 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model
Apr 22, 2026We present LLaDA2.0-Uni, a unified discrete diffusion large language model (dLLM) that supports multimodal understanding and generation within a natively integrated framework. Its architecture combines a fully semantic discrete tokenizer, a MoE-based dLLM backbone, and a diffusion decoder. By discretizing continuous visual inputs via SigLIP-VQ, the model enables block-level masked diffusion for both text and vision inputs within the backbone, while the decoder reconstructs visual tokens into high-fidelity images. Inference efficiency is enhanced beyond parallel decoding through prefix-aware optimizations in the backbone and few-step distillation in the decoder. Supported by carefully curated large-scale data and a tailored multi-stage training pipeline, LLaDA2.0-Uni matches specialized VLMs in multimodal understanding while delivering strong performance in image generation and editing. Its native support for interleaved generation and reasoning establishes a promising and scalable paradigm for next-generation unified foundation models. Codes and models are available at https://github.com/inclusionAI/LLaDA2.0-Uni.
FSSUWNet: Mitigating the Fragility of Pre-trained Models with Feature Enhancement for Few-Shot Semantic Segmentation in Underwater Images
Apr 01, 2025



Few-Shot Semantic Segmentation (FSS), which focuses on segmenting new classes in images using only a limited number of annotated examples, has recently progressed in data-scarce domains. However, in this work, we show that the existing FSS methods often struggle to generalize to underwater environments. Specifically, the prior features extracted by pre-trained models used as feature extractors are fragile due to the unique challenges of underwater images. To address this, we propose FSSUWNet, a tailored FSS framework for underwater images with feature enhancement. FSSUWNet exploits the integration of complementary features, emphasizing both low-level and high-level image characteristics. In addition to employing a pre-trained model as the primary encoder, we propose an auxiliary encoder called Feature Enhanced Encoder which extracts complementary features to better adapt to underwater scene characteristics. Furthermore, a simple and effective Feature Alignment Module aims to provide global prior knowledge and align low-level features with high-level features in dimensions. Given the scarcity of underwater images, we introduce a cross-validation dataset version based on the Segmentation of Underwater Imagery dataset. Extensive experiments on public underwater segmentation datasets demonstrate that our approach achieves state-of-the-art performance. For example, our method outperforms the previous best method by 2.8% and 2.6% in terms of the mean Intersection over Union metric for 1-shot and 5-shot scenarios in the datasets, respectively. Our implementation is available at https://github.com/lizhh268/FSSUWNet.
PixelLM: Pixel Reasoning with Large Multimodal Model
Dec 04, 2023



While large multimodal models (LMMs) have achieved remarkable progress, generating pixel-level masks for image reasoning tasks involving multiple open-world targets remains a challenge. To bridge this gap, we introduce PixelLM, an effective and efficient LMM for pixel-level reasoning and understanding. Central to PixelLM is a novel, lightweight pixel decoder and a comprehensive segmentation codebook. The decoder efficiently produces masks from the hidden embeddings of the codebook tokens, which encode detailed target-relevant information. With this design, PixelLM harmonizes with the structure of popular LMMs and avoids the need for additional costly segmentation models. Furthermore, we propose a target refinement loss to enhance the model's ability to differentiate between multiple targets, leading to substantially improved mask quality. To advance research in this area, we construct MUSE, a high-quality multi-target reasoning segmentation benchmark. PixelLM excels across various pixel-level image reasoning and understanding tasks, outperforming well-established methods in multiple benchmarks, including MUSE, single- and multi-referring segmentation. Comprehensive ablations confirm the efficacy of each proposed component. All code, models, and datasets will be publicly available.
VLAB: Enhancing Video Language Pre-training by Feature Adapting and Blending
May 22, 2023Large-scale image-text contrastive pre-training models, such as CLIP, have been demonstrated to effectively learn high-quality multimodal representations. However, there is limited research on learning video-text representations for general video multimodal tasks based on these powerful features. Towards this goal, we propose a novel video-text pre-training method dubbed VLAB: Video Language pre-training by feature Adapting and Blending, which transfers CLIP representations to video pre-training tasks and develops unified video multimodal models for a wide range of video-text tasks. Specifically, VLAB is founded on two key strategies: feature adapting and feature blending. In the former, we introduce a new video adapter module to address CLIP's deficiency in modeling temporal information and extend the model's capability to encompass both contrastive and generative tasks. In the latter, we propose an end-to-end training method that further enhances the model's performance by exploiting the complementarity of image and video features. We validate the effectiveness and versatility of VLAB through extensive experiments on highly competitive video multimodal tasks, including video text retrieval, video captioning, and video question answering. Remarkably, VLAB outperforms competing methods significantly and sets new records in video question answering on MSRVTT, MSVD, and TGIF datasets. It achieves an accuracy of 49.6, 61.0, and 79.0, respectively. Codes and models will be released.
