 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudioGuard: Toward Comprehensive Audio Safety Protection Across Diverse Threat Models
Apr 10, 2026Audio has rapidly become a primary interface for foundation models, powering real-time voice assistants. Ensuring safety in audio systems is inherently more complex than just "unsafe text spoken aloud": real-world risks can hinge on audio-native harmful sound events, speaker attributes (e.g., child voice), impersonation/voice-cloning misuse, and voice-content compositional harms, such as child voice plus sexual content. The nature of audio makes it challenging to develop comprehensive benchmarks or guardrails against this unique risk landscape. To close this gap, we conduct large-scale red teaming on audio systems, systematically uncover vulnerabilities in audio, and develop a comprehensive, policy-grounded audio risk taxonomy and AudioSafetyBench, the first policy-based audio safety benchmark across diverse threat models. AudioSafetyBench supports diverse languages, suspicious voices (e.g., celebrity/impersonation and child voice), risky voice-content combinations, and non-speech sound events. To defend against these threats, we propose AudioGuard, a unified guardrail consisting of 1) SoundGuard for waveform-level audio-native detection and 2) ContentGuard for policy-grounded semantic protection. Extensive experiments on AudioSafetyBench and four complementary benchmarks show that AudioGuard consistently improves guardrail accuracy over strong audio-LLM-based baselines with substantially lower latency.
PersonaLive! Expressive Portrait Image Animation for Live Streaming
Dec 12, 2025



Current diffusion-based portrait animation models predominantly focus on enhancing visual quality and expression realism, while overlooking generation latency and real-time performance, which restricts their application range in the live streaming scenario. We propose PersonaLive, a novel diffusion-based framework towards streaming real-time portrait animation with multi-stage training recipes. Specifically, we first adopt hybrid implicit signals, namely implicit facial representations and 3D implicit keypoints, to achieve expressive image-level motion control. Then, a fewer-step appearance distillation strategy is proposed to eliminate appearance redundancy in the denoising process, greatly improving inference efficiency. Finally, we introduce an autoregressive micro-chunk streaming generation paradigm equipped with a sliding training strategy and a historical keyframe mechanism to enable low-latency and stable long-term video generation. Extensive experiments demonstrate that PersonaLive achieves state-of-the-art performance with up to 7-22x speedup over prior diffusion-based portrait animation models.
StereoWorld: Geometry-Aware Monocular-to-Stereo Video Generation
Dec 11, 2025The growing adoption of XR devices has fueled strong demand for high-quality stereo video, yet its production remains costly and artifact-prone. To address this challenge, we present StereoWorld, an end-to-end framework that repurposes a pretrained video generator for high-fidelity monocular-to-stereo video generation. Our framework jointly conditions the model on the monocular video input while explicitly supervising the generation with a geometry-aware regularization to ensure 3D structural fidelity. A spatio-temporal tiling scheme is further integrated to enable efficient, high-resolution synthesis. To enable large-scale training and evaluation, we curate a high-definition stereo video dataset containing over 11M frames aligned to natural human interpupillary distance (IPD). Extensive experiments demonstrate that StereoWorld substantially outperforms prior methods, generating stereo videos with superior visual fidelity and geometric consistency. The project webpage is available at https://ke-xing.github.io/StereoWorld/.
Comprehensive Metapath-based Heterogeneous Graph Transformer for Gene-Disease Association Prediction
Jan 14, 2025



Discovering gene-disease associations is crucial for understanding disease mechanisms, yet identifying these associations remains challenging due to the time and cost of biological experiments. Computational methods are increasingly vital for efficient and scalable gene-disease association prediction. Graph-based learning models, which leverage node features and network relationships, are commonly employed for biomolecular predictions. However, existing methods often struggle to effectively integrate node features, heterogeneous structures, and semantic information. To address these challenges, we propose COmprehensive MEtapath-based heterogeneous graph Transformer(COMET) for predicting gene-disease associations. COMET integrates diverse datasets to construct comprehensive heterogeneous networks, initializing node features with BioGPT. We define seven Metapaths and utilize a transformer framework to aggregate Metapath instances, capturing global contexts and long-distance dependencies. Through intra- and inter-metapath aggregation using attention mechanisms, COMET fuses latent vectors from multiple Metapaths to enhance GDA prediction accuracy. Our method demonstrates superior robustness compared to state-of-the-art approaches. Ablation studies and visualizations validate COMET's effectiveness, providing valuable insights for advancing human health research.
Towards Graph Prompt Learning: A Survey and Beyond
Aug 26, 2024



