 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Zipfian Distribution of Stopwords and Subset Selection Models
Mar 05, 2026Stopwords are words that are not very informative to the content or the meaning of a language text. Most stopwords are function words but can also be common verbs, adjectives and adverbs. In contrast to the well known Zipf's law for rank-frequency plot for all words, the rank-frequency plot for stopwords are best fitted by the Beta Rank Function (BRF). On the other hand, the rank-frequency plots of non-stopwords also deviate from the Zipf's law, but are fitted better by a quadratic function of log-token-count over log-rank than by BRF. Based on the observed rank of stopwords in the full word list, we propose a stopword (subset) selection model that the probability for being selected as a function of the word's rank $r$ is a decreasing Hill's function ($1/(1+(r/r_{mid})^γ)$); whereas the probability for not being selected is the standard Hill's function ( $1/(1+(r_{mid}/r)^γ)$). We validate this selection probability model by a direct estimation from an independent collection of texts. We also show analytically that this model leads to a BRF rank-frequency distribution for stopwords when the original full word list follows the Zipf's law, as well as explaining the quadratic fitting function for the non-stopwords.
Quadratic Term Correction on Heaps' Law
Nov 18, 2025Heaps' or Herdan's law characterizes the word-type vs. word-token relation by a power-law function, which is concave in linear-linear scale but a straight line in log-log scale. However, it has been observed that even in log-log scale, the type-token curve is still slightly concave, invalidating the power-law relation. At the next-order approximation, we have shown, by twenty English novels or writings (some are translated from another language to English), that quadratic functions in log-log scale fit the type-token data perfectly. Regression analyses of log(type)-log(token) data with both a linear and quadratic term consistently lead to a linear coefficient of slightly larger than 1, and a quadratic