 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4V as a Generalist Evaluator for Vision-Language Tasks
Nov 02, 2023Automatically evaluating vision-language tasks is challenging, especially when it comes to reflecting human judgments due to limitations in accounting for fine-grained details. Although GPT-4V has shown promising results in various multi-modal tasks, leveraging GPT-4V as a generalist evaluator for these tasks has not yet been systematically explored. We comprehensively validate GPT-4V's capabilities for evaluation purposes, addressing tasks ranging from foundational image-to-text and text-to-image synthesis to high-level image-to-image translations and multi-images to text alignment. We employ two evaluation methods, single-answer grading and pairwise comparison, using GPT-4V. Notably, GPT-4V shows promising agreement with humans across various tasks and evaluation methods, demonstrating immense potential for multi-modal LLMs as evaluators. Despite limitations like restricted visual clarity grading and real-world complex reasoning, its ability to provide human-aligned scores enriched with detailed explanations is promising for universal automatic evaluator.
Do you really follow me? Adversarial Instructions for Evaluating the Robustness of Large Language Models
Aug 17, 2023



Large Language Models (LLMs) have shown remarkable proficiency in following instructions, making them valuable in customer-facing applications. However, their impressive capabilities also raise concerns about the amplification of risks posed by adversarial instructions, which can be injected into the model input by third-party attackers to manipulate LLMs' original instructions and prompt unintended actions and content. Therefore, it is crucial to understand LLMs' ability to accurately discern which instructions to follow to ensure their safe deployment in real-world scenarios. In this paper, we propose a pioneering benchmark for automatically evaluating the robustness of LLMs against adversarial instructions. The objective of this benchmark is to quantify the extent to which LLMs are influenced by injected adversarial instructions and assess their ability to differentiate between these adversarial instructions and original user instructions. Through experiments conducted with state-of-the-art instruction-following LLMs, we uncover significant limitations in their robustness against adversarial instruction attacks. Furthermore, our findings indicate that prevalent instruction-tuned models are prone to being overfitted to follow any instruction phrase in the prompt without truly understanding which instructions should be followed. This highlights the need to address the challenge of training models to comprehend prompts instead of merely following instruction phrases and completing the text.
Augmenting Language Models with Long-Term Memory
Jun 12, 2023Existing large language models (LLMs) can only afford fix-sized inputs due to the input length limit, preventing them from utilizing rich long-context information from past inputs. To address this, we propose a framework, Language Models Augmented with Long-Term Memory (LongMem), which enables LLMs to memorize long history. We design a novel decoupled network architecture with the original backbone LLM frozen as a memory encoder and an adaptive residual side-network as a memory retriever and reader. Such a decoupled memory design can easily cache and update long-term past contexts for memory retrieval without suffering from memory staleness. Enhanced with memory-augmented adaptation training, LongMem can thus memorize long past context and use long-term memory for language modeling. The proposed memory retrieval module can handle unlimited-length context in its memory bank to benefit various downstream tasks. Typically, LongMem can enlarge the long-form memory to 65k tokens and thus cache many-shot extra demonstration examples as long-form memory for in-context learning. Experiments show that our method outperforms strong long-context models on ChapterBreak, a challenging long-context modeling benchmark, and achieves remarkable improvements on memory-augmented in-context learning over LLMs. The results demonstrate that the proposed method is effective in helping language models to memorize and utilize long-form contents. Our code is open-sourced at https://aka.ms/LongMem.
STEPS: A Benchmark for Order Reasoning in Sequential Tasks
Jun 07, 2023



Various human activities can be abstracted into a sequence of actions in natural text, i.e. cooking, repairing, manufacturing, etc. Such action sequences heavily depend on the executing order, while disorder in action sequences leads to failure of further task execution by robots or AI agents. Therefore, to verify the order reasoning capability of current neural models in sequential tasks, we propose a challenging benchmark , named STEPS. STEPS involves two subtask settings, focusing on determining the rationality of given next step in recipes and selecting the reasonable step from the multi-choice question, respectively. We describe the data construction and task formulations, and benchmark most of significant Large Language Models (LLMs). The experimental results demonstrate 1) The commonsense reasoning of action orders in sequential tasks are challenging to resolve via zero-shot prompting or few-shot in-context learning for LLMs; 2) Prompting method still significantly lags behind tuning-based method on STEPS.
Graph Reasoning for Question Answering with Triplet Retrieval
May 30, 2023



