 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIGA-Stereo: Learning LiDAR Geometry Aware Representations for Stereo-based 3D Detector
Aug 18, 2021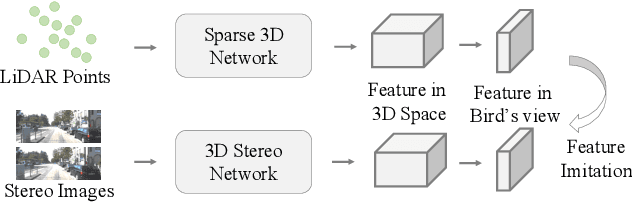
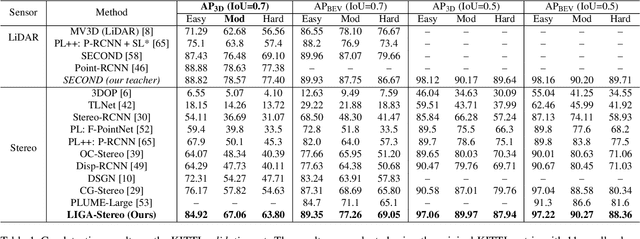
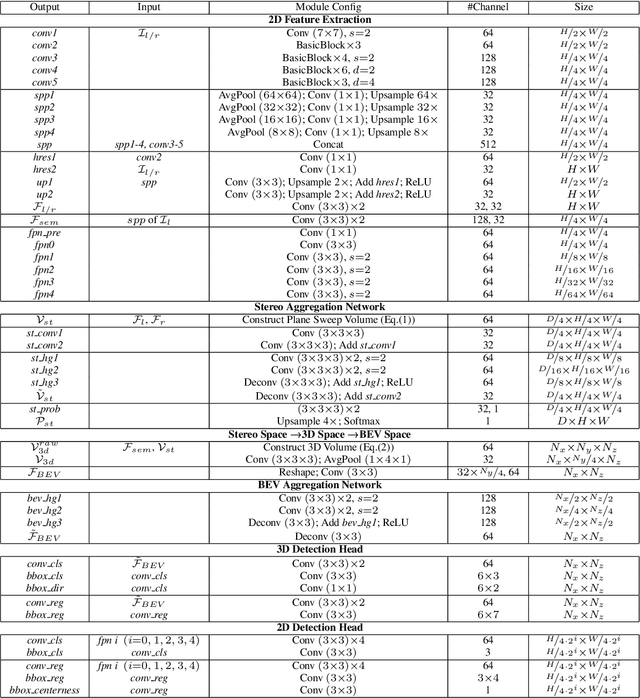
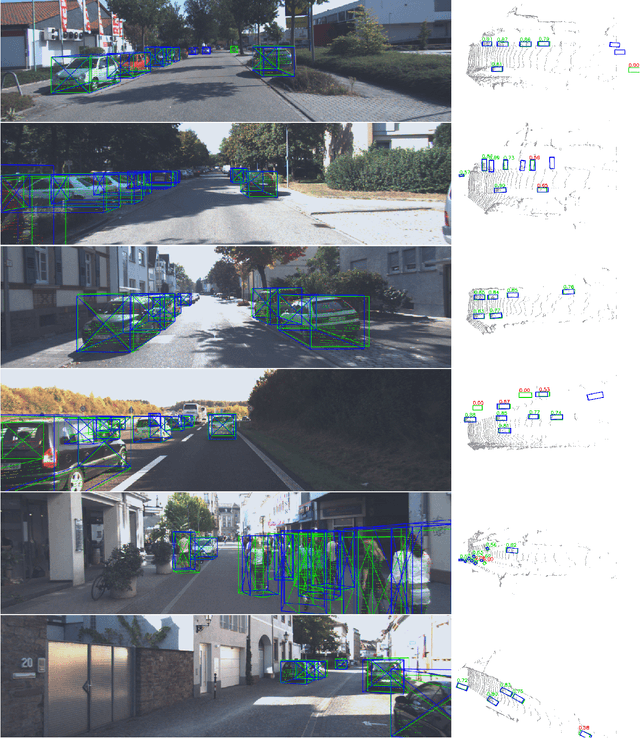
Stereo-based 3D detection aims at detecting 3D object bounding boxes from stereo images using intermediate depth maps or implicit 3D geometry representations, which provides a low-cost solution for 3D perception. However, its performance is still inferior compared with LiDAR-based detection algorithms. To detect and localize accurate 3D bounding boxes, LiDAR-based models can encode accurate object boundaries and surface normal directions from LiDAR point clouds. However, the detection results of stereo-based detectors are easily affected by the erroneous depth features due to the limitation of stereo matching. To solve the problem, we propose LIGA-Stereo (LiDAR Geometry Aware Stereo Detector) to learn stereo-based 3D detectors under the guidance of high-level geometry-aware representations of LiDAR-based detection models. In addition, we found existing voxel-based stereo detectors failed to learn semantic features effectively from indirect 3D supervisions. We attach an auxiliary 2D detection head to provide direct 2D semantic supervisions. Experiment results show that the above two strategies improved the geometric and semantic representation capabilities. Compared with the state-of-the-art stereo detector, our method has improved the 3D detection performance of cars, pedestrians, cyclists by 10.44%, 5.69%, 5.97% mAP respectively on the official KITTI benchmark. The gap between stereo-based and LiDAR-based 3D detectors is further narrowed.