CMAE-V: Contrastive Masked Autoencoders for Video Action Recognition
Jan 15, 2023


Contrastive Masked Autoencoder (CMAE), as a new self-supervised framework, has shown its potential of learning expressive feature representations in visual image recognition. This work shows that CMAE also trivially generalizes well on video action recognition without modifying the architecture and the loss criterion. By directly replacing the original pixel shift with the temporal shift, our CMAE for visual action recognition, CMAE-V for short, can generate stronger feature representations than its counterpart based on pure masked autoencoders. Notably, CMAE-V, with a hybrid architecture, can achieve 82.2% and 71.6% top-1 accuracy on the Kinetics-400 and Something-something V2 datasets, respectively. We hope this report could provide some informative inspiration for future works.
Contrastive Masked Autoencoders are Stronger Vision Learners
Jul 27, 2022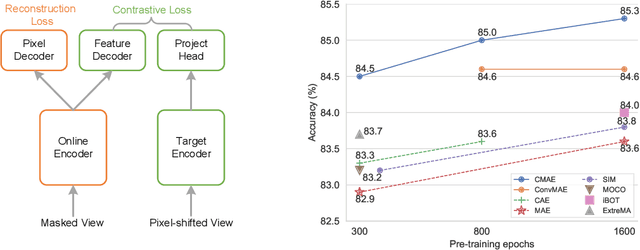

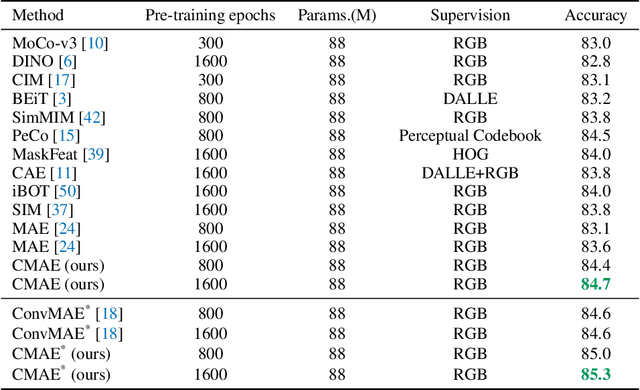
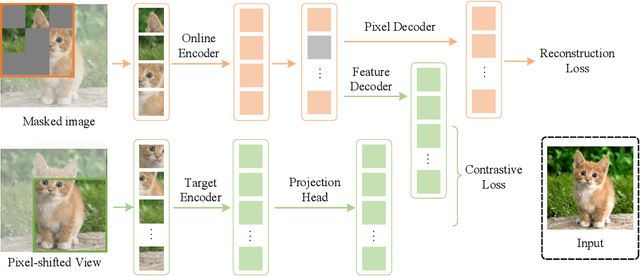
Masked image modeling (MIM) has achieved promising results on various vision tasks. However, the limited discriminability of learned representation manifests there is still plenty to go for making a stronger vision learner. Towards this goal, we propose Contrastive Masked Autoencoders (CMAE), a new self-supervised pre-training method for learning more comprehensive and capable vision representations. By elaboratively unifying contrastive learning (CL) and masked image model (MIM) through novel designs, CMAE leverages their respective advantages and learns representations with both strong instance discriminability and local perceptibility. Specifically, CMAE consists of two branches where the online branch is an asymmetric encoder-decoder and the target branch is a momentum updated encoder. During training, the online encoder reconstructs original images from latent representations of masked images to learn holistic features. The target encoder, fed with the full images, enhances the feature discriminability via contrastive learning with its online counterpart. To make CL compatible with MIM, CMAE introduces two new components, i.e. pixel shift for generating plausible positive views and feature decoder for complementing features of contrastive pairs. Thanks to these novel designs, CMAE effectively improves the representation quality and transfer performance over its MIM counterpart. CMAE achieves the state-of-the-art performance on highly competitive benchmarks of image classification, semantic segmentation and object detection. Notably, CMAE-Base achieves $85.3\%$ top-1 accuracy on ImageNet and $52.5\%$ mIoU on ADE20k, surpassing previous best results by $0.7\%$ and $1.8\%$ respectively. Codes will be made publicly available.
Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning
Apr 08, 2021
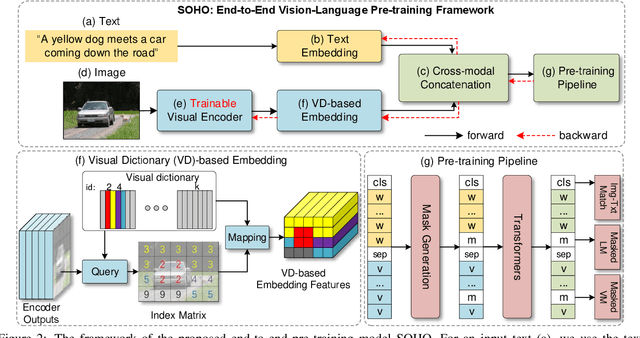
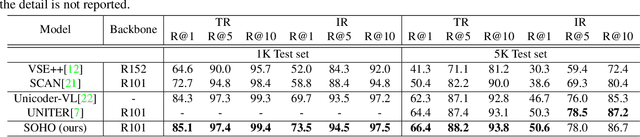
We study joint learning of Convolutional Neural Network (CNN) and Transformer for vision-language pre-training (VLPT) which aims to learn cross-modal alignments from millions of image-text pairs. State-of-the-art approaches extract salient image regions and align regions with words step-by-step. As region-based visual features usually represent parts of an image, it is challenging for existing vision-language models to fully understand the semantics from paired natural languages. In this paper, we propose SOHO to "See Out of tHe bOx" that takes a whole image as input, and learns vision-language representation in an end-to-end manner. SOHO does not require bounding box annotations which enables inference 10 times faster than region-based approaches. In particular, SOHO learns to extract comprehensive yet compact image features through a visual dictionary (VD) that facilitates cross-modal understanding. VD is designed to represent consistent visual abstractions of similar semantics. It is updated on-the-fly and utilized in our proposed pre-training task Masked Visual Modeling (MVM). We conduct experiments on four well-established vision-language tasks by following standard VLPT settings. In particular, SOHO achieves absolute gains of 2.0% R@1 score on MSCOCO text retrieval 5k test split, 1.5% accuracy on NLVR$^2$ test-P split, 6.7% accuracy on SNLI-VE test split, respectively.
Pixel-BERT: Aligning Image Pixels with Text by Deep Multi-Modal Transformers
Apr 02, 2020
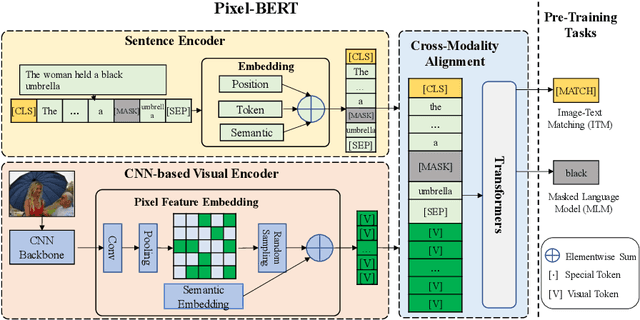
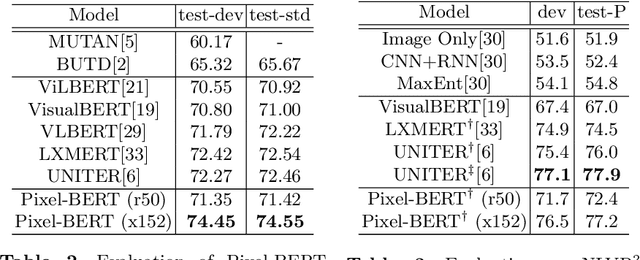
We propose Pixel-BERT to align image pixels with text by deep multi-modal transformers that jointly learn visual and language embedding in a unified end-to-end framework. We aim to build a more accurate and thorough connection between image pixels and language semantics directly from image and sentence pairs instead of using region-based image features as the most recent vision and language tasks. Our Pixel-BERT which aligns semantic connection in pixel and text level solves the limitation of task-specific visual representation for vision and language tasks. It also relieves the cost of bounding box annotations and overcomes the unbalance between semantic labels in visual task and language semantic. To provide a better representation for down-stream tasks, we pre-train a universal end-to-end model with image and sentence pairs from Visual Genome dataset and MS-COCO dataset. We propose to use a random pixel sampling mechanism to enhance the robustness of visual representation and to apply the Masked Language Model and Image-Text Matching as pre-training tasks. Extensive experiments on downstream tasks with our pre-trained model show that our approach makes the most state-of-the-arts in downstream tasks, including Visual Question Answering (VQA), image-text retrieval, Natural Language for Visual Reasoning for Real (NLVR). Particularly, we boost the performance of a single model in VQA task by 2.17 points compared with SOTA under fair comparison.
Learning Rich Image Region Representation for Visual Question Answering
Oct 29, 2019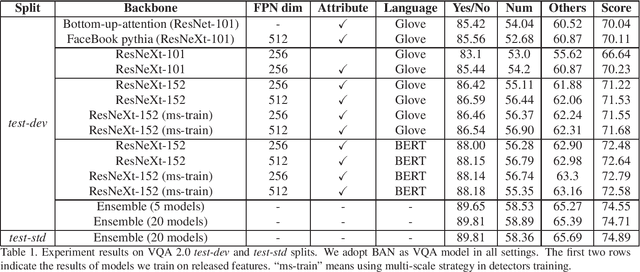
We propose to boost VQA by leveraging more powerful feature extractors by improving the representation ability of both visual and text features and the ensemble of models. For visual feature, some detection techniques are used to improve the detector. For text feature, we adopt BERT as the language model and find that it can significantly improve VQA performance. Our solution won the second place in the VQA Challenge 2019.