 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Diffusion Language Model Decoding through Joint Search in Generation Order and Token Space
Jan 28, 2026Diffusion Language Models (DLMs) offer order-agnostic generation that can explore many possible decoding trajectories. However, current decoding methods commit to a single trajectory, limiting exploration in trajectory space. We introduce Order-Token Search to explore this space through jointly searching over generation order and token values. Its core is a likelihood estimator that scores denoising actions, enabling stable pruning and efficient exploration of diverse trajectories. Across mathematical reasoning and coding benchmarks, Order-Token Search consistently outperforms baselines on GSM8K, MATH500, Countdown, and HumanEval (3.1%, 3.8%, 7.9%, and 6.8% absolute over backbone), matching or surpassing diffu-GRPO post-trained d1-LLaDA. Our work establishes joint search as a key component for advancing decoding in DLMs.
RelGNN: Composite Message Passing for Relational Deep Learning
Feb 10, 2025



Predictive tasks on relational databases are critical in real-world applications spanning e-commerce, healthcare, and social media. To address these tasks effectively, Relational Deep Learning (RDL) encodes relational data as graphs, enabling Graph Neural Networks (GNNs) to exploit relational structures for improved predictions. However, existing heterogeneous GNNs often overlook the intrinsic structural properties of relational databases, leading to modeling inefficiencies. Here we introduce RelGNN, a novel GNN framework specifically designed to capture the unique characteristics of relational databases. At the core of our approach is the introduction of atomic routes, which are sequences of nodes forming high-order tripartite structures. Building upon these atomic routes, RelGNN designs new composite message passing mechanisms between heterogeneous nodes, allowing direct single-hop interactions between them. This approach avoids redundant aggregations and mitigates information entanglement, ultimately leading to more efficient and accurate predictive modeling. RelGNN is evaluated on 30 diverse real-world tasks from RelBench (Fey et al., 2024), and consistently achieves state-of-the-art accuracy with up to 25% improvement.
Sequential LLM Framework for Fashion Recommendation
Oct 15, 2024



The fashion industry is one of the leading domains in the global e-commerce sector, prompting major online retailers to employ recommendation systems for product suggestions and customer convenience. While recommendation systems have been widely studied, most are designed for general e-commerce problems and struggle with the unique challenges of the fashion domain. To address these issues, we propose a sequential fashion recommendation framework that leverages a pre-trained large language model (LLM) enhanced with recommendation-specific prompts. Our framework employs parameter-efficient fine-tuning with extensive fashion data and introduces a novel mix-up-based retrieval technique for translating text into relevant product suggestions. Extensive experiments show our proposed framework significantly enhances fashion recommendation performance.
GeoMFormer: A General Architecture for Geometric Molecular Representation Learning
Jun 24, 2024Molecular modeling, a central topic in quantum mechanics, aims to accurately calculate the properties and simulate the behaviors of molecular systems. The molecular model is governed by physical laws, which impose geometric constraints such as invariance and equivariance to coordinate rotation and translation. While numerous deep learning approaches have been developed to learn molecular representations under these constraints, most of them are built upon heuristic and costly modules. We argue that there is a strong need for a general and flexible framework for learning both invariant and equivariant features. In this work, we introduce a novel Transformer-based molecular model called GeoMFormer to achieve this goal. Using the standard Transformer modules, two separate streams are developed to maintain and learn invariant and equivariant representations. Carefully designed cross-attention modules bridge the two streams, allowing information fusion and enhancing geometric modeling in each stream. As a general and flexible architecture, we show that many previous architectures can be viewed as special instantiations of GeoMFormer. Extensive experiments are conducted to demonstrate the power of GeoMFormer. All empirical results show that GeoMFormer achieves strong performance on both invariant and equivariant tasks of different types and scales. Code and models will be made publicly available at https://github.com/c-tl/GeoMFormer.
