 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKPNet: Towards Minimal Face Detector
Mar 17, 2020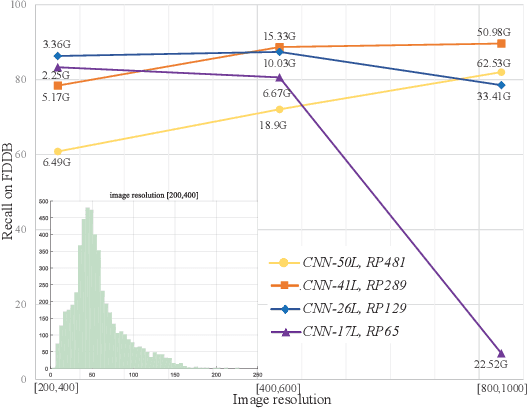

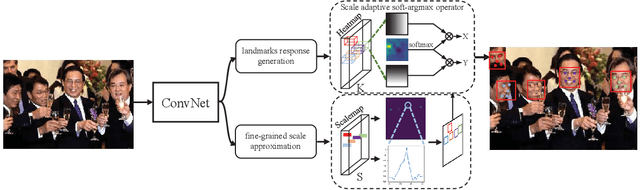
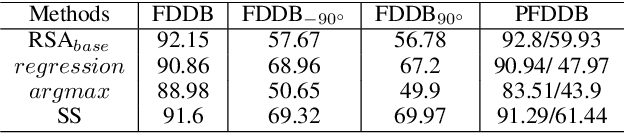
The small receptive field and capacity of minimal neural networks limit their performance when using them to be the backbone of detectors. In this work, we find that the appearance feature of a generic face is discriminative enough for a tiny and shallow neural network to verify from the background. And the essential barriers behind us are 1) the vague definition of the face bounding box and 2) tricky design of anchor-boxes or receptive field. Unlike most top-down methods for joint face detection and alignment, the proposed KPNet detects small facial keypoints instead of the whole face by in a bottom-up manner. It first predicts the facial landmarks from a low-resolution image via the well-designed fine-grained scale approximation and scale adaptive soft-argmax operator. Finally, the precise face bounding boxes, no matter how we define it, can be inferred from the keypoints. Without any complex head architecture or meticulous network designing, the KPNet achieves state-of-the-art accuracy on generic face detection and alignment benchmarks with only $\sim1M$ parameters, which runs at 1000fps on GPU and is easy to perform real-time on most modern front-end chips.
Revisiting the Sibling Head in Object Detector
Mar 17, 2020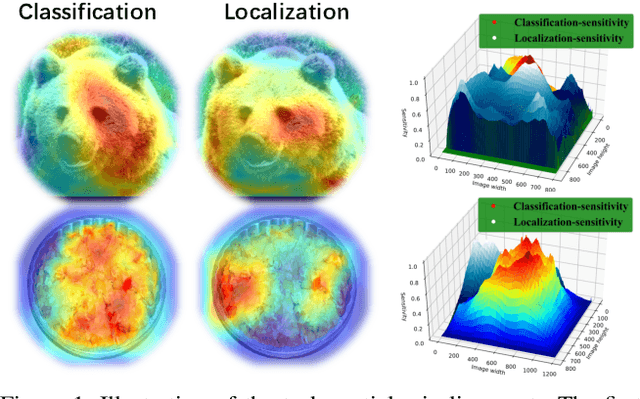
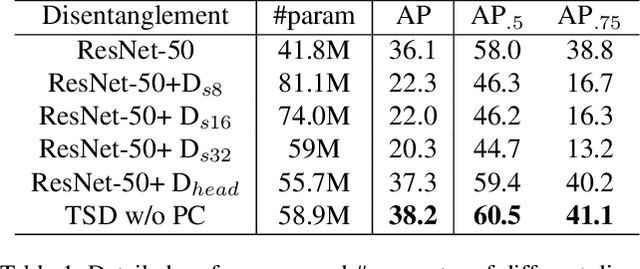
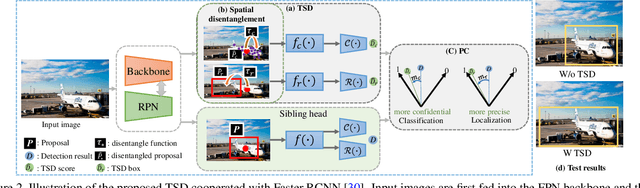

The ``shared head for classification and localization'' (sibling head), firstly denominated in Fast RCNN~\cite{girshick2015fast}, has been leading the fashion of the object detection community in the past five years. This paper provides the observation that the spatial misalignment between the two object functions in the sibling head can considerably hurt the training process, but this misalignment can be resolved by a very simple operator called task-aware spatial disentanglement (TSD). Considering the classification and regression, TSD decouples them from the spatial dimension by generating two disentangled proposals for them, which are estimated by the shared proposal. This is inspired by the natural insight that for one