 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Masked Autoencoders are Stronger Vision Learners
Jul 27, 2022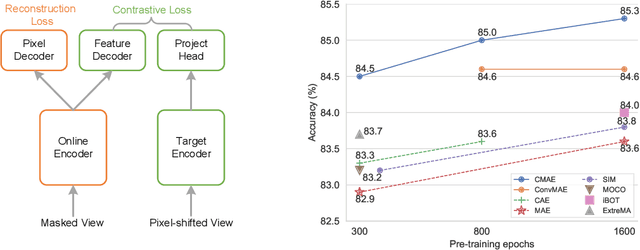

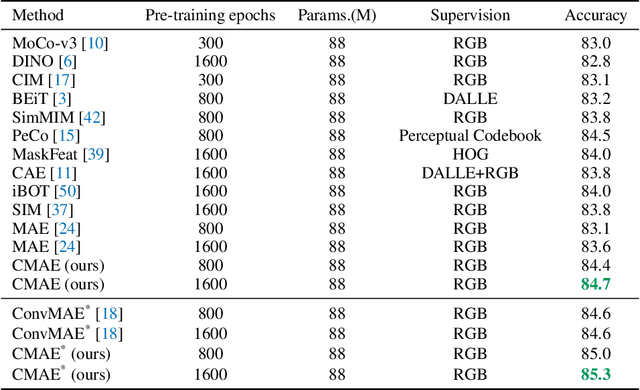
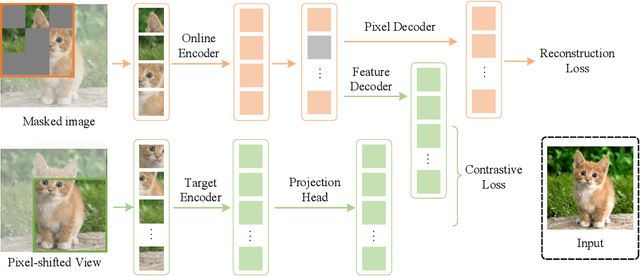
Masked image modeling (MIM) has achieved promising results on various vision tasks. However, the limited discriminability of learned representation manifests there is still plenty to go for making a stronger vision learner. Towards this goal, we propose Contrastive Masked Autoencoders (CMAE), a new self-supervised pre-training method for learning more comprehensive and capable vision representations. By elaboratively unifying contrastive learning (CL) and masked image model (MIM) through novel designs, CMAE leverages their respective advantages and learns representations with both strong instance discriminability and local perceptibility. Specifically, CMAE consists of two branches where the online branch is an asymmetric encoder-decoder and the target branch is a momentum updated encoder. During training, the online encoder reconstructs original images from latent representations of masked images to learn holistic features. The target encoder, fed with the full images, enhances the feature discriminability via contrastive learning with its online counterpart. To make CL compatible with MIM, CMAE introduces two new components, i.e. pixel shift for generating plausible positive views and feature decoder for complementing features of contrastive pairs. Thanks to these novel designs, CMAE effectively improves the representation quality and transfer performance over its MIM counterpart. CMAE achieves the state-of-the-art performance on highly competitive benchmarks of image classification, semantic segmentation and object detection. Notably, CMAE-Base achieves $85.3\%$ top-1 accuracy on ImageNet and $52.5\%$ mIoU on ADE20k, surpassing previous best results by $0.7\%$ and $1.8\%$ respectively. Codes will be made publicly available.
