periodicity and long-term predictability of LLM serving workloads. We propose universal GPU workers to enable one-for-many GPU prewarming that loads models with knowledge of future workloads. Based on universal GPU workers, we design and build WarmServe, a multi-LLM serving system that (1) mitigates cluster-wide prewarming interference by adopting an evict-aware model placement strategy, (2) prepares universal GPU workers in advance by proactive prewarming, and (3) manages GPU memory with a zero-overhead memory switching mechanism. Evaluation under real-world datasets shows that WarmServe improves TTFT by up to 50.8$\times$ compared to the state-of-the-art autoscaling-based system, while being capable of serving up to 2.5$\times$ more requests compared to the GPU-sharing system.
Distribution Matching Distillation Meets Reinforcement Learning
Nov 19, 2025Distribution Matching Distillation (DMD) distills a pre-trained multi-step diffusion model to a few-step one to improve inference efficiency. However, the performance of the latter is often capped by the former. To circumvent this dilemma, we propose DMDR, a novel framework that combines Reinforcement Learning (RL) techniques into the distillation process. We show that for the RL of the few-step generator, the DMD loss itself is a more effective regularization compared to the traditional ones. In turn, RL can help to guide the mode coverage process in DMD more effectively. These allow us to unlock the capacity of the few-step generator by conducting distillation and RL simultaneously. Meanwhile, we design the dynamic distribution guidance and dynamic renoise sampling training strategies to improve the initial distillation process. The experiments demonstrate that DMDR can achieve leading visual quality, prompt coherence among few-step methods, and even exhibit performance that exceeds the multi-step teacher.
From Low-Rank Features to Encoding Mismatch: Rethinking Feature Distillation in Vision Transformers
Nov 19, 2025Feature-map knowledge distillation (KD) is highly effective for convolutional networks but often fails for Vision Transformers (ViTs). To understand this failure and guide method design, we conduct a two-view representation analysis of ViTs. First, a layer-wise Singular Value Decomposition (SVD) of full feature matrices shows that final-layer representations are globally low-rank: for CaiT-S24, only $121/61/34/14$ dimensions suffice to capture $99\%/95\%/90\%/80\%$ of the energy. In principle, this suggests that a compact student plus a simple linear projector should be enough for feature alignment, contradicting the weak empirical performance of standard feature KD. To resolve this paradox, we introduce a token-level Spectral Energy Pattern (SEP) analysis that measures how each token uses channel capacity. SEP reveals that, despite the global low-rank structure, individual tokens distribute energy over most channels, forming a high-bandwidth encoding pattern. This results in an encoding mismatch between wide teachers and narrow students. Motivated by this insight, we propose two minimal, mismatch-driven strategies: (1) post-hoc feature lifting with a lightweight projector retained during inference, or (2) native width alignment that widens only the student's last block to the teacher's width. On ImageNet-1K, these strategies reactivate simple feature-map distillation in ViTs, raising DeiT-Tiny accuracy from $74.86\%$ to $77.53\%$ and $78.23\%$ when distilling from CaiT-S24, while also improving standalone students trained without any teacher. Our analysis thus explains why ViT feature distillation fails and shows how exploiting low-rank structure yields effective, interpretable remedies and concrete design guidance for compact ViTs.
AesTest: Measuring Aesthetic Intelligence from Perception to Production
Nov 09, 2025Perceiving and producing aesthetic judgments is a fundamental yet underexplored capability for multimodal large language models (MLLMs). However, existing benchmarks for image aesthetic assessment (IAA) are narrow in perception scope or lack the diversity needed to evaluate systematic aesthetic production. To address this gap, we introduce AesTest, a comprehensive benchmark for multimodal aesthetic perception and production, distinguished by the following features: 1) It consists of curated multiple-choice questions spanning ten tasks, covering perception, appreciation, creation, and photography. These tasks are grounded in psychological theories of generative learning. 2) It integrates data from diverse sources, including professional editing workflows, photographic composition tutorials, and crowdsourced preferences. It ensures coverage of both expert-level principles and real-world variation. 3) It supports various aesthetic query types, such as attribute-based analysis, emotional resonance, compositional choice, and stylistic reasoning. We evaluate both instruction-tuned IAA MLLMs and general MLLMs on AesTest, revealing significant challenges in building aesthetic intelligence. We will publicly release AesTest to support future research in this area.
Scaling Up Occupancy-centric Driving Scene Generation: Dataset and Method
Oct 27, 2025



Driving scene generation is a critical domain for autonomous driving, enabling downstream applications, including perception and planning evaluation. Occupancy-centric methods have recently achieved state-of-the-art results by offering consistent conditioning across frames and modalities; however, their performance heavily depends on annotated occupancy data, which still remains scarce. To overcome this limitation, we curate Nuplan-Occ, the largest semantic occupancy dataset to date, constructed from the widely used Nuplan benchmark. Its scale and diversity facilitate not only large-scale generative modeling but also autonomous driving downstream applications. Based on this dataset, we develop a unified framework that jointly synthesizes high-quality semantic occupancy, multi-view videos, and LiDAR point clouds. Our approach incorporates a spatio-temporal disentangled architecture to support high-fidelity spatial expansion and temporal forecasting of 4D dynamic occupancy. To bridge modal gaps, we further propose two novel techniques: a Gaussian splatting-based sparse point map rendering strategy that enhances multi-view video generation, and a sensor-aware embedding strategy that explicitly models LiDAR sensor properties for realistic multi-LiDAR simulation. Extensive experiments demonstrate that our method achieves superior generation fidelity and scalability compared to existing approaches, and validates its practical value in downstream tasks. Repo: https://github.com/Arlo0o/UniScene-Unified-Occupancy-centric-Driving-Scene-Generation/tree/v2
Vision-Centric Activation and Coordination for Multimodal Large Language Models
Oct 16, 2025Multimodal large language models (MLLMs) integrate image features from visual encoders with LLMs, demonstrating advanced comprehension capabilities. However, mainstream MLLMs are solely supervised by the next-token prediction of textual tokens, neglecting critical vision-centric information essential for analytical abilities. To track this dilemma, we introduce VaCo, which optimizes MLLM representations through Vision-Centric activation and Coordination from multiple vision foundation models (VFMs). VaCo introduces visual discriminative alignment to integrate task-aware perceptual features extracted from VFMs, thereby unifying the optimization of both textual and visual outputs in MLLMs. Specifically, we incorporate the learnable Modular Task Queries (MTQs) and Visual Alignment Layers (VALs) into MLLMs, activating specific visual signals under the supervision of diverse VFMs. To coordinate representation conflicts across VFMs, the crafted Token Gateway Mask (TGM) restricts the information flow among multiple groups of MTQs. Extensive experiments demonstrate that VaCo significantly improves the performance of different MLLMs on various benchmarks, showcasing its superior capabilities in visual comprehension.