instance, the features in some salient area may have rich information for classification while these around the boundary may be good at bounding box regression. Surprisingly, this simple design can boost all backbones and models on both MS COCO and Google OpenImage consistently by ~3% mAP. Further, we propose a progressive constraint to enlarge the performance margin between the disentangled and the shared proposals, and gain ~1% more mAP. We show the \algname{} breaks through the upper bound of nowadays single-model detector by a large margin (mAP 49.4 with ResNet-101, 51.2 with SENet154), and is the core model of our 1st place solution on the Google OpenImage Challenge 2019.
Adapting Object Detectors with Conditional Domain Normalization
Mar 16, 2020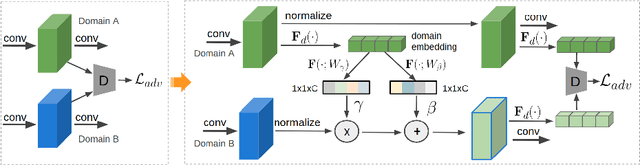
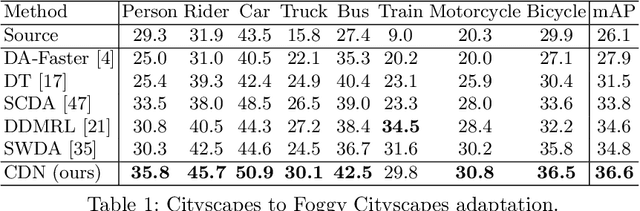
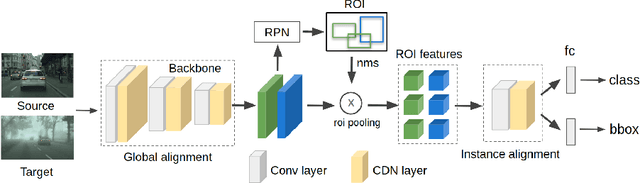
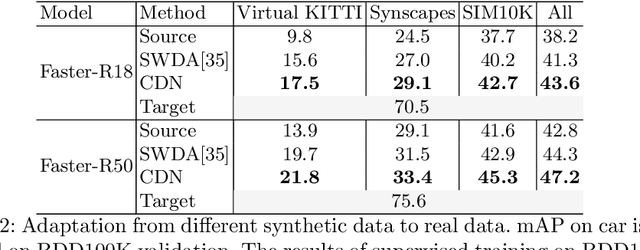
Real-world object detectors are often challenged by the domain gaps between different datasets. In this work, we present the Conditional Domain Normalization (CDN) to bridge the domain gap. CDN is designed to encode different domain inputs into a shared latent space, where the features from different domains carry the same domain attribute. To achieve this, we first disentangle the domain-specific attribute out of the semantic features from one domain via a domain embedding module, which learns a domain-vector to characterize the corresponding domain attribute information. Then this domain-vector is used to encode the features from another domain through a conditional normalization, resulting in different domains' features carrying the same domain attribute. We incorporate CDN into various convolution stages of an object detector to adaptively address the domain shifts of different level's representation. In contrast to existing adaptation works that conduct domain confusion learning on semantic features to remove domain-specific factors, CDN aligns different domain distributions by modulating the semantic features of one domain conditioned on the learned domain-vector of another domain. Extensive experiments show that CDN outperforms existing methods remarkably on both real-to-real and synthetic-to-real adaptation benchmarks, including 2D image detection and 3D point cloud detection.