Fast Convergence of DETR with Spatially Modulated Co-Attention
Aug 05, 2021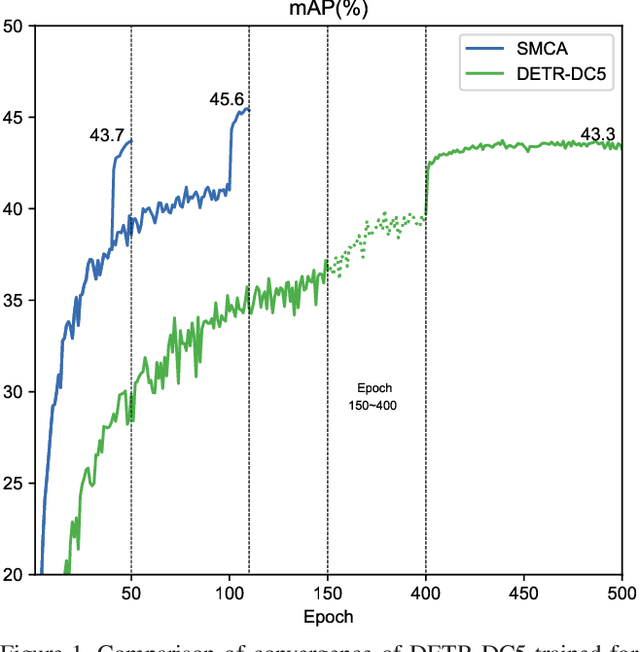
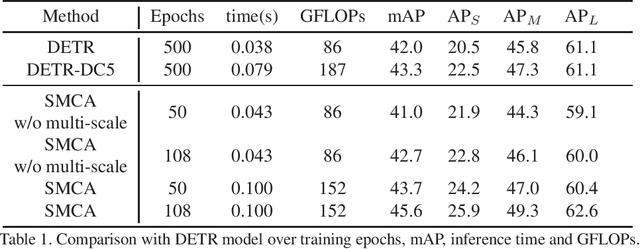
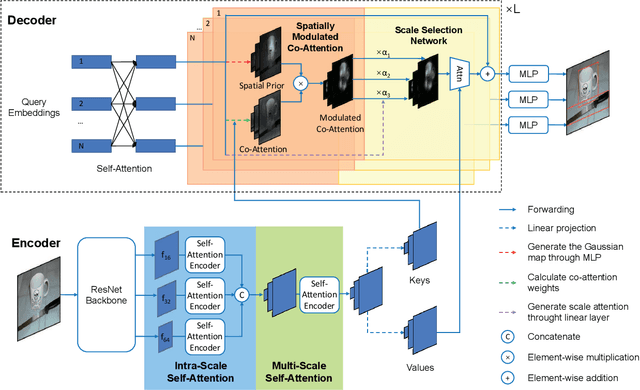
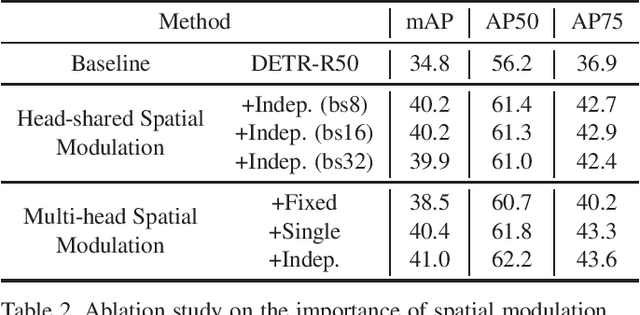
The recently proposed Detection Transformer (DETR) model successfully applies Transformer to objects detection and achieves comparable performance with two-stage object detection frameworks, such as Faster-RCNN. However, DETR suffers from its slow convergence. Training DETR from scratch needs 500 epochs to achieve a high accuracy. To accelerate its convergence, we propose a simple yet effective scheme for improving the DETR framework, namely Spatially Modulated Co-Attention (SMCA) mechanism. The core idea of SMCA is to conduct location-aware co-attention in DETR by constraining co-attention responses to be high near initially estimated bounding box locations. Our proposed SMCA increases DETR's convergence speed by replacing the original co-attention mechanism in the decoder while keeping other operations in DETR unchanged. Furthermore, by integrating multi-head and scale-selection attention designs into SMCA, our fully-fledged SMCA can achieve better performance compared to DETR with a dilated convolution-based backbone (45.6 mAP at 108 epochs vs. 43.3 mAP at 500 epochs). We perform extensive ablation studies on COCO dataset to validate SMCA. Code is released at https://github.com/gaopengcuhk/SMCA-DETR .