Large-scale "pre-train and prompt learning" paradigms have demonstrated remarkable adaptability, enabling broad applications across diverse domains such as question answering, image recognition, and multimodal retrieval. This approach fully leverages the potential of large-scale pre-trained models, reducing downstream data requirements and computational costs while enhancing model applicability across various tasks. Graphs, as versatile data structures that capture relationships between entities, play pivotal roles in fields such as social network analysis, recommender systems, and biological graphs. Despite the success of pre-train and prompt learning paradigms in Natural Language Processing (NLP) and Computer Vision (CV), their application in graph domains remains nascent. In graph-structured data, not only do the node and edge features often have disparate distributions, but the topological structures also differ significantly. This diversity in graph data can lead to incompatible patterns or gaps between pre-training and fine-tuning on downstream graphs. We aim to bridge this gap by summarizing methods for alleviating these disparities. This includes exploring prompt design methodologies, comparing related techniques, assessing application scenarios and datasets, and identifying unresolved problems and challenges. This survey categorizes over 100 relevant works in this field, summarizing general design principles and the latest applications, including text-attributed graphs, molecules, proteins, and recommendation systems. Through this extensive review, we provide a foundational understanding of graph prompt learning, aiming to impact not only the graph mining community but also the broader Artificial General Intelligence (AGI) community.
Ada-adapter:Fast Few-shot Style Personlization of Diffusion Model with Pre-trained Image Encoder
Jul 08, 2024



Fine-tuning advanced diffusion models for high-quality image stylization usually requires large training datasets and substantial computational resources, hindering their practical applicability. We propose Ada-Adapter, a novel framework for few-shot style personalization of diffusion models. Ada-Adapter leverages off-the-shelf diffusion models and pre-trained image feature encoders to learn a compact style representation from a limited set of source images. Our method enables efficient zero-shot style transfer utilizing a single reference image. Furthermore, with a small number of source images (three to five are sufficient) and a few minutes of fine-tuning, our method can capture intricate style details and conceptual characteristics, generating high-fidelity stylized images that align well with the provided text prompts. We demonstrate the effectiveness of our approach on various artistic styles, including flat art, 3D rendering, and logo design. Our experimental results show that Ada-Adapter outperforms existing zero-shot and few-shot stylization methods in terms of output quality, diversity, and training efficiency.
Unveiling Delay Effects in Traffic Forecasting: A Perspective from Spatial-Temporal Delay Differential Equations
Feb 02, 2024



Traffic flow forecasting is a fundamental research issue for transportation planning and management, which serves as a canonical and typical example of spatial-temporal predictions. In recent years, Graph Neural Networks (GNNs) and Recurrent Neural Networks (RNNs) have achieved great success in capturing spatial-temporal correlations for traffic flow forecasting. Yet, two non-ignorable issues haven't been well solved: 1) The message passing in GNNs is immediate, while in reality the spatial message interactions among neighboring nodes can be delayed. The change of traffic flow at one node will take several minutes, i.e., time delay, to influence its connected neighbors. 2) Traffic conditions undergo continuous changes. The prediction frequency for traffic flow forecasting may vary based on specific scenario requirements. Most existing discretized models require retraining for each prediction horizon, restricting their applicability. To tackle the above issues, we propose a neural Spatial-Temporal Delay Differential Equation model, namely STDDE. It includes both delay effects and continuity into a unified delay differential equation framework, which explicitly models the time delay in spatial information propagation. Furthermore, theoretical proofs are provided to show its stability. Then we design a learnable traffic-graph time-delay estimator, which utilizes the continuity of the hidden states to achieve the gradient backward process. Finally, we propose a continuous output module, allowing us to accurately predict traffic flow at various frequencies, which provides more flexibility and adaptability to different scenarios. Extensive experiments show the superiority of the proposed STDDE along with competitive computational efficiency.
ACR: Attention Collaboration-based Regressor for Arbitrary Two-Hand Reconstruction
Mar 10, 2023