Channel Equilibrium Networks for Learning Deep Representation
Feb 29, 2020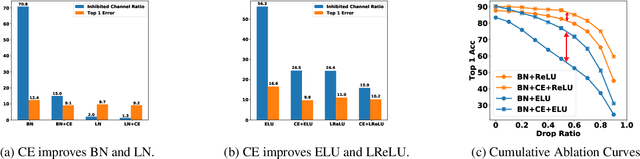
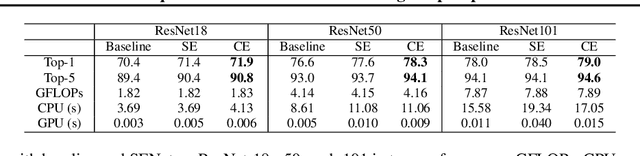
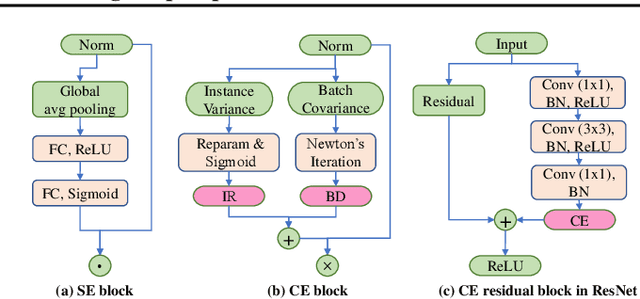
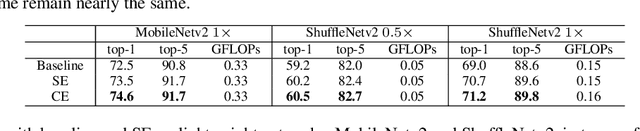
Convolutional Neural Networks (CNNs) are typically constructed by stacking multiple building blocks, each of which contains a normalization layer such as batch normalization (BN) and a rectified linear function such as ReLU. However, this work shows that the combination of normalization and rectified linear function leads to inhibited channels, which have small magnitude and contribute little to the learned feature representation, impeding the generalization ability of CNNs. Unlike prior arts that simply removed the inhibited channels, we propose to "wake them up" during training by designing a novel neural building block, termed Channel Equilibrium (CE) block, which enables channels at the same layer to contribute equally to the learned representation. We show that CE is able to prevent inhibited channels both empirically and theoretically. CE has several appealing benefits. (1) It can be integrated into many advanced CNN architectures such as ResNet and MobileNet, outperforming their original networks. (2) CE has an interesting connection with the Nash Equilibrium, a well-known solution of a non-cooperative game. (3) Extensive experiments show that CE achieves state-of-the-art performance on various challenging benchmarks such as ImageNet and COCO.