UltraLED: Learning to See Everything in Ultra-High Dynamic Range Scenes
Oct 09, 2025



Ultra-high dynamic range (UHDR) scenes exhibit significant exposure disparities between bright and dark regions. Such conditions are commonly encountered in nighttime scenes with light sources. Even with standard exposure settings, a bimodal intensity distribution with boundary peaks often emerges, making it difficult to preserve both highlight and shadow details simultaneously. RGB-based bracketing methods can capture details at both ends using short-long exposure pairs, but are susceptible to misalignment and ghosting artifacts. We found that a short-exposure image already retains sufficient highlight detail. The main challenge of UHDR reconstruction lies in denoising and recovering information in dark regions. In comparison to the RGB images, RAW images, thanks to their higher bit depth and more predictable noise characteristics, offer greater potential for addressing this challenge. This raises a key question: can we learn to see everything in UHDR scenes using only a single short-exposure RAW image? In this study, we rely solely on a single short-exposure frame, which inherently avoids ghosting and motion blur, making it particularly robust in dynamic scenes. To achieve that, we introduce UltraLED, a two-stage framework that performs exposure correction via a ratio map to balance dynamic range, followed by a brightness-aware RAW denoiser to enhance detail recovery in dark regions. To support this setting, we design a 9-stop bracketing pipeline to synthesize realistic UHDR images and contribute a corresponding dataset based on diverse scenes, using only the shortest exposure as input for reconstruction. Extensive experiments show that UltraLED significantly outperforms existing single-frame approaches. Our code and dataset are made publicly available at https://srameo.github.io/projects/ultraled.
PrismGS: Physically-Grounded Anti-Aliasing for High-Fidelity Large-Scale 3D Gaussian Splatting
Oct 09, 20253D Gaussian Splatting (3DGS) has recently enabled real-time photorealistic rendering in compact scenes, but scaling to large urban environments introduces severe aliasing artifacts and optimization instability, especially under high-resolution (e.g., 4K) rendering. These artifacts, manifesting as flickering textures and jagged edges, arise from the mismatch between Gaussian primitives and the multi-scale nature of urban geometry. While existing ``divide-and-conquer'' pipelines address scalability, they fail to resolve this fidelity gap. In this paper, we propose PrismGS, a physically-grounded regularization framework that improves the intrinsic rendering behavior of 3D Gaussians. PrismGS integrates two synergistic regularizers. The first is pyramidal multi-scale supervision, which enforces consistency by supervising the rendering against a pre-filtered image pyramid. This compels the model to learn an inherently anti-aliased representation that remains coherent across different viewing scales, directly mitigating flickering textures. This is complemented by an explicit size regularization that imposes a physically-grounded lower bound on the dimensions of the 3D Gaussians. This prevents the formation of degenerate, view-dependent primitives, leading to more stable and plausible geometric surfaces and reducing jagged edges. Our method is plug-and-play and compatible with existing pipelines. Extensive experiments on MatrixCity, Mill-19, and UrbanScene3D demonstrate that PrismGS achieves state-of-the-art performance, yielding significant PSNR gains around 1.5 dB against CityGaussian, while maintaining its superior quality and robustness under demanding 4K rendering.
ANTS: Shaping the Adaptive Negative Textual Space by MLLM for OOD Detection
Sep 04, 2025The introduction of negative labels (NLs) has proven effective in enhancing Out-of-Distribution (OOD) detection. However, existing methods often lack an understanding of OOD images, making it difficult to construct an accurate negative space. In addition, the presence of false negative labels significantly degrades their near-OOD performance. To address these issues, we propose shaping an Adaptive Negative Textual Space (ANTS) by leveraging the understanding and reasoning capabilities of multimodal large language models (MLLMs). Specifically, we identify images likely to be OOD samples as negative images and prompt the MLLM to describe these images, generating expressive negative sentences that precisely characterize the OOD distribution and enhance far-OOD detection. For the near-OOD setting, where OOD samples resemble the in-distribution (ID) subset, we first identify the subset of ID classes that are visually similar to negative images and then leverage the reasoning capability of MLLMs to generate visually similar negative labels tailored to this subset, effectively reducing false negatives and improving near-OOD detection. To balance these two types of negative textual spaces, we design an adaptive weighted score that enables the method to handle different OOD task settings (near-OOD and far-OOD) without relying on task-specific prior knowledge, making it highly adaptable in open environments. On the ImageNet benchmark, our ANTS significantly reduces the FPR95 by 4.2\%, establishing a new state-of-the-art. Furthermore, our method is training-free and zero-shot, enabling high scalability.