SemanticStyleGAN: Learning Compositional Generative Priors for Controllable Image Synthesis and Editing
Dec 07, 2021
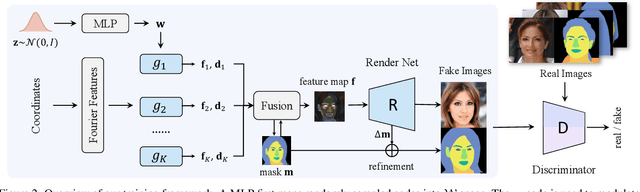
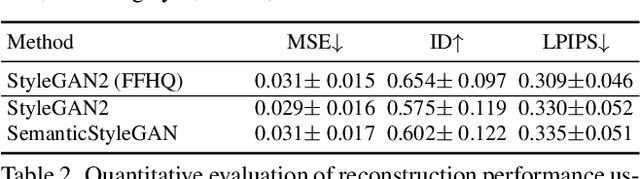
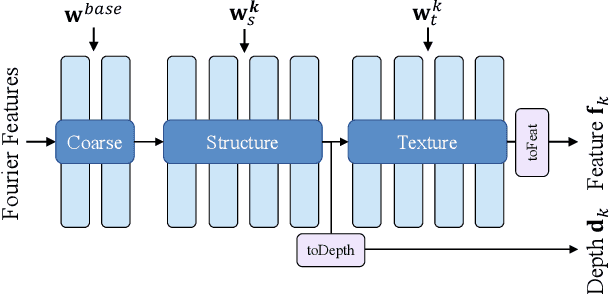
Recent studies have shown that StyleGANs provide promising prior models for downstream tasks on image synthesis and editing. However, since the latent codes of StyleGANs are designed to control global styles, it is hard to achieve a fine-grained control over synthesized images. We present SemanticStyleGAN, where a generator is trained to model local semantic parts separately and synthesizes images in a compositional way. The structure and texture of different local parts are controlled by corresponding latent codes. Experimental results demonstrate that our model provides a strong disentanglement between different spatial areas. When combined with editing methods designed for StyleGANs, it can achieve a more fine-grained control to edit synthesized or real images. The model can also be extended to other domains via transfer learning. Thus, as a generic prior model with built-in disentanglement, it could facilitate the development of GAN-based applications and enable more potential downstream tasks.
Video Salient Object Detection via Contrastive Features and Attention Modules
Nov 03, 2021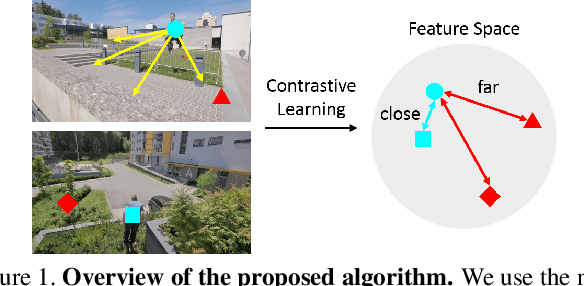
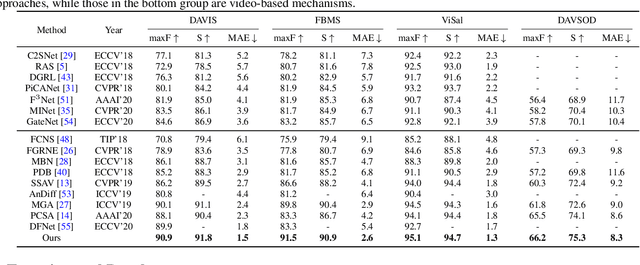
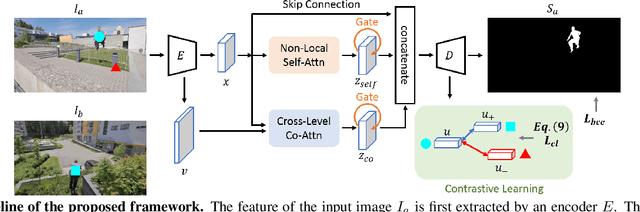
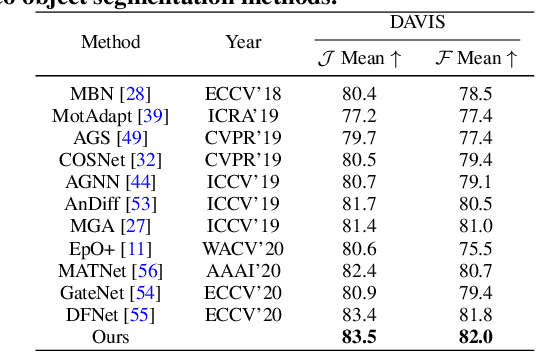
Video salient object detection aims to find the most visually distinctive objects in a video. To explore the temporal dependencies, existing methods usually resort to recurrent neural networks or optical flow. However, these approaches require high computational cost, and tend to accumulate inaccuracies over time. In this paper, we propose a network with attention modules to learn contrastive features for video salient object detection without the high computational temporal modeling techniques. We develop a non-local self-attention scheme to capture the global information in the video frame. A co-attention formulation is utilized