Monocular 3D Object Detection with Decoupled Structured Polygon Estimation and Height-Guided Depth Estimation
Feb 05, 2020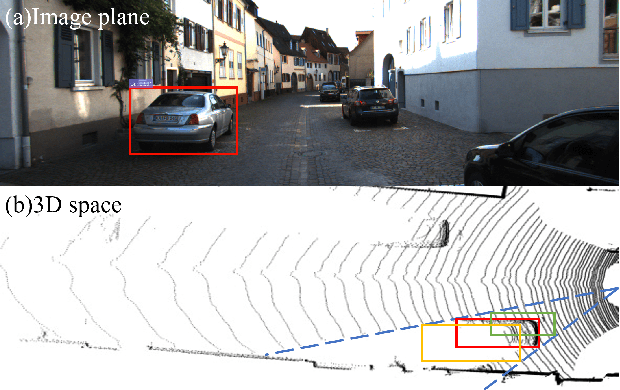
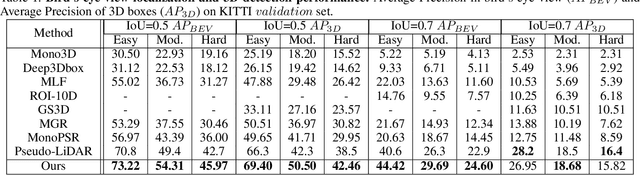
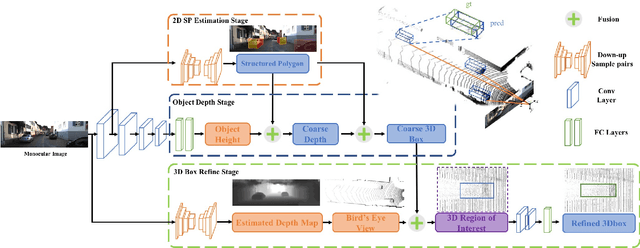
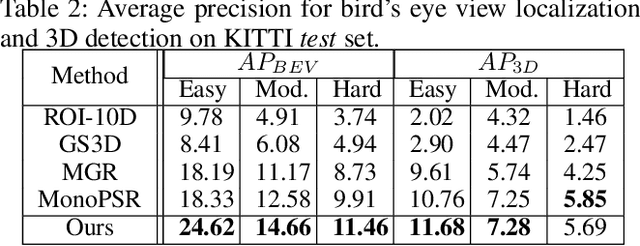
Monocular 3D object detection task aims to predict the 3D bounding boxes of objects based on monocular RGB images. Since the location recovery in 3D space is quite difficult on account of absence of depth information, this paper proposes a novel unified framework which decomposes the detection problem into a structured polygon prediction task and a depth recovery task. Different from the widely studied 2D bounding boxes, the proposed novel structured polygon in the 2D image consists of several projected surfaces of the target object. Compared to the widely-used 3D bounding box proposals, it is shown to be a better representation for 3D detection. In order to inversely project the predicted 2D structured polygon to a cuboid in the 3D physical world, the following depth recovery task uses the object height prior to complete the inverse projection transformation with the given camera projection matrix. Moreover, a fine-grained 3D box refinement scheme is proposed to further rectify the 3D detection results. Experiments are conducted on the challenging KITTI benchmark, in which our method achieves state-of-the-art detection accuracy.
Single Image Dehazing Using Ranking Convolutional Neural Network
Jan 15, 2020
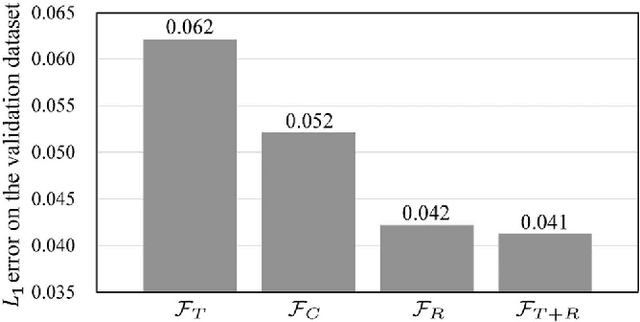
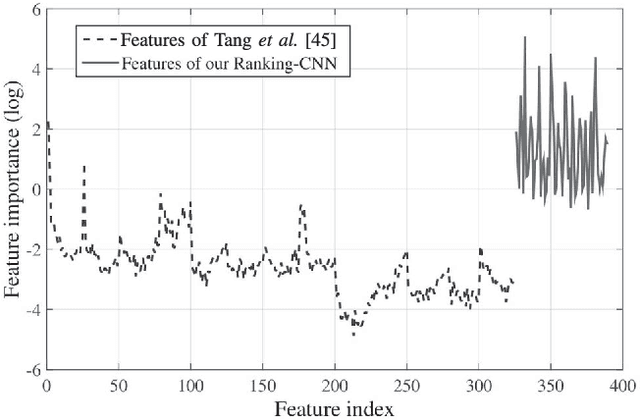
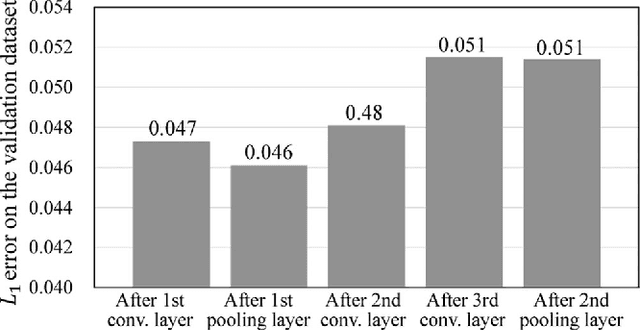
Single image dehazing, which aims to recover the clear image solely from an input hazy or foggy image, is a challenging ill-posed problem. Analysing existing approaches, the common key step is to estimate the haze density of each pixel. To this end, various approaches often heuristically designed haze-relevant features. Several recent works also automatically learn the features via directly exploiting Convolutional Neural Networks (CNN). However, it may be insufficient to fully capture the intrinsic attributes of hazy images. To obtain effective features for single image dehazing, this paper presents a novel Ranking Convolutional Neural Network (Ranking-CNN). In