Answering complex questions often requires reasoning over knowledge graphs (KGs). State-of-the-art methods often utilize entities in questions to retrieve local subgraphs, which are then fed into KG encoder, e.g. graph neural networks (GNNs), to model their local structures and integrated into language models for question answering. However, this paradigm constrains retrieved knowledge in local subgraphs and discards more diverse triplets buried in KGs that are disconnected but useful for question answering. In this paper, we propose a simple yet effective method to first retrieve the most relevant triplets from KGs and then rerank them, which are then concatenated with questions to be fed into language models. Extensive results on both CommonsenseQA and OpenbookQA datasets show that our method can outperform state-of-the-art up to 4.6% absolute accuracy.
Bot or Human? Detecting ChatGPT Imposters with A Single Question
May 16, 2023


Large language models like ChatGPT have recently demonstrated impressive capabilities in natural language understanding and generation, enabling various applications including translation, essay writing, and chit-chatting. However, there is a concern that they can be misused for malicious purposes, such as fraud or denial-of-service attacks. Therefore, it is crucial to develop methods for detecting whether the party involved in a conversation is a bot or a human. In this paper, we propose a framework named FLAIR, Finding Large language model Authenticity via a single Inquiry and Response, to detect conversational bots in an online manner. Specifically, we target a single question scenario that can effectively differentiate human users from bots. The questions are divided into two categories: those that are easy for humans but difficult for bots (e.g., counting, substitution, positioning, noise filtering, and ASCII art), and those that are easy for bots but difficult for humans (e.g., memorization and computation). Our approach shows different strengths of these questions in their effectiveness, providing a new way for online service providers to protect themselves against nefarious activities and ensure that they are serving real users. We open-sourced our dataset on https://github.com/hongwang600/FLAIR and welcome contributions from the community to enrich such detection datasets.
Guiding Large Language Models via Directional Stimulus Prompting
Feb 22, 2023We introduce a new framework, Directional Stimulus Prompting, that uses a tuneable language model (LM) to provide guidance for the black-box frozen large language model (LLM) on downstream tasks. Unlike prior work that manually or automatically finds the optimal prompt for each task, we train a policy LM to generate discrete tokens as ``directional stimulus'' of each input, which is a hint/cue such as keywords of an article for summarization. The directional stimulus is then combined with the original input and fed into the LLM to guide its generation toward the desired target. The policy LM can be trained through 1) supervised learning from annotated data and 2) reinforcement learning from offline and online rewards to explore directional stimulus that better aligns LLMs with human preferences. This framework is flexibly applicable to various LMs and tasks. To verify its effectiveness, we apply our framework to summarization and dialogue response generation tasks. Experimental results demonstrate that it can significantly improve LLMs' performance with a small collection of training data: a T5 (780M) trained with 2,000 samples from the CNN/Daily Mail dataset improves Codex (175B)'s performance by 7.2% in ROUGE-Avg scores; 500 dialogues boost the combined score by 52.5%, achieving comparable or even better performance than fully trained models on the MultiWOZ dataset.
Language Model Detoxification in Dialogue with Contextualized Stance Control
Jan 25, 2023