ReSSL: Relational Self-Supervised Learning with Weak Augmentation
Jul 23, 2021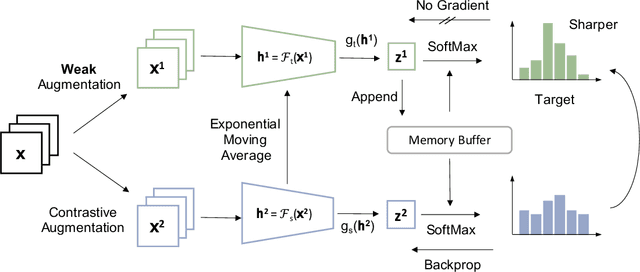
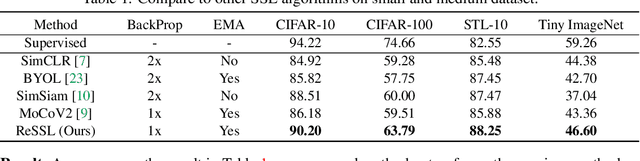
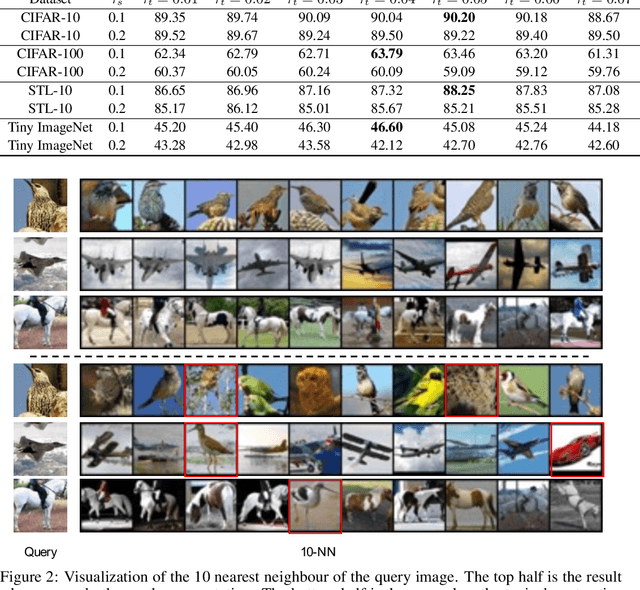
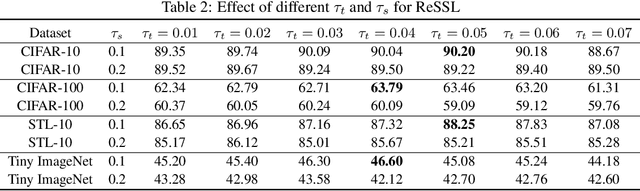
Self-supervised Learning (SSL) including the mainstream contrastive learning has achieved great success in learning visual representations without data annotations. However, most of methods mainly focus on the instance level information (\ie, the different augmented images of the same instance should have the same feature or cluster into the same class), but there is a lack of attention on the relationships between different instances. In this paper, we introduced a novel SSL paradigm, which we term as relational self-supervised learning (ReSSL) framework that learns representations by modeling the relationship between different instances. Specifically, our proposed method employs sharpened distribution of pairwise similarities among different instances as \textit{relation} metric, which is thus utilized to match the feature embeddings of different augmentations. Moreover, to boost the performance, we argue that weak augmentations matter to represent a more reliable relation, and leverage momentum strategy for practical efficiency. Experimental results show that our proposed ReSSL significantly outperforms the previous state-of-the-art algorithms in terms of both performance and training efficiency. Code is available at \url{https://github.com/KyleZheng1997/ReSSL}.