Reconstructing two hands from monocular RGB images is challenging due to frequent occlusion and mutual confusion. Existing methods mainly learn an entangled representation to encode two interacting hands, which are incredibly fragile to impaired interaction, such as truncated hands, separate hands, or external occlusion. This paper presents ACR (Attention Collaboration-based Regressor), which makes the first attempt to reconstruct hands in arbitrary scenarios. To achieve this, ACR explicitly mitigates interdependencies between hands and between parts by leveraging center and part-based attention for feature extraction. However, reducing interdependence helps release the input constraint while weakening the mutual reasoning about reconstructing the interacting hands. Thus, based on center attention, ACR also learns cross-hand prior that handle the interacting hands better. We evaluate our method on various types of hand reconstruction datasets. Our method significantly outperforms the best interacting-hand approaches on the InterHand2.6M dataset while yielding comparable performance with the state-of-the-art single-hand methods on the FreiHand dataset. More qualitative results on in-the-wild and hand-object interaction datasets and web images/videos further demonstrate the effectiveness of our approach for arbitrary hand reconstruction. Our code is available at https://github.com/ZhengdiYu/Arbitrary-Hands-3D-Reconstruction.
Instances as Queries
May 23, 2021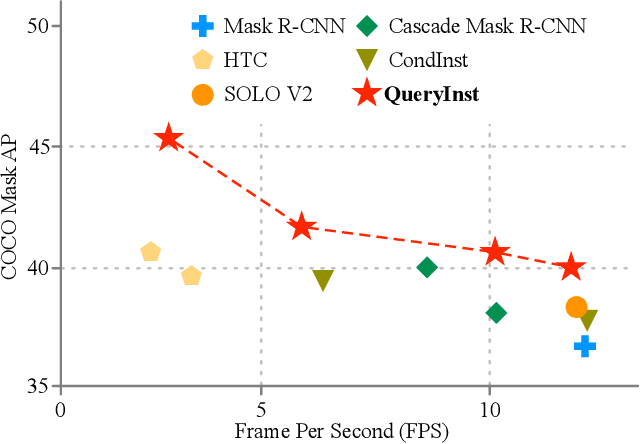
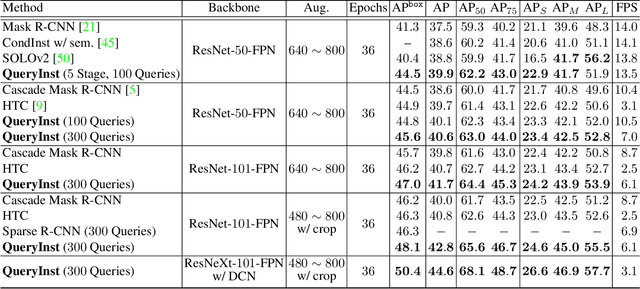
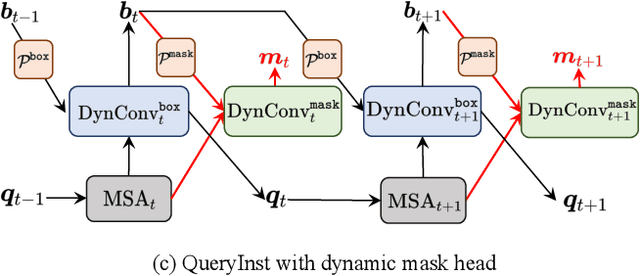

