 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps
Jan 16, 2025



Generative models have made significant impacts across various domains, largely due to their ability to scale during training by increasing data, computational resources, and model size, a phenomenon characterized by the scaling laws. Recent research has begun to explore inference-time scaling behavior in Large Language Models (LLMs), revealing how performance can further improve with additional computation during inference. Unlike LLMs, diffusion models inherently possess the flexibility to adjust inference-time computation via the number of denoising steps, although the performance gains typically flatten after a few dozen. In this work, we explore the inference-time scaling behavior of diffusion models beyond increasing denoising steps and investigate how the generation performance can further improve with increased computation. Specifically, we consider a search problem aimed at identifying better noises for the diffusion sampling process. We structure the design space along two axes: the verifiers used to provide feedback, and the algorithms used to find better noise candidates. Through extensive experiments on class-conditioned and text-conditioned image generation benchmarks, our findings reveal that increasing inference-time compute leads to substantial improvements in the quality of samples generated by diffusion models, and with the complicated nature of images, combinations of the components in the framework can be specifically chosen to conform with different application scenario.
Video Creation by Demonstration
Dec 12, 2024



We explore a novel video creation experience, namely Video Creation by Demonstration. Given a demonstration video and a context image from a different scene, we generate a physically plausible video that continues naturally from the context image and carries out the action concepts from the demonstration. To enable this capability, we present $\delta$-Diffusion, a self-supervised training approach that learns from unlabeled videos by conditional future frame prediction. Unlike most existing video generation controls that are based on explicit signals, we adopts the form of implicit latent control for maximal flexibility and expressiveness required by general videos. By leveraging a video foundation model with an appearance bottleneck design on top, we extract action latents from demonstration videos for conditioning the generation process with minimal appearance leakage. Empirically, $\delta$-Diffusion outperforms related baselines in terms of both human preference and large-scale machine evaluations, and demonstrates potentials towards interactive world simulation. Sampled video generation results are available at https://delta-diffusion.github.io/.
KITTEN: A Knowledge-Intensive Evaluation of Image Generation on Visual Entities
Oct 15, 2024