Vision Transformer Architecture Search
Jun 25, 2021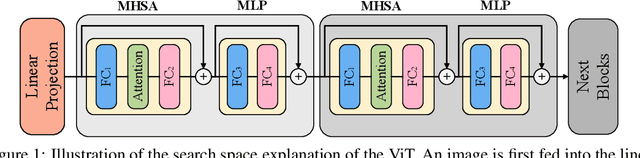

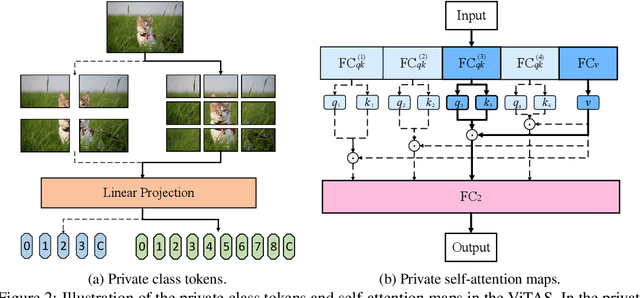

Recently, transformers have shown great superiority in solving computer vision tasks by modeling images as a sequence of manually-split patches with self-attention mechanism. However, current architectures of vision transformers (ViTs) are simply inherited from natural language processing (NLP) tasks and have not been sufficiently investigated and optimized. In this paper, we make a further step by examining the intrinsic structure of transformers for vision tasks and propose an architecture search method, dubbed ViTAS, to search for the optimal architecture with similar hardware budgets. Concretely, we design a new effective yet efficient weight sharing paradigm for ViTs, such that architectures with different token embedding, sequence size, number of heads, width, and depth can be derived from a single super-transformer. Moreover, to cater for the variance of distinct architectures, we introduce \textit{private} class token and self-attention maps in the super-transformer. In addition, to adapt the searching for different budgets, we propose to search the sampling probability of identity operation. Experimental results show that our ViTAS attains excellent results compared to existing pure transformer architectures. For example, with $1.3$G FLOPs budget, our searched architecture achieves $74.7\%$ top-$1$ accuracy on ImageNet and is $2.5\%$ superior than the current baseline ViT architecture. Code is available at \url{https://github.com/xiusu/ViTAS}.