Enabling Efficient Equivariant Operations in the Fourier Basis via Gaunt Tensor Products
Jan 18, 2024


Developing equivariant neural networks for the E(3) group plays an important role in modeling 3D data across real-world applications. Enforcing this equivariance primarily involves the tensor products of irreducible representations (irreps). However, the computational complexity of such operations increases significantly as higher-order tensors are used. In this work, we propose a systematic approach to substantially accelerate the computation of the tensor products of irreps. We mathematically connect the commonly used Clebsch-Gordan coefficients to the Gaunt coefficients, which are integrals of products of three spherical harmonics. Through Gaunt coefficients, the tensor product of irreps becomes equivalent to the multiplication between spherical functions represented by spherical harmonics. This perspective further allows us to change the basis for the equivariant operations from spherical harmonics to a 2D Fourier basis. Consequently, the multiplication between spherical functions represented by a 2D Fourier basis can be efficiently computed via the convolution theorem and Fast Fourier Transforms. This transformation reduces the complexity of full tensor products of irreps from $\mathcal{O}(L^6)$ to $\mathcal{O}(L^3)$, where $L$ is the max degree of irreps. Leveraging this approach, we introduce the Gaunt Tensor Product, which serves as a new method to construct efficient equivariant operations across different model architectures. Our experiments on the Open Catalyst Project and 3BPA datasets demonstrate both the increased efficiency and improved performance of our approach.
One Transformer Can Understand Both 2D & 3D Molecular Data
Oct 04, 2022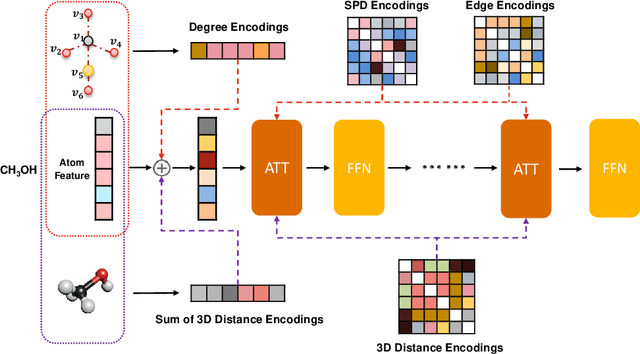
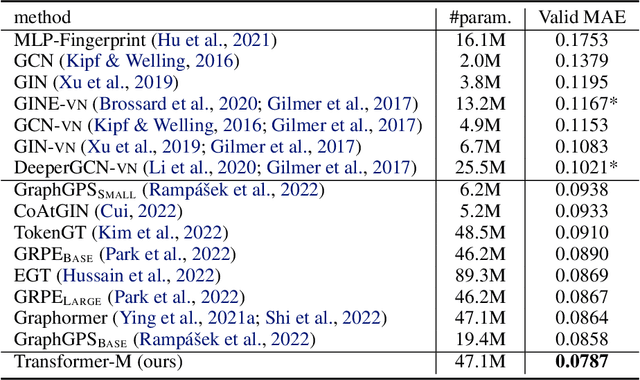
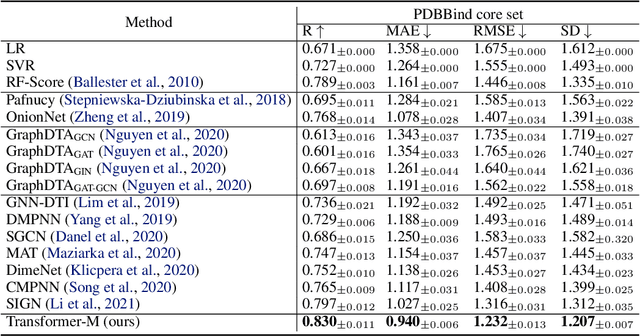
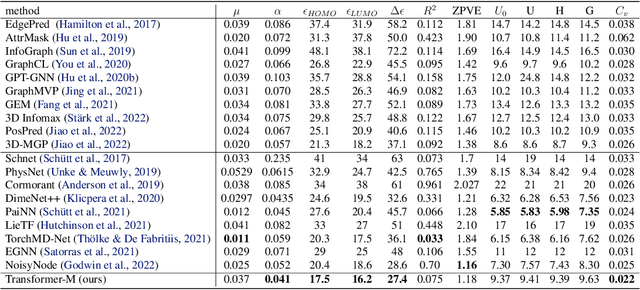
Unlike vision and language data which usually has a unique format, molecules can naturally be characterized using different chemical formulations. One can view a molecule as a 2D graph or define it as a collection of atoms located in a 3D space. For molecular representation learning, most previous works designed neural networks only for a particular data format, making the learned models likely to fail for other data formats. We believe a general-purpose neural network model for chemistry should be able to handle molecular tasks across data modalities. To achieve this goal, in this work, we develop a novel Transformer-based Molecular model called Transformer-M, which can take