coefficient around -0.02. Using the ``random drawing colored ball from the bag with replacement" model, we have shown that the curvature of the log-log scale is identical to a ``pseudo-variance" which is negative. Although a pseudo-variance calculation may encounter numeric instability when the number of tokens is large, due to the large values of pseudo-weights, this formalism provides a rough estimation of the curvature when the number of tokens is small.
AesTest: Measuring Aesthetic Intelligence from Perception to Production
Nov 09, 2025Perceiving and producing aesthetic judgments is a fundamental yet underexplored capability for multimodal large language models (MLLMs). However, existing benchmarks for image aesthetic assessment (IAA) are narrow in perception scope or lack the diversity needed to evaluate systematic aesthetic production. To address this gap, we introduce AesTest, a comprehensive benchmark for multimodal aesthetic perception and production, distinguished by the following features: 1) It consists of curated multiple-choice questions spanning ten tasks, covering perception, appreciation, creation, and photography. These tasks are grounded in psychological theories of generative learning. 2) It integrates data from diverse sources, including professional editing workflows, photographic composition tutorials, and crowdsourced preferences. It ensures coverage of both expert-level principles and real-world variation. 3) It supports various aesthetic query types, such as attribute-based analysis, emotional resonance, compositional choice, and stylistic reasoning. We evaluate both instruction-tuned IAA MLLMs and general MLLMs on AesTest, revealing significant challenges in building aesthetic intelligence. We will publicly release AesTest to support future research in this area.
Characterizing Ranked Chinese Syllable-to-Character Mapping Spectrum: A Bridge Between the Spoken and Written Chinese Language
May 08, 2012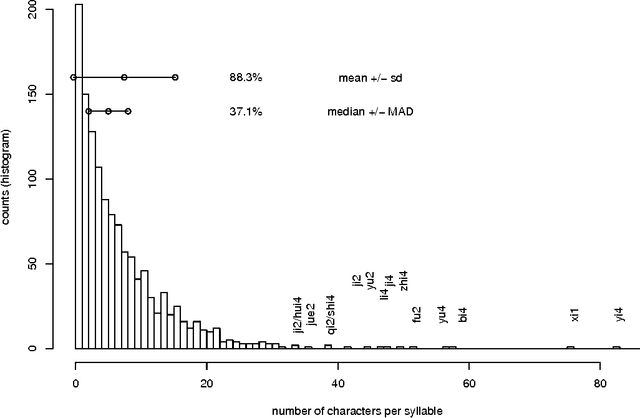
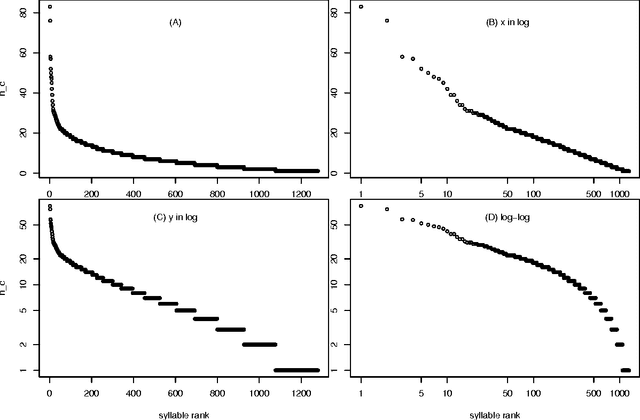
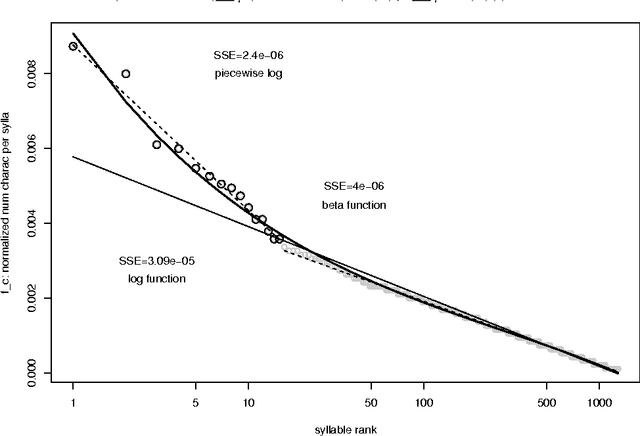
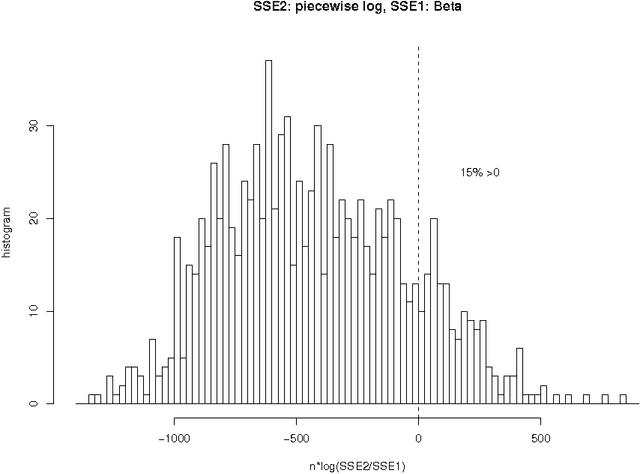