Scalable Transformers for Neural Machine Translation
Jun 18, 2021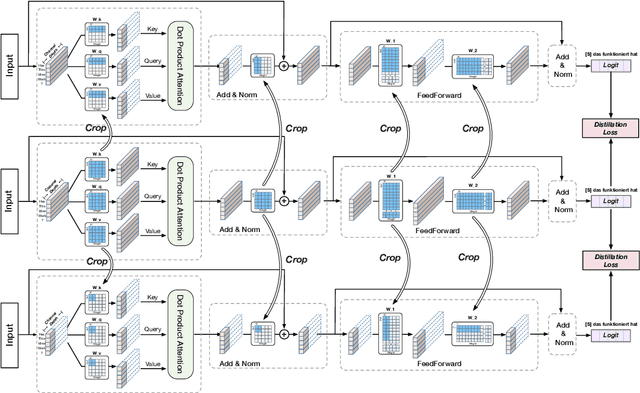
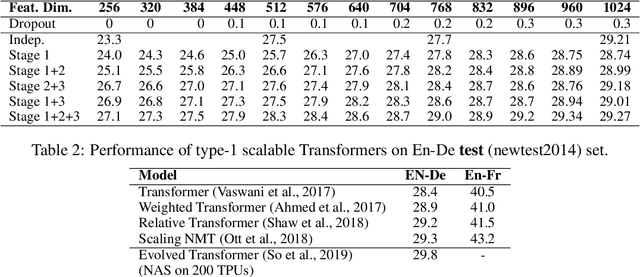
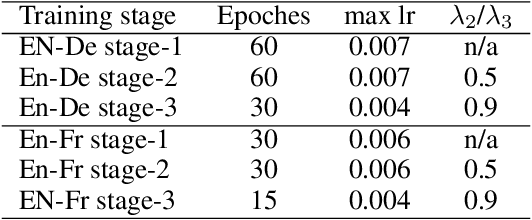
Transformer has been widely adopted in Neural Machine Translation (NMT) because of its large capacity and parallel training of sequence generation. However, the deployment of Transformer is challenging because different scenarios require models of different complexities and scales. Naively training multiple Transformers is redundant in terms of both computation and memory. In this paper, we propose a novel Scalable Transformers, which naturally contains sub-Transformers of different scales and have shared parameters. Each sub-Transformer can be easily obtained by cropping the parameters of the largest Transformer. A three-stage training scheme is proposed to tackle the difficulty of training the Scalable Transformers, which introduces additional supervisions from word-level and sequence-level self-distillation. Extensive experiments were conducted on WMT EN-De and En-Fr to validate our proposed Scalable Transformers.
ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search
May 21, 2021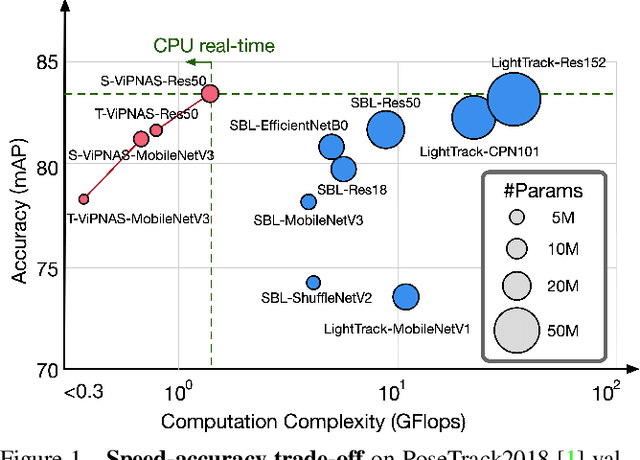
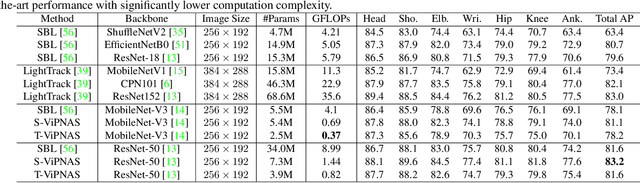
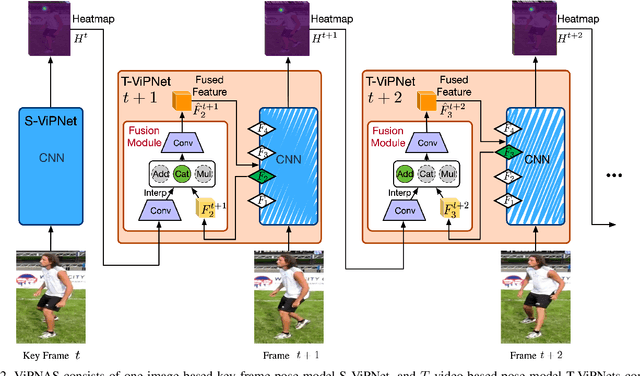
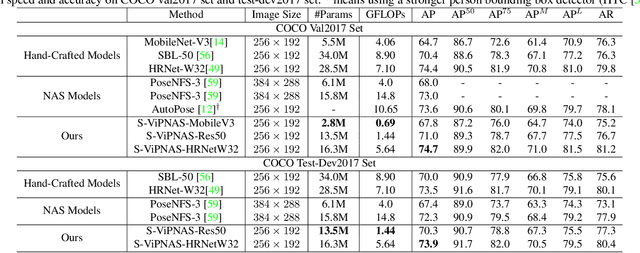
Human pose estimation has achieved significant progress in recent years. However, most of the recent methods focus on improving accuracy using complicated models and ignoring real-time efficiency. To achieve a better trade-off between accuracy and efficiency, we propose a novel neural architecture search (NAS) method, termed ViPNAS, to search networks in both spatial and temporal levels for fast online video pose estimation. In the spatial level, we carefully design the search space with five different dimensions including network depth, width, kernel size, group number, and attentions. In the temporal level, we search from a series of temporal feature fusions to optimize the total accuracy and speed across multiple video