molecular data of 2D or 3D formats as input and generate meaningful semantic representations. Using the standard Transformer as the backbone architecture, Transformer-M develops two separated channels to encode 2D and 3D structural information and incorporate them with the atom features in the network modules. When the input data is in a particular format, the corresponding channel will be activated, and the other will be disabled. By training on 2D and 3D molecular data with properly designed supervised signals, Transformer-M automatically learns to leverage knowledge from different data modalities and correctly capture the representations. We conducted extensive experiments for Transformer-M. All empirical results show that Transformer-M can simultaneously achieve strong performance on 2D and 3D tasks, suggesting its broad applicability. The code and models will be made publicly available at https://github.com/lsj2408/Transformer-M.
TransVG++: End-to-End Visual Grounding with Language Conditioned Vision Transformer
Jun 14, 2022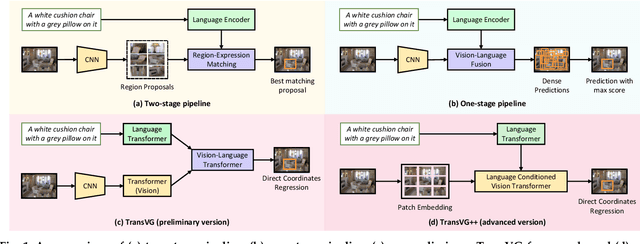
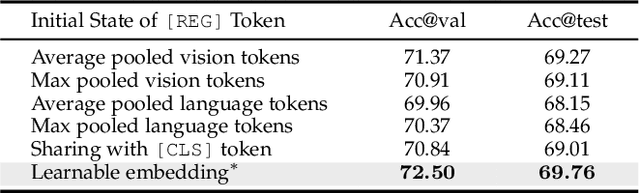
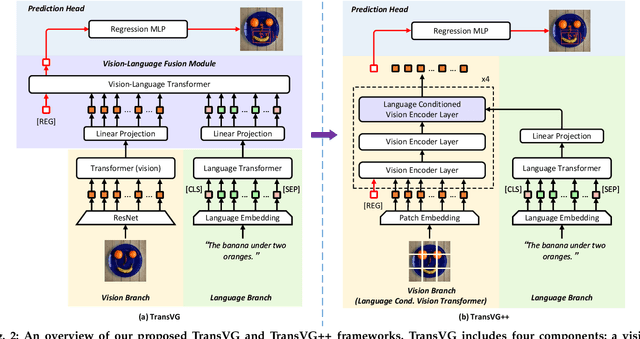
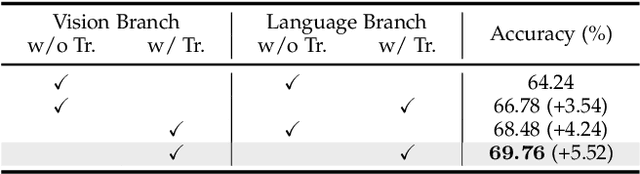
In this work, we explore neat yet effective Transformer-based frameworks for visual grounding. The previous methods generally address the core problem of visual grounding, i.e., multi-modal fusion and reasoning, with manually-designed mechanisms. Such heuristic designs are not only complicated but also make models easily overfit specific data distributions. To avoid this, we first propose TransVG, which establishes multi-modal correspondences by Transformers and localizes referred regions by directly regressing box coordinates. We empirically show that complicated fusion modules can be replaced by a simple stack of Transformer encoder layers with higher performance. However, the core fusion Transformer in TransVG is stand-alone against uni-modal encoders, and thus should be trained from scratch on limited visual grounding data, which makes it hard to be optimized and leads to sub-optimal performance. To this end, we further introduce TransVG++ to make two-fold improvements. For one thing, we upgrade our framework to a purely Transformer-based one by leveraging Vision Transformer (ViT) for vision feature encoding. For another, we devise Language Conditioned Vision Transformer that removes external fusion modules and reuses the uni-modal ViT for vision-language fusion at the intermediate layers. We conduct extensive experiments on five prevalent datasets, and report a series of state-of-the-art records.