Ranking-CNN, a novel ranking layer is proposed to extend the structure of CNN so that the statistical and structural attributes of hazy images can be simultaneously captured. By training Ranking-CNN in a well-designed manner, powerful haze-relevant features can be automatically learned from massive hazy image patches. Based on these features, haze can be effectively removed by using a haze density prediction model trained through the random forest regression. Experimental results show that our approach outperforms several previous dehazing approaches on synthetic and real-world benchmark images. Comprehensive analyses are also conducted to interpret the proposed Ranking-CNN from both the theoretical and experimental aspects.
PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection
Dec 31, 2019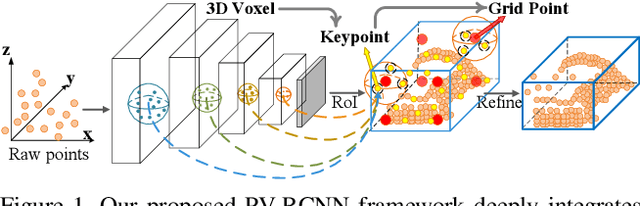
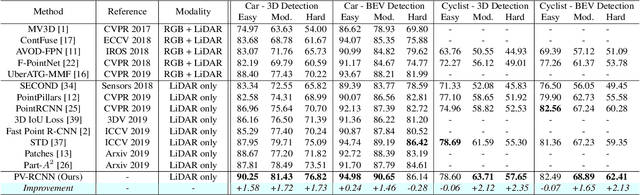
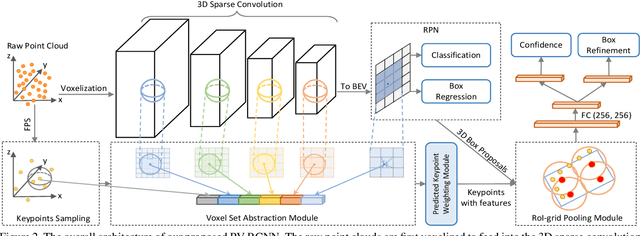
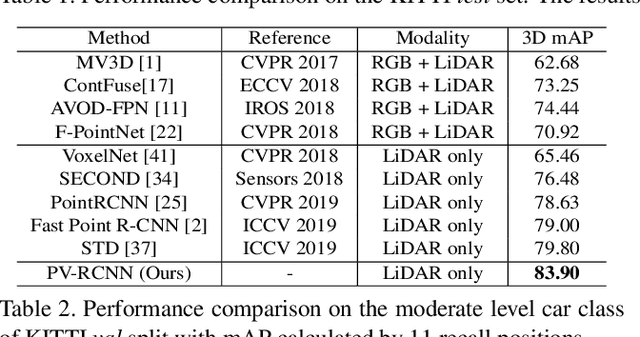
We present a novel and high-performance 3D object detection framework, named PointVoxel-RCNN (PV-RCNN), for accurate 3D object detection from point clouds. Our proposed method deeply integrates both 3D voxel Convolutional Neural Network (CNN) and PointNet-based set abstraction to learn more discriminative point cloud features. It takes advantages of efficient learning and high-quality proposals of the 3D voxel CNN and the flexible receptive fields of the PointNet-based networks. Specifically, the proposed framework summarizes the 3D scene with a 3D voxel CNN into a small set of keypoints via a novel voxel set abstraction module to save follow-up computations and also to encode representative scene features. Given the high-quality 3D proposals generated by the voxel CNN, the RoI-grid pooling is proposed to abstract proposal-specific features from the keypoints to the RoI-grid points via keypoint set abstraction with multiple receptive fields. Compared with conventional pooling operations, the RoI-grid feature points encode much richer context information for accurately estimating object confidences and locations. Extensive experiments on both the KITTI dataset and the Waymo Open dataset show that our proposed PV-RCNN surpasses state-of-the-art 3D detection methods with remarkable margins by using only point clouds.