frames. To the best of our knowledge, we are the first to search for the temporal feature fusion and automatic computation allocation in videos. Extensive experiments demonstrate the effectiveness of our approach on the challenging COCO2017 and PoseTrack2018 datasets. Our discovered model family, S-ViPNAS and T-ViPNAS, achieve significantly higher inference speed (CPU real-time) without sacrificing the accuracy compared to the previous state-of-the-art methods.
Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation
Apr 22, 2021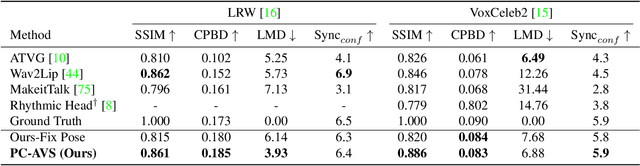
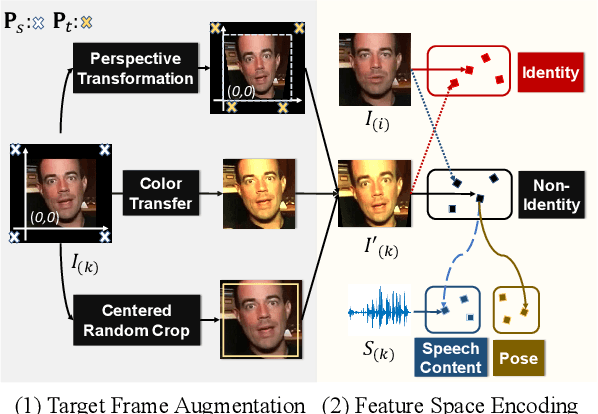

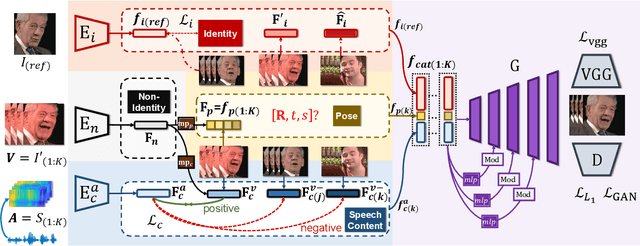
While accurate lip synchronization has been achieved for arbitrary-subject audio-driven talking face generation, the problem of how to efficiently drive the head pose remains. Previous methods rely on pre-estimated structural information such as landmarks and 3D parameters, aiming to generate personalized rhythmic movements. However, the inaccuracy of such estimated information under extreme conditions would lead to degradation problems. In this paper, we propose a clean yet effective framework to generate pose-controllable talking faces. We operate on raw face images, using only a single photo as an identity reference. The key is to modularize audio-visual representations by devising an implicit low-dimension pose code. Substantially, both speech content and head pose information lie in a joint non-identity embedding space. While speech content information can be defined by learning the intrinsic synchronization between audio-visual modalities, we identify that a pose code will be complementarily learned in a modulated convolution-based reconstruction framework. Extensive experiments show that our method generates accurately lip-synced talking faces whose poses are controllable by other videos. Moreover, our model has multiple advanced capabilities including extreme view robustness and talking face frontalization. Code, models, and demo videos are available at https://hangz-nju-cuhk.github.io/projects/PC-AVS.