To reduce the toxic degeneration in a pretrained Language Model (LM), previous work on Language Model detoxification has focused on reducing the toxicity of the generation itself (self-toxicity) without consideration of the context. As a result, a type of implicit offensive language where the generations support the offensive language in the context is ignored. Different from the LM controlling tasks in previous work, where the desired attributes are fixed for generation, the desired stance of the generation depends on the offensiveness of the context. Therefore, we propose a novel control method to do context-dependent detoxification with the stance taken into consideration. We introduce meta prefixes to learn the contextualized stance control strategy and to generate the stance control prefix according to the input context. The generated stance prefix is then combined with the toxicity control prefix to guide the response generation. Experimental results show that our proposed method can effectively learn the context-dependent stance control strategies while keeping a low self-toxicity of the underlying LM.
Explanations from Large Language Models Make Small Reasoners Better
Oct 13, 2022
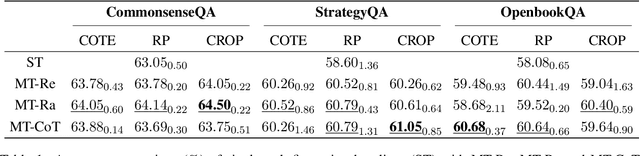
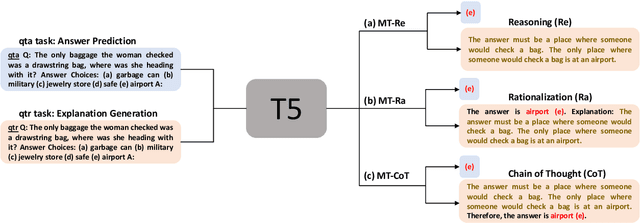
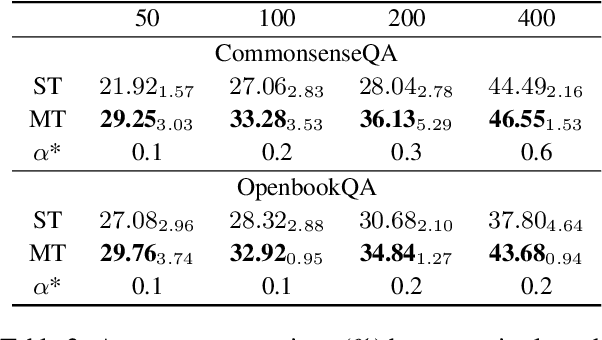
Integrating free-text explanations to in-context learning of large language models (LLM) is shown to elicit strong reasoning capabilities along with reasonable explanations. In this paper, we consider the problem of leveraging the explanations generated by LLM to improve the training of small reasoners, which are more favorable in real-production deployment due to their low cost. We systematically explore three explanation generation approaches from LLM and utilize a multi-task learning framework to facilitate small models to acquire strong reasoning power together with explanation generation capabilities. Experiments on multiple reasoning tasks show that our method can consistently and significantly outperform finetuning baselines across different settings, and even perform better than finetuning/prompting a 60x larger GPT-3 (175B) model by up to 9.5% in accuracy. As a side benefit, human evaluation further shows that our method can generate high-quality explanations to justify its predictions, moving towards the goal of explainable AI.
Controllable Dialogue Simulation with In-Context Learning
Oct 09, 2022
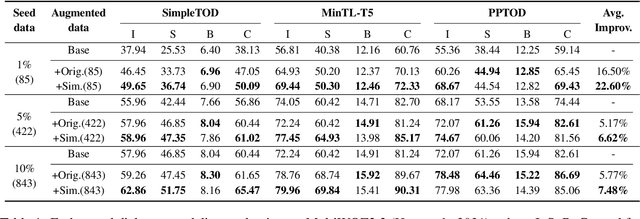

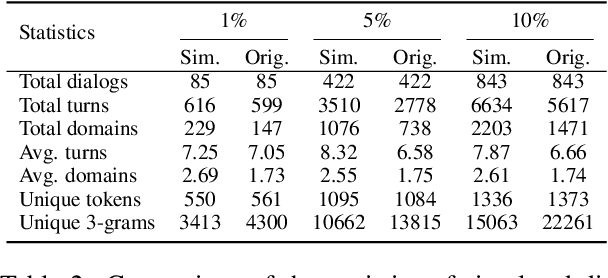
Building dialogue systems requires a large corpus of annotated dialogues. Such datasets are usually created via crowdsourcing, which is expensive and time-consuming. In this paper, we propose a novel method for dialogue simulation based on language model in-context learning, dubbed as \textsc{Dialogic}. Seeded with a few annotated dialogues, \textsc{Dialogic} automatically selects in-context examples for demonstration and prompts GPT-3 to generate new dialogues and their annotations in a controllable way. Leveraging the strong in-context learning ability of GPT-3, our method can be used to rapidly expand a small set of dialogue data without requiring \textit{human involvement} or \textit{parameter update}, and is thus much more cost-efficient and time-saving than crowdsourcing. Experimental results on the MultiWOZ dataset demonstrate that training a model on the simulated dialogues leads to even better performance than using the same amount of human-generated dialogues in the low-resource settings, with as few as 85 dialogues as the seed data. Human evaluation results also show that our simulated dialogues has high language fluency and annotation accuracy. The code and data are available at \href{https://github.com/Leezekun/dialogic}{https://github.com/Leezekun/dialogic}.