to combine the low-level and high-level features. We further apply the contrastive learning to improve the feature representations, where foreground region pairs from the same video are pulled together, and foreground-background region pairs are pushed away in the latent space. The intra-frame contrastive loss helps separate the foreground and background features, and the inter-frame contrastive loss improves the temporal consistency. We conduct extensive experiments on several benchmark datasets for video salient object detection and unsupervised video object segmentation, and show that the proposed method requires less computation, and performs favorably against the state-of-the-art approaches.
Adversarial Open Domain Adaption for Sketch-to-Photo Synthesis
Apr 12, 2021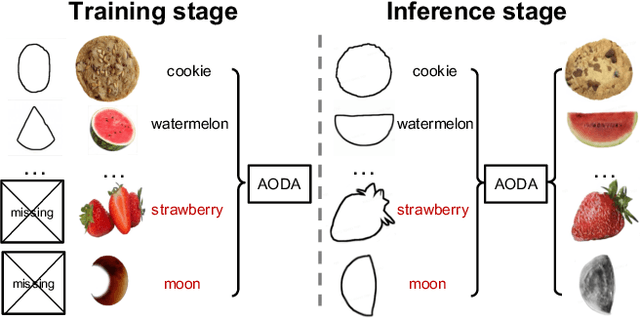



In this paper, we explore the open-domain sketch-to-photo translation, which aims to synthesize a realistic photo from a freehand sketch with its class label, even if the sketches of that class are missing in the training data. It is challenging due to the lack of training supervision and the large geometry distortion between the freehand sketch and photo domains. To synthesize the absent freehand sketches from photos, we propose a framework that jointly learns sketch-to-photo and photo-to-sketch generation. However, the generator trained from fake sketches might lead to unsatisfying results when dealing with sketches of missing classes, due to the domain gap between synthesized sketches and real ones. To alleviate this issue, we further propose a simple yet effective open-domain sampling and optimization strategy to "fool" the generator into treating fake sketches as real ones. Our method takes advantage of the learned sketch-to-photo and photo-to-sketch mapping of in-domain data and generalizes them to the open-domain classes. We validate our method on the Scribble and SketchyCOCO datasets. Compared with the recent competing methods, our approach shows impressive results in synthesizing realistic color, texture, and maintaining the geometric composition for various categories of open-domain sketches.