Decoupled Spatial-Temporal Transformer for Video Inpainting
Apr 14, 2021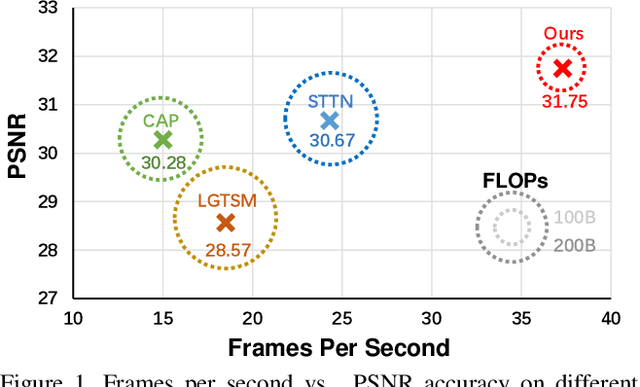
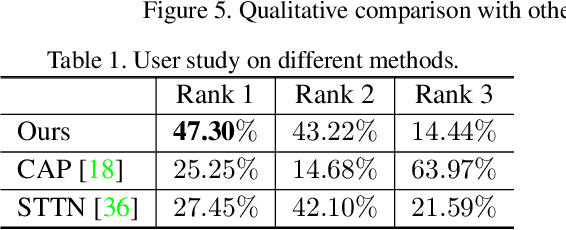

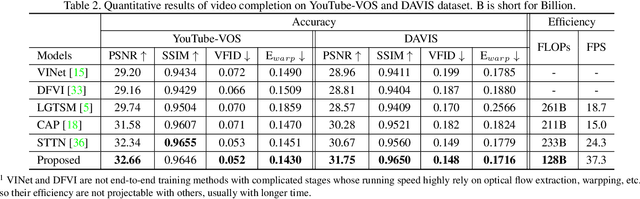
Video inpainting aims to fill the given spatiotemporal holes with realistic appearance but is still a challenging task even with prosperous deep learning approaches. Recent works introduce the promising Transformer architecture into deep video inpainting and achieve better performance. However, it still suffers from synthesizing blurry texture as well as huge computational cost. Towards this end, we propose a novel Decoupled Spatial-Temporal Transformer (DSTT) for improving video inpainting with exceptional efficiency. Our proposed DSTT disentangles the task of learning spatial-temporal attention into 2 sub-tasks: one is for attending temporal object movements on different frames at same spatial locations, which is achieved by temporally-decoupled Transformer block, and the other is for attending similar background textures on same frame of all spatial positions, which is achieved by spatially-decoupled Transformer block. The interweaving stack of such two blocks makes our proposed model attend background textures and moving objects more precisely, and thus the attended plausible and temporally-coherent appearance can be propagated to fill the holes. In addition, a hierarchical encoder is adopted before the stack of Transformer blocks, for learning robust and hierarchical features that maintain multi-level local spatial structure, resulting in the more representative token vectors. Seamless combination of these two novel designs forms a better spatial-temporal attention scheme and our proposed model achieves better performance than state-of-the-art video inpainting approaches with significant boosted efficiency.