Search to Distill: Pearls are Everywhere but not the Eyes
Nov 20, 2019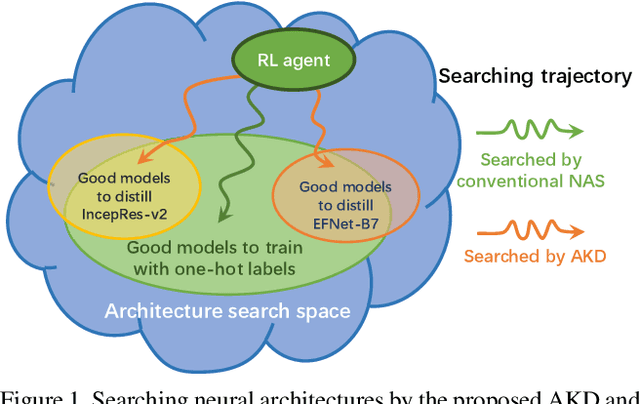
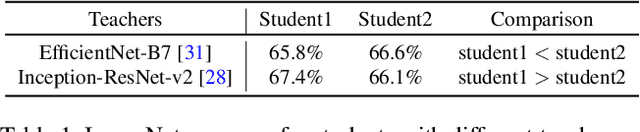
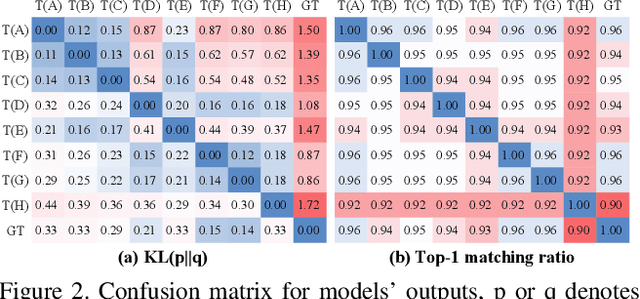
Standard Knowledge Distillation (KD) approaches distill the knowledge of a cumbersome teacher model into the parameters of a student model with a pre-defined architecture. However, the knowledge of a neural network, which is represented by the network's output distribution conditioned on its input, depends not only on its parameters but also on its architecture. Hence, a more generalized approach for KD is to distill the teacher's knowledge into both the parameters and architecture of the student. To achieve this, we present a new Architecture-aware Knowledge Distillation (AKD) approach that finds student models (pearls for the teacher) that are best for distilling the given teacher model. In particular, we leverage Neural Architecture Search (NAS), equipped with our KD-guided reward, to search for the best student architectures for a given teacher. Experimental results show our proposed AKD consistently outperforms the conventional NAS plus KD approach, and achieves state-of-the-art results on the ImageNet classification task under various latency settings. Furthermore, the best AKD student architecture for the ImageNet classification task also transfers well to other tasks such as million level face recognition and ensemble learning.