DynOcc: Learning Single-View Depth from Dynamic Occlusion Cues
Mar 30, 2021
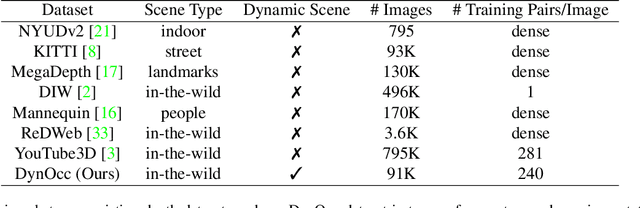
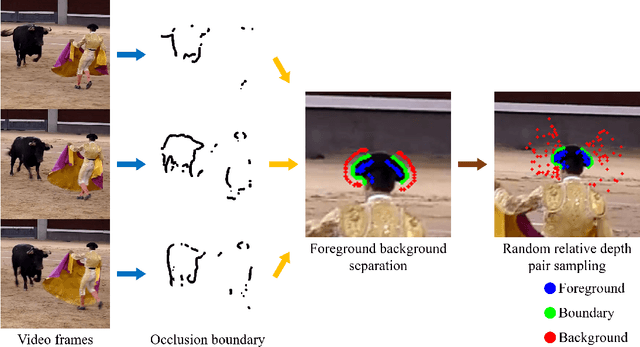
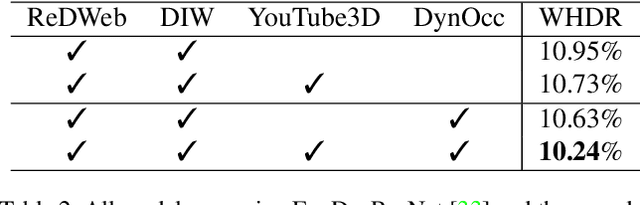
Recently, significant progress has been made in single-view depth estimation thanks to increasingly large and diverse depth datasets. However, these datasets are largely limited to specific application domains (e.g. indoor, autonomous driving) or static in-the-wild scenes due to hardware constraints or technical limitations of 3D reconstruction. In this paper, we introduce the first depth dataset DynOcc consisting of dynamic in-the-wild scenes. Our approach leverages the occlusion cues in these dynamic scenes to infer depth relationships between points of selected video frames. To achieve accurate occlusion detection and depth order estimation, we employ a novel occlusion boundary detection, filtering and thinning scheme followed by a robust foreground/background classification method. In total our DynOcc dataset contains 22M depth pairs out of 91K frames from a diverse set of videos. Using our dataset we achieved state-of-the-art results measured in weighted human disagreement rate (WHDR). We also show that the inferred depth maps trained with DynOcc can preserve sharper depth boundaries.
Unsupervised Real-world Low-light Image Enhancement with Decoupled Networks
May 06, 2020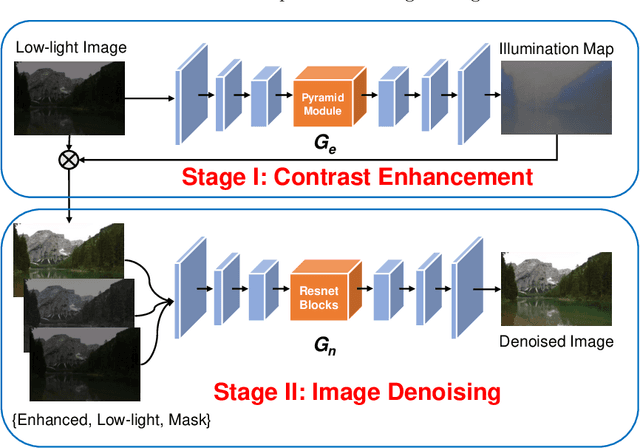



Conventional learning-based approaches to low-light image enhancement typically require a large amount of paired training data, which are difficult to acquire in real-world scenarios. Recently, unsupervised models for this task have been explored to eliminate the use of paired data. However, these methods primarily tackle the problem of illumination enhancement, and usually fail to suppress the noises that ubiquitously exist in images taken under real-world low-light conditions. In this paper, we address the real-world low-light image enhancement problem by decoupling this task into two sub-tasks: illumination enhancement and noise suppression. We propose to learn a two-stage GAN-based framework to enhance the real-world low-light images in a fully unsupervised fashion. In addition to conventional benchmark datasets, a new unpaired low-light image enhancement dataset is built and used to thoroughly evaluate the performance of our model. Extensive experiments show that our method outperforms the state-of-the-art unsupervised image enhancement methods in terms of both illumination enhancement and noise reduction.