One important aspect of the relationship between spoken and written Chinese is the ranked syllable-to-character mapping spectrum, which is the ranked list of syllables by the number of characters that map to the syllable. Previously, this spectrum is analyzed for more than 400 syllables without distinguishing the four intonations. In the current study, the spectrum with 1280 toned syllables is analyzed by logarithmic function, Beta rank function, and piecewise logarithmic function. Out of the three fitting functions, the two-piece logarithmic function fits the data the best, both by the smallest sum of squared errors (SSE) and by the lowest Akaike information criterion (AIC) value. The Beta rank function is the close second. By sampling from a Poisson distribution whose parameter value is chosen from the observed data, we empirically estimate the $p$-value for testing the two-piece-logarithmic-function being better than the Beta rank function hypothesis, to be 0.16. For practical purposes, the piecewise logarithmic function and the Beta rank function can be considered a tie.
* 15 pages, 4 figures
Fitting Ranked English and Spanish Letter Frequency Distribution in U.S. and Mexican Presidential Speeches
Mar 15, 2011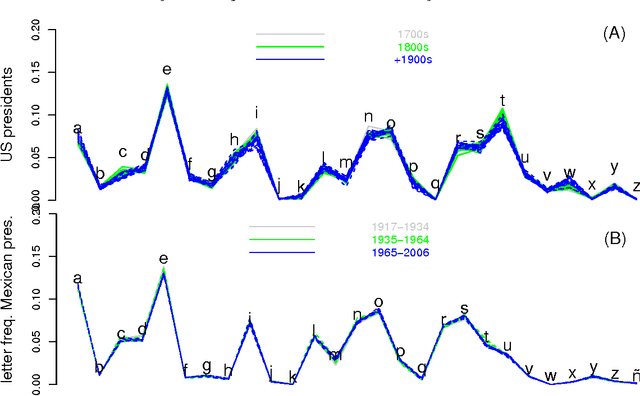
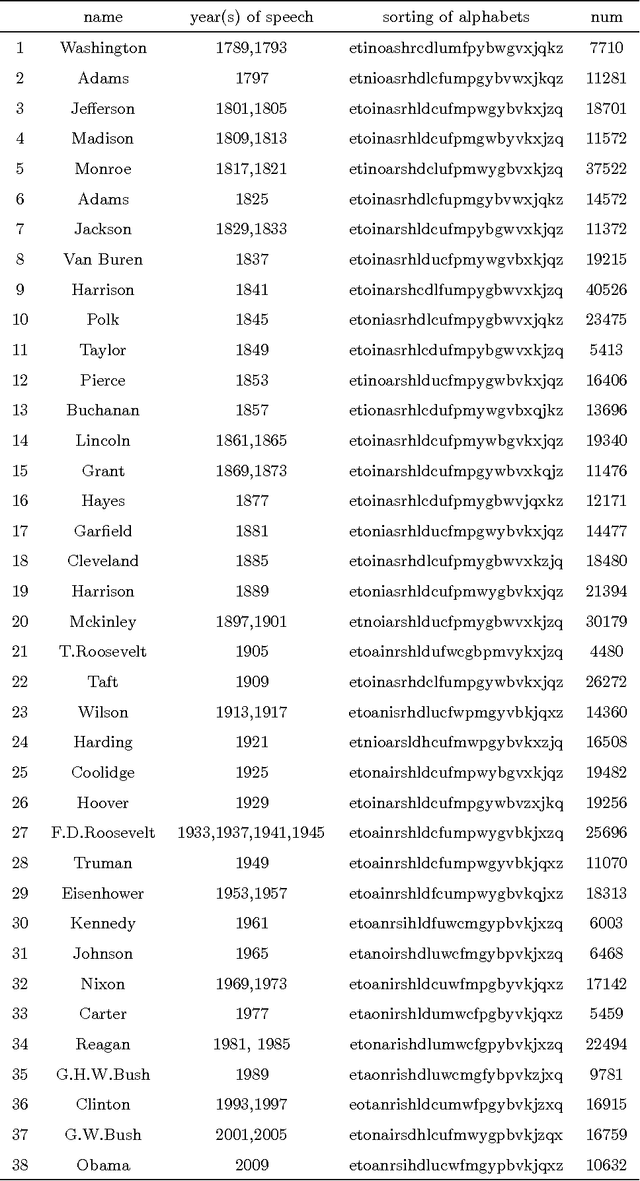
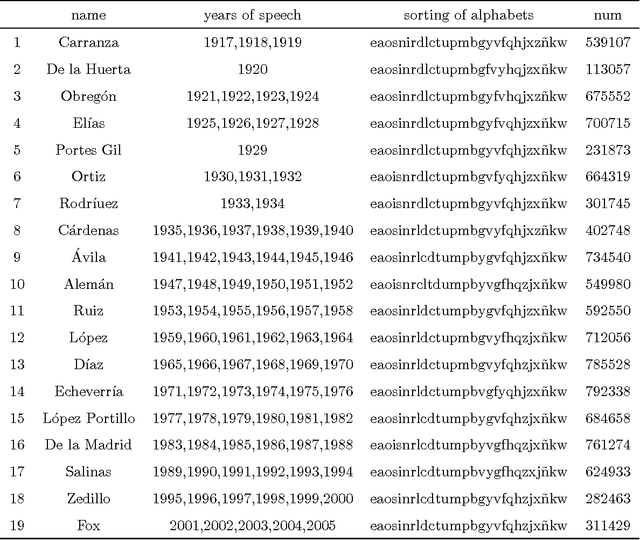
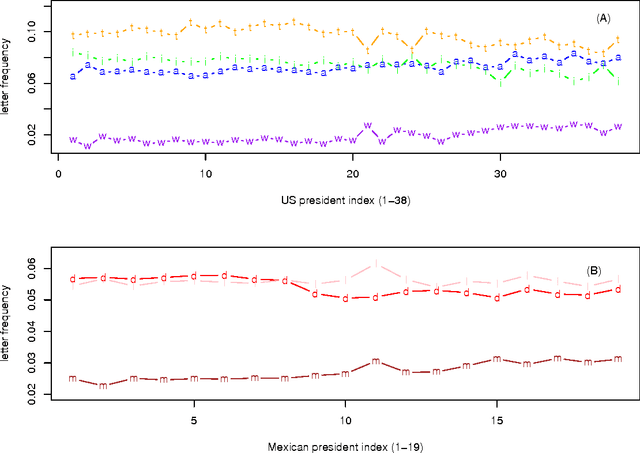
The limited range in its abscissa of ranked letter frequency distributions causes multiple functions to fit the observed distribution reasonably well. In order to critically compare various functions, we apply the statistical model selections on ten functions, using the texts of U.S. and Mexican presidential speeches in the last 1-2 centuries. Dispite minor switching of ranking order of certain letters during the temporal evolution for both datasets, the letter usage is generally stable. The best fitting function, judged by either least-square-error or by AIC/BIC model selection, is the Cocho/Beta function. We also use a novel method to discover clusters of letters by their observed-over-expected frequency ratios.
* 7 figures