Vision-Infused Deep Audio Inpainting
Oct 24, 2019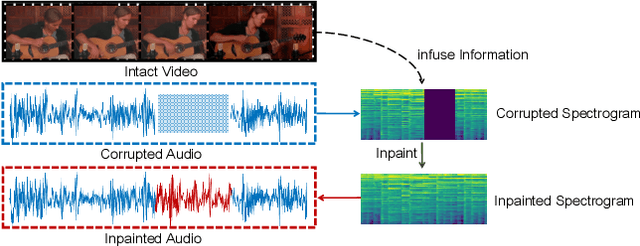

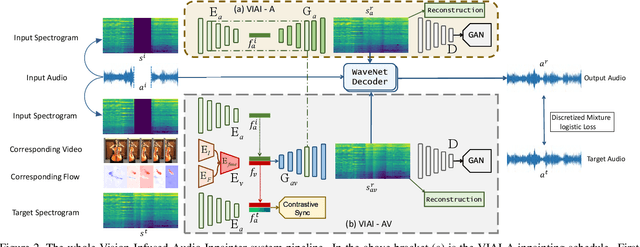
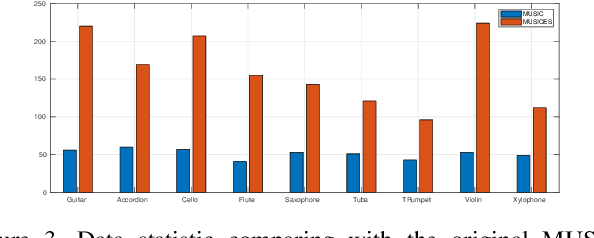
Multi-modality perception is essential to develop interactive intelligence. In this work, we consider a new task of visual information-infused audio inpainting, \ie synthesizing missing audio segments that correspond to their accompanying videos. We identify two key aspects for a successful inpainter: (1) It is desirable to operate on spectrograms instead of raw audios. Recent advances in deep semantic image inpainting could be leveraged to go beyond the limitations of traditional audio inpainting. (2) To synthesize visually indicated audio, a visual-audio joint feature space needs to be learned with synchronization of audio and video. To facilitate a large-scale study, we collect a new multi-modality instrument-playing dataset called MUSIC-Extra-Solo (MUSICES) by enriching MUSIC dataset. Extensive experiments demonstrate that our framework is capable of inpainting realistic and varying audio segments with or without visual contexts. More importantly, our synthesized audio segments are coherent with their video counterparts, showing the effectiveness of our proposed Vision-Infused Audio Inpainter (VIAI). Code, models, dataset and video results are available at https://hangz-nju-cuhk.github.io/projects/AudioInpainting
Learning to Predict Layout-to-image Conditional Convolutions for Semantic Image Synthesis
Oct 16, 2019
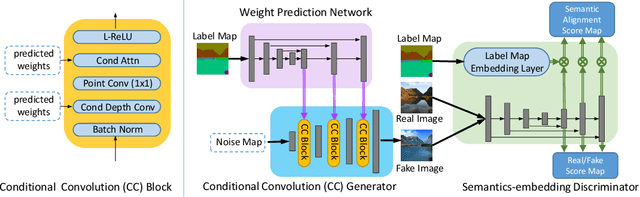
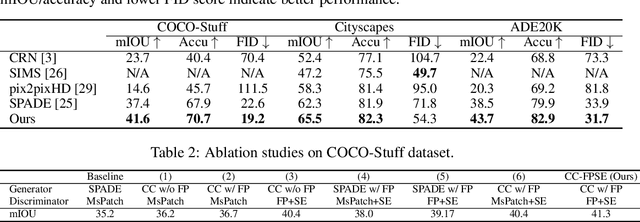

Semantic image synthesis aims at generating photorealistic images from semantic layouts. Previous approaches with conditional generative adversarial networks (GAN) show state-of-the-art performance on this task, which either feed the semantic label maps as inputs to the generator, or use them to modulate the activations in normalization layers via affine transformations. We argue that convolutional kernels in the generator should be aware of the distinct semantic labels at different locations when generating images. In order to better exploit the semantic layout for the image generator, we propose to predict convolutional kernels conditioned on the semantic label map to generate the intermediate feature maps from the noise maps and eventually generate the images. Moreover, we propose a feature pyramid semantics-embedding discriminator, which is more effective in enhancing fine details and semantic alignments between the generated images and the input semantic layouts than previous multi-scale discriminators. We achieve state-of-the-art results on both quantitative metrics and subjective evaluation on various semantic segmentation datasets, demonstrating the effectiveness of our approach.