Human Motion Transfer from Poses in the Wild
Apr 07, 2020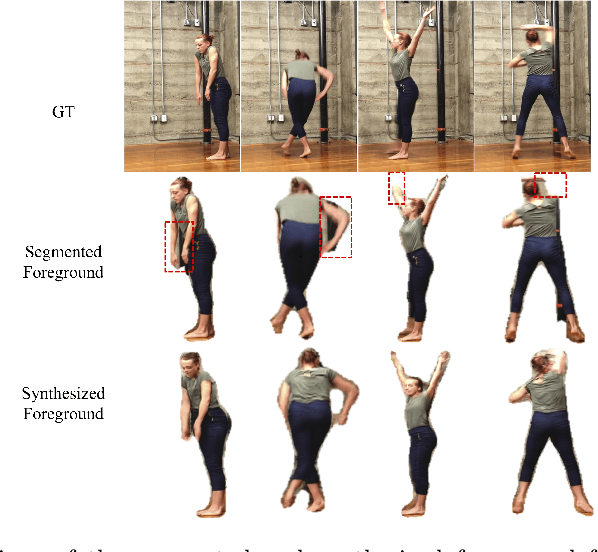
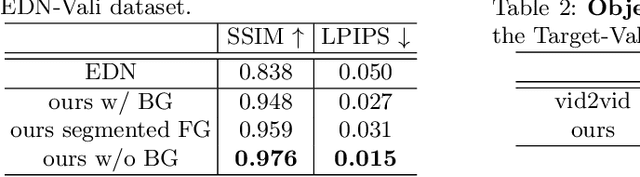
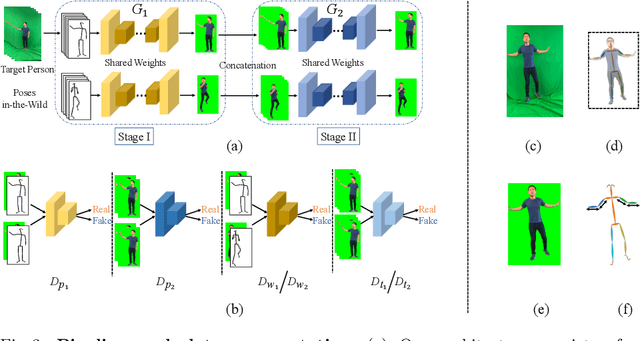

In this paper, we tackle the problem of human motion transfer, where we synthesize novel motion video for a target person that imitates the movement from a reference video. It is a video-to-video translation task in which the estimated poses are used to bridge two domains. Despite substantial progress on the topic, there exist several problems with the previous methods. First, there is a domain gap between training and testing pose sequences--the model is tested on poses it has not seen during training, such as difficult dancing moves. Furthermore, pose detection errors are inevitable, making the job of the generator harder. Finally, generating realistic pixels from sparse poses is challenging in a single step. To address these challenges, we introduce a novel pose-to-video translation framework for generating high-quality videos that are temporally coherent even for in-the-wild pose sequences unseen during training. We propose a pose augmentation method to minimize the training-test gap, a unified paired and unpaired learning strategy to improve the robustness to detection errors, and two-stage network architecture to achieve superior texture quality. To further boost research on the topic, we build two human motion datasets. Finally, we show the superiority of our approach over the state-of-the-art studies through extensive experiments and evaluations on different datasets.