TransVG: End-to-End Visual Grounding with Transformers
Apr 17, 2021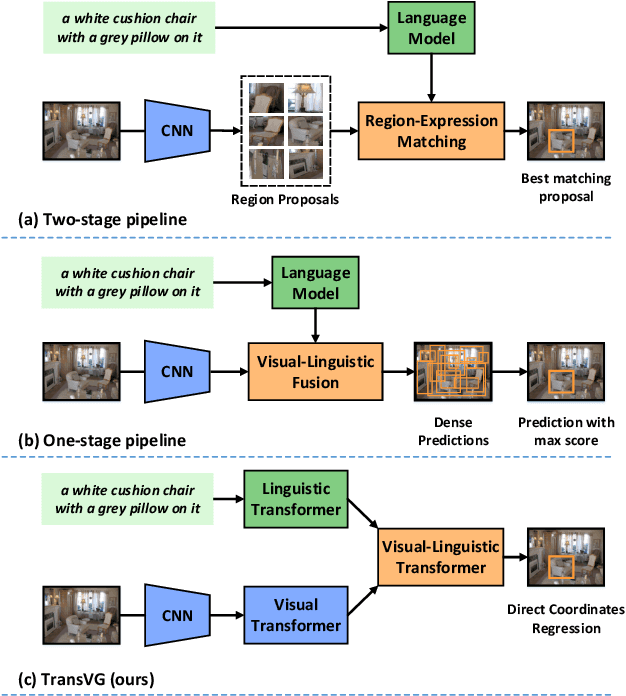
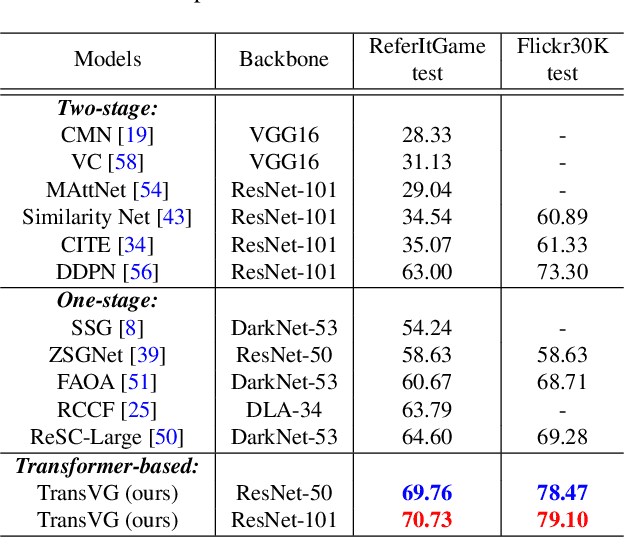
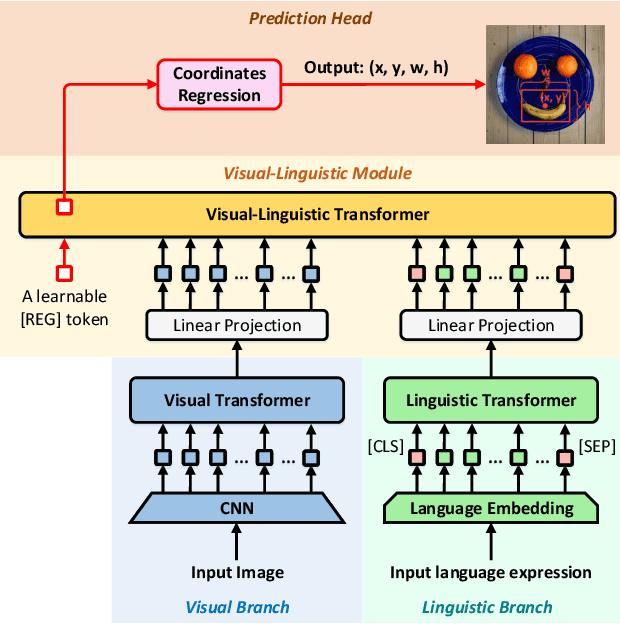
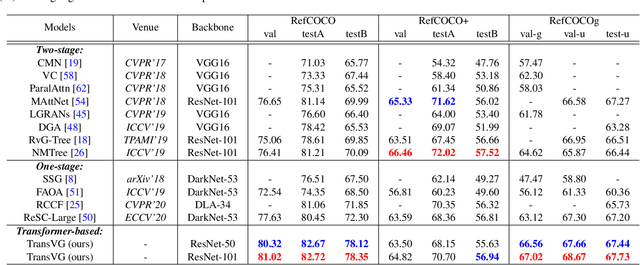
In this paper, we present a neat yet effective transformer-based framework for visual grounding, namely TransVG, to address the task of grounding a language query to the corresponding region onto an image. The state-of-the-art methods, including two-stage or one-stage ones, rely on a complex module with manually-designed mechanisms to perform the query reasoning and multi-modal fusion. However, the involvement of certain mechanisms in fusion module design, such as query decomposition and image scene graph, makes the models easily overfit to datasets with specific scenarios, and limits the plenitudinous interaction between the visual-linguistic context. To avoid this caveat, we propose to establish the multi-modal correspondence by leveraging transformers, and empirically show that the complex fusion modules (e.g., modular attention network, dynamic graph, and multi-modal tree) can be replaced by a simple stack of transformer encoder layers with higher performance. Moreover, we re-formulate the visual grounding as a direct coordinates regression problem and avoid making predictions out of a set of