Visually Informed Binaural Audio Generation without Binaural Audios
Apr 13, 2021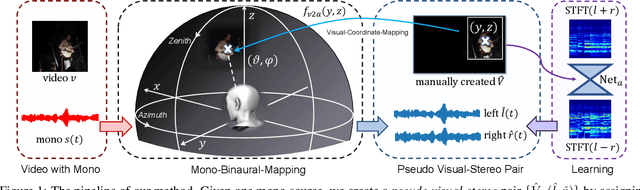
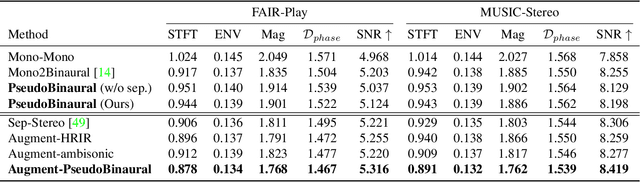
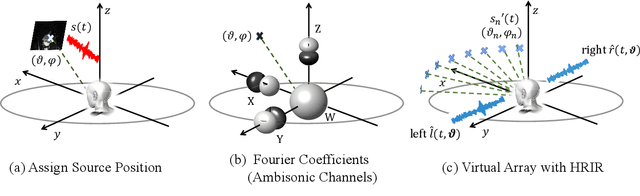

Stereophonic audio, especially binaural audio, plays an essential role in immersive viewing environments. Recent research has explored generating visually guided stereophonic audios supervised by multi-channel audio collections. However, due to the requirement of professional recording devices, existing datasets are limited in scale and variety, which impedes the generalization of supervised methods in real-world scenarios. In this work, we propose PseudoBinaural, an effective pipeline that is free of binaural recordings. The key insight is to carefully build pseudo visual-stereo pairs with mono data for training. Specifically, we leverage spherical harmonic decomposition and head-related impulse response (HRIR) to identify the relationship between spatial locations and received binaural audios. Then in the visual modality, corresponding visual cues of the mono data are manually placed at sound source positions to form the pairs. Compared to fully-supervised paradigms, our binaural-recording-free pipeline shows great stability in cross-dataset evaluation and achieves comparable performance under subjective preference. Moreover, combined with binaural recordings, our method is able to further boost the performance of binaural audio generation under supervised settings.
Semantic Scene Completion via Integrating Instances and Scene in-the-Loop
Apr 08, 2021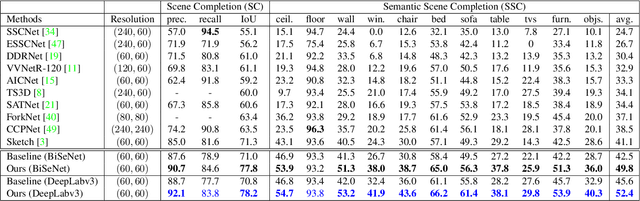

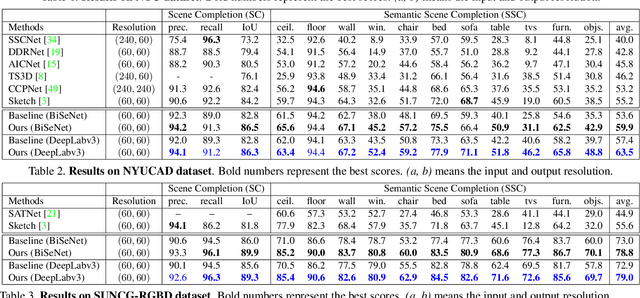
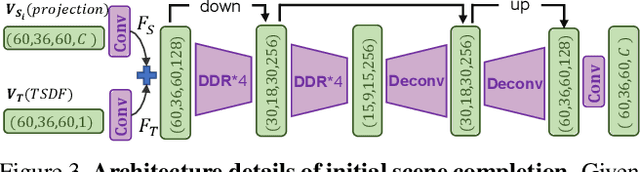
Semantic Scene Completion aims at reconstructing a complete 3D scene with precise voxel-wise semantics from a single-view depth or RGBD image. It is a crucial but challenging problem for indoor scene understanding. In this work, we present a novel framework named Scene-Instance-Scene Network (\textit{SISNet}), which takes advantages of both instance and scene level semantic information. Our method is capable of inferring fine-grained shape details as well as nearby objects whose semantic categories are easily mixed-up. The key insight is that we decouple the instances from a coarsely completed semantic scene instead of a raw input image to guide the reconstruction of instances and the overall scene. SISNet conducts iterative scene-to-instance (SI) and instance-to-scene (IS) semantic completion. Specifically, the SI is able to encode objects' surrounding context for effectively decoupling instances from the scene and each instance could be voxelized into higher resolution to capture finer details. With IS, fine-grained instance information can be integrated back into the 3D scene and thus leads to more accurate semantic scene completion. Utilizing such an iterative mechanism, the scene and instance completion benefits each other to achieve higher completion accuracy. Extensively experiments show that our proposed method consistently outperforms state-of-the-art methods on both real NYU, NYUCAD and synthetic SUNCG-RGBD datasets. The code and the supplementary material will be available at \url{https://github.com/yjcaimeow/SISNet}.