Anatomy-aware 3D Human Pose Estimation in Videos
Mar 17, 2020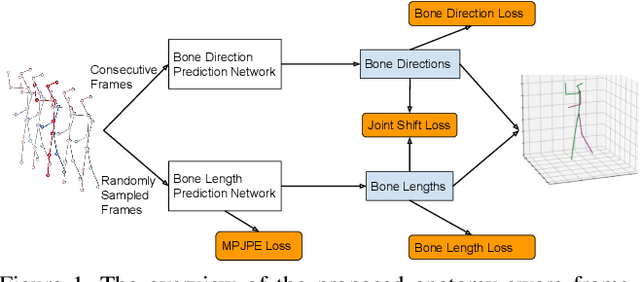
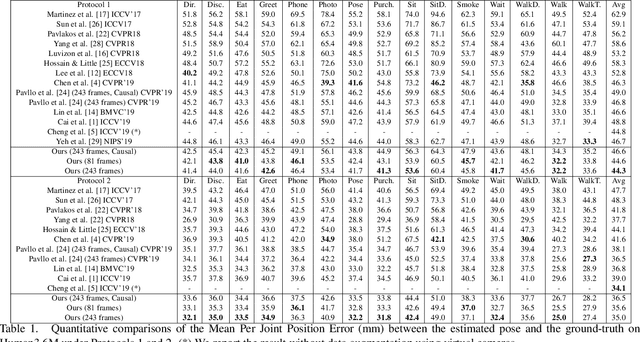
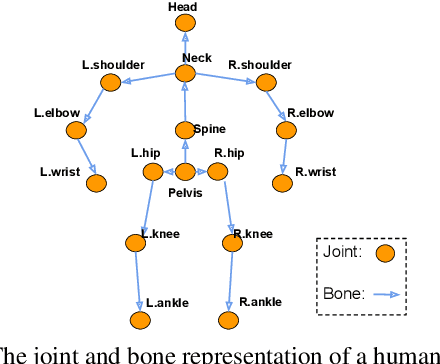
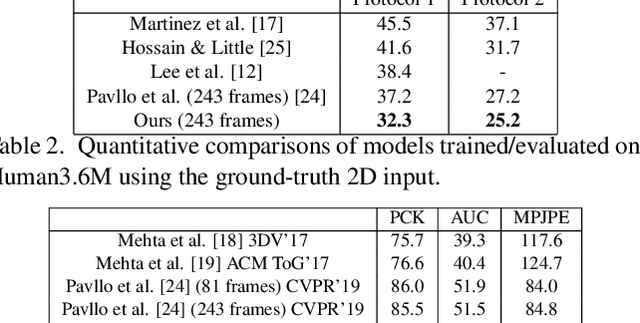
In this work, we propose a new solution for 3D human pose estimation in videos. Instead of directly regressing the 3D joint locations, we draw inspiration from the human skeleton anatomy and decompose the task into bone direction prediction and bone length prediction, from which the 3D joint locations can be completely derived. Our motivation is the fact that the bone lengths of a human skeleton remain consistent across time. This promotes us to develop effective techniques to utilize global information across {\it all} the frames in a video for high-accuracy bone length prediction. Moreover, for the bone direction prediction network, we propose a fully-convolutional propagating architecture with long skip connections. Essentially, it predicts the directions of different bones hierarchically without using any time-consuming memory units (e.g. LSTM). A novel joint shift loss is further introduced to bridge the training of the bone length and bone direction prediction networks. Finally, we employ an implicit attention mechanism to feed the 2D keypoint visibility scores into the model as extra guidance, which significantly mitigates the depth ambiguity in many challenging poses. Our full model outperforms the previous best results on Human3.6M and MPI-INF-3DHP datasets, where comprehensive evaluation validates the effectiveness of our model.