candidates (i.e., region proposals or anchor boxes). Extensive experiments are conducted on five widely used datasets, and a series of state-of-the-art records are set by our TransVG. We build the benchmark of transformer-based visual grounding framework and will make our code available to the public.
Improving One-stage Visual Grounding by Recursive Sub-query Construction
Aug 03, 2020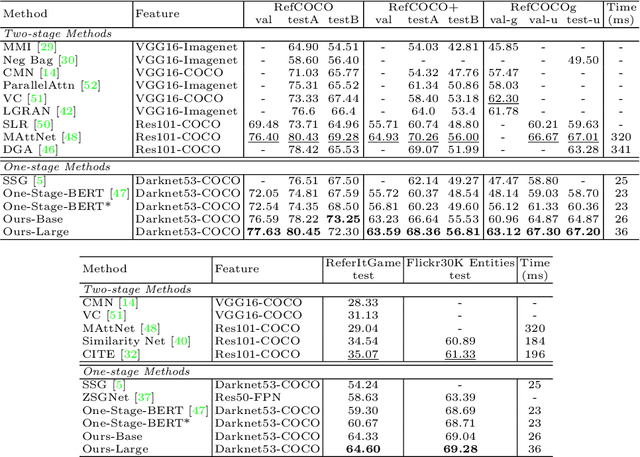

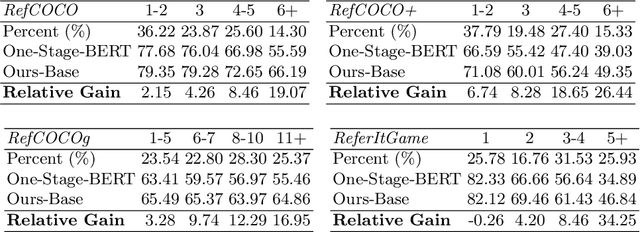
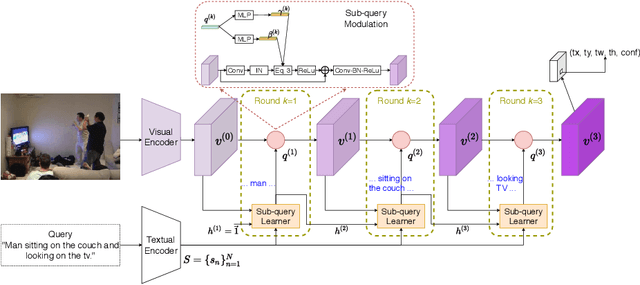
We improve one-stage visual grounding by addressing current limitations on grounding long and complex queries. Existing one-stage methods encode the entire language query as a single sentence embedding vector, e.g., taking the embedding from BERT or the hidden state from LSTM. This single vector representation is prone to overlooking the detailed descriptions in the query. To address this query modeling deficiency, we propose a recursive sub-query construction framework, which reasons between image and query for multiple rounds and reduces the referring ambiguity step by step. We show our new one-stage method obtains 5.0%, 4.5%, 7.5%, 12.8% absolute improvements over the state-of-the-art one-stage baseline on ReferItGame, RefCOCO, RefCOCO+, and RefCOCOg, respectively. In particular, superior performances on longer and more complex queries validates the effectiveness of our query modeling.