Recently, query based object detection frameworks achieve comparable performance with previous state-of-the-art object detectors. However, how to fully leverage such frameworks to perform instance segmentation remains an open problem. In this paper, we present QueryInst (Instances as Queries), a query based instance segmentation method driven by parallel supervision on dynamic mask heads. The key insight of QueryInst is to leverage the intrinsic one-to-one correspondence in object queries across different stages, as well as one-to-one correspondence between mask RoI features and object queries in the same stage. This approach eliminates the explicit multi-stage mask head connection and the proposal distribution inconsistency issues inherent in non-query based multi-stage instance segmentation methods. We conduct extensive experiments on three challenging benchmarks, i.e., COCO, CityScapes, and YouTube-VIS to evaluate the effectiveness of QueryInst in instance segmentation and video instance segmentation (VIS) task. Specifically, using ResNet-101-FPN backbone, QueryInst obtains 48.1 box AP and 42.8 mask AP on COCO test-dev, which is 2 points higher than HTC in terms of both box AP and mask AP, while runs 2.4 times faster. For video instance segmentation, QueryInst achieves the best performance among all online VIS approaches and strikes a decent speed-accuracy trade-off. Code is available at \url{https://github.com/hustvl/QueryInst}.
Crossover Learning for Fast Online Video Instance Segmentation
Apr 13, 2021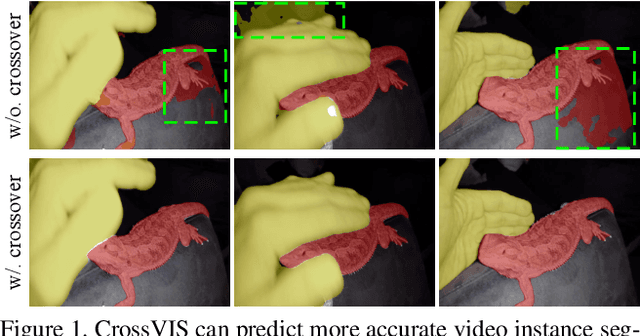
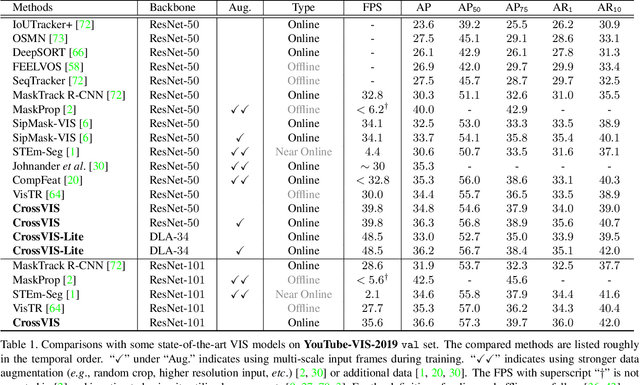
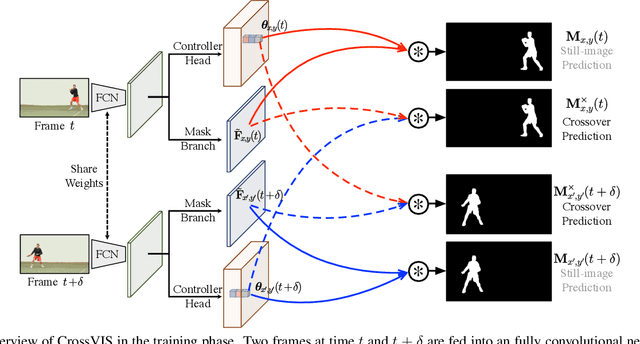
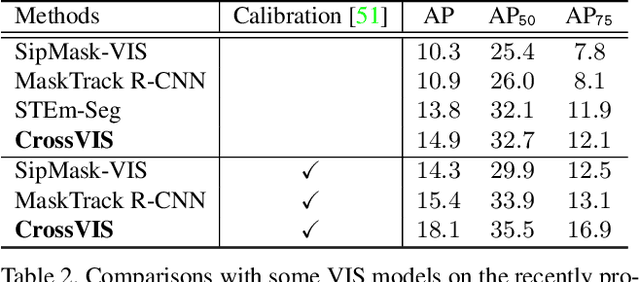
Modeling temporal visual context across frames is critical for video instance segmentation (VIS) and other video understanding tasks. In this paper, we propose a fast online VIS model named CrossVIS. For temporal information modeling in VIS, we present a novel crossover learning scheme that uses the instance feature in the current frame to pixel-wisely localize the same instance in other frames. Different from previous schemes, crossover learning does not require any additional network parameters for feature enhancement. By integrating with the instance segmentation loss, crossover learning enables efficient cross-frame instance-to-pixel relation learning and brings cost-free improvement during inference. Besides, a global balanced instance embedding branch is proposed for more accurate and more stable online instance association. We conduct extensive experiments on three challenging VIS benchmarks, \ie, YouTube-VIS-2019, OVIS, and YouTube-VIS-2021 to evaluate our methods. To our knowledge, CrossVIS achieves state-of-the-art performance among all online VIS methods and shows a decent trade-off between latency and accuracy. Code will be available to facilitate future research.