EnlightenGAN: Deep Light Enhancement without Paired Supervision
Jun 17, 2019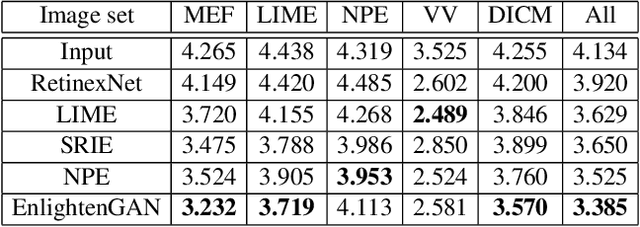
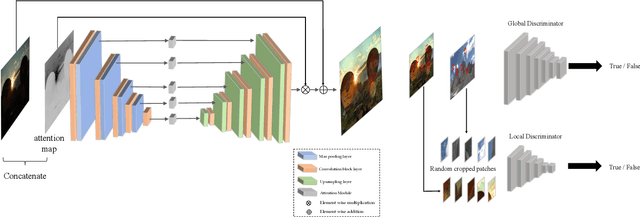


Deep learning-based methods have achieved remarkable success in image restoration and enhancement, but are they still competitive when there is a lack of paired training data? As one such example, this paper explores the low-light image enhancement problem, where in practice it is extremely challenging to simultaneously take a low-light and a normal-light photo of the same visual scene. We propose a highly effective unsupervised generative adversarial network, dubbed EnlightenGAN, that can be trained without low/normal-light image pairs, yet proves to generalize very well on various real-world test images. Instead of supervising the learning using ground truth data, we propose to regularize the unpaired training using the information extracted from the input itself, and benchmark a series of innovations for the low-light image enhancement problem, including a global-local discriminator structure, a self-regularized perceptual loss fusion, and attention mechanism. Through extensive experiments, our proposed approach outperforms recent methods under a variety of metrics in terms of visual quality and subjective user study. Thanks to the great flexibility brought by unpaired training, EnlightenGAN is demonstrated to be easily adaptable to enhancing real-world images from various domains. The code is available at \url{https://github.com/yueruchen/EnlightenGAN}
Fashion Editing with Multi-scale Attention Normalization
Jun 03, 2019
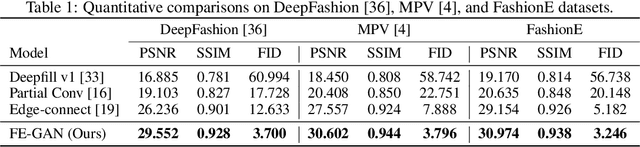
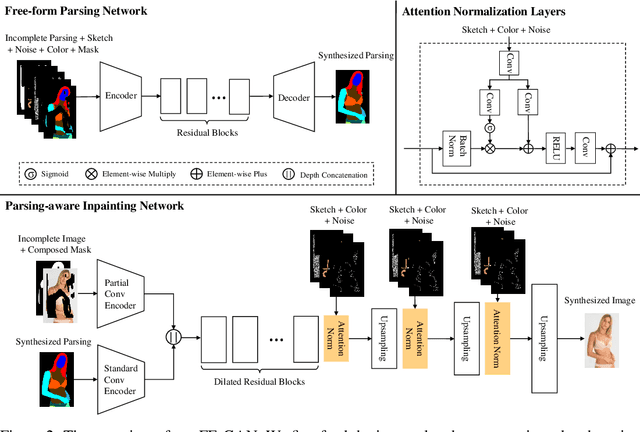

Interactive fashion image manipulation, which enables users to edit images with sketches and color strokes, is an interesting research problem with great application value. Existing works often treat it as a general inpainting task and do not fully leverage the semantic structural information in fashion images. Moreover, they directly utilize conventional convolution and normalization layers to restore the incomplete image, which tends to wash away the sketch and color information. In this paper, we propose a novel Fashion Editing Generative Adversarial Network (FE-GAN), which is capable of manipulating fashion images by free-form sketches and sparse color strokes. FE-GAN consists of two modules: 1) a free-form parsing network that learns to control the human parsing generation by manipulating sketch and color; 2) a parsing-aware inpainting network that renders detailed textures with semantic guidance from the human parsing map. A new attention normalization layer is further applied at multiple scales in the decoder of the inpainting network to enhance the quality of the synthesized image. Extensive experiments on high-resolution fashion image datasets demonstrate that the proposed method significantly outperforms the state-of-the-art methods on image manipulation.