Global Image Sentiment Transfer
Jun 22, 2020
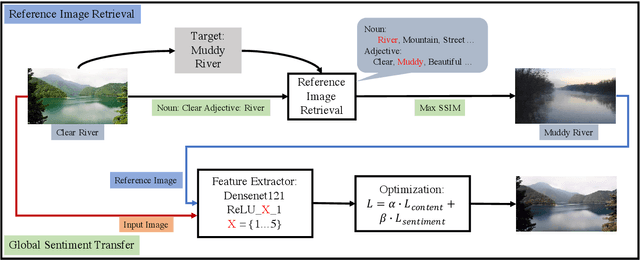

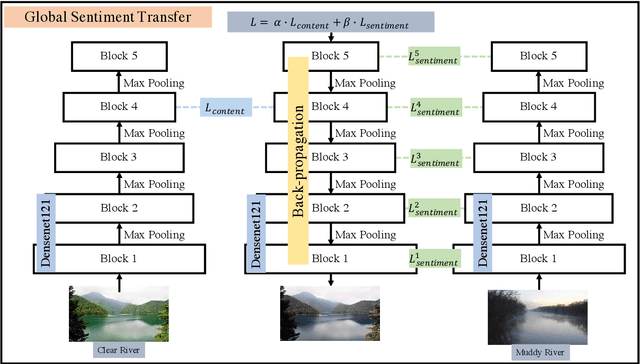
Transferring the sentiment of an image is an unexplored research topic in the area of computer vision. This work proposes a novel framework consisting of a reference image retrieval step and a global sentiment transfer step to transfer sentiments of images according to a given sentiment tag. The proposed image retrieval algorithm is based on the SSIM index. The retrieved reference images by the proposed algorithm are more content-related against the algorithm based on the perceptual loss. Therefore can lead to a better image sentiment transfer result. In addition, we propose a global sentiment transfer step, which employs an optimization algorithm to iteratively transfer sentiment of images based on feature maps produced by the Densenet121 architecture. The proposed sentiment transfer algorithm can transfer the sentiment of images while ensuring the content structure of the input image intact. The qualitative and quantitative experiments demonstrate that the proposed sentiment transfer framework outperforms existing artistic and photorealistic style transfer algorithms in making reliable sentiment transfer results with rich and exact details.