Recent advancements in text-to-image generation have significantly enhanced the quality of synthesized images. Despite this progress, evaluations predominantly focus on aesthetic appeal or alignment with text prompts. Consequently, there is limited understanding of whether these models can accurately represent a wide variety of realistic visual entities - a task requiring real-world knowledge. To address this gap, we propose a benchmark focused on evaluating Knowledge-InTensive image generaTion on real-world ENtities (i.e., KITTEN). Using KITTEN, we conduct a systematic study on the fidelity of entities in text-to-image generation models, focusing on their ability to generate a wide range of real-world visual entities, such as landmark buildings, aircraft, plants, and animals. We evaluate the latest text-to-image models and retrieval-augmented customization models using both automatic metrics and carefully-designed human evaluations, with an emphasis on the fidelity of entities in the generated images. Our findings reveal that even the most advanced text-to-image models often fail to generate entities with accurate visual details. Although retrieval-augmented models can enhance the fidelity of entity by incorporating reference images during testing, they often over-rely on these references and struggle to produce novel configurations of the entity as requested in creative text prompts.
$ε$-VAE: Denoising as Visual Decoding
Oct 05, 2024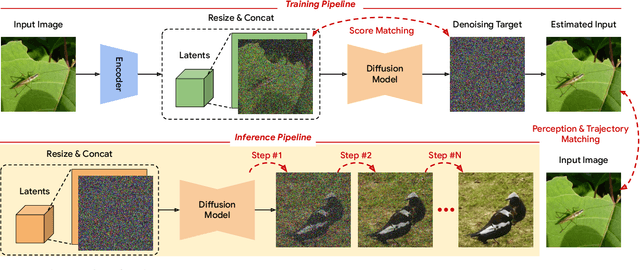
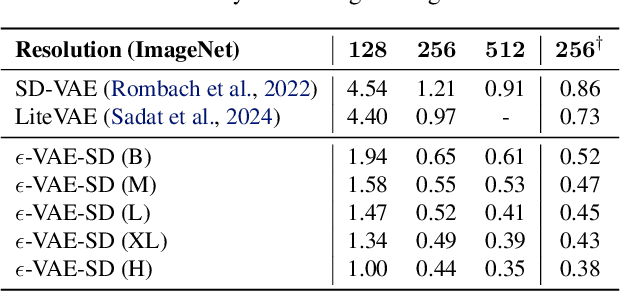
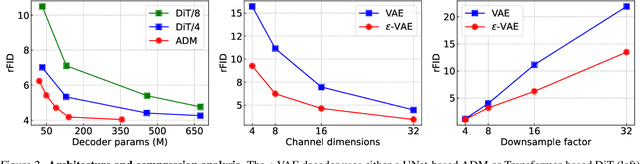
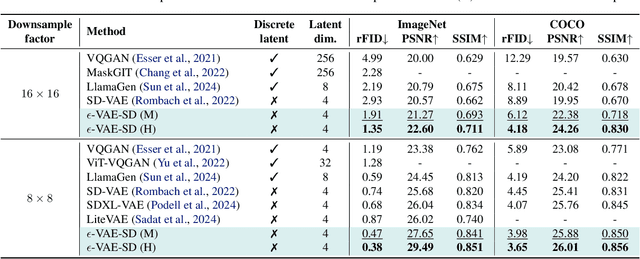
In generative modeling, tokenization simplifies complex data into compact, structured representations, creating a more efficient, learnable space. For high-dimensional visual data, it reduces redundancy and emphasizes key features for high-quality generation. Current visual tokenization methods rely on a traditional autoencoder framework, where the encoder compresses data into latent representations, and the decoder reconstructs the original input. In this work, we offer a new perspective by proposing denoising as decoding, shifting from single-step reconstruction to iterative refinement. Specifically, we replace the decoder with a diffusion process that iteratively refines noise to recover the original image, guided by the latents provided by the encoder. We evaluate our approach by assessing both reconstruction (rFID) and generation quality (FID), comparing it to state-of-the-art autoencoding approach. We hope this work offers new insights into integrating iterative generation and autoencoding for improved compression and generation.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Improving Subject-Driven Image Synthesis with Subject-Agnostic Guidance
May 02, 2024



In subject-driven text-to-image synthesis, the synthesis process tends to be heavily influenced by the reference images provided by users, often overlooking crucial attributes detailed in the text prompt. In this work, we propose Subject-Agnostic Guidance (SAG), a simple yet effective solution to remedy the problem. We show that through constructing a subject-agnostic condition and applying our proposed dual classifier-free guidance, one could obtain outputs consistent with both the given subject and input text prompts. We validate the efficacy of our approach through both optimization-based and encoder-based methods. Additionally, we demonstrate its applicability in second-order customization methods, where an encoder-based model is fine-tuned with DreamBooth. Our approach is conceptually simple and requires only minimal code modifications, but leads to substantial quality improvements, as evidenced by our evaluations and user studies.
Instruct-Imagen: Image Generation with Multi-modal Instruction
Jan 03, 2024



This paper presents instruct-imagen, a model that tackles heterogeneous image generation tasks and generalizes across unseen tasks. We introduce *multi-modal instruction* for image generation, a task representation articulating a range of generation intents with precision. It uses natural language to amalgamate disparate modalities (e.g., text, edge, style, subject, etc.), such that abundant generation intents can be standardized in a uniform format. We then build instruct-imagen by fine-tuning a pre-trained text-to-image diffusion model with a two-stage framework. First, we adapt the model using the retrieval-augmented training, to enhance model's capabilities to ground its generation on external multimodal context. Subsequently, we fine-tune the adapted model on diverse image generation tasks that requires vision-language understanding (e.g., subject-driven generation, etc.), each paired with a multi-modal instruction encapsulating the task's essence. Human evaluation on various image generation datasets reveals that instruct-imagen matches or surpasses prior task-specific models in-domain and demonstrates promising generalization to unseen and more complex tasks.
Alchemist: Parametric Control of Material Properties with Diffusion Models
Dec 05, 2023



We propose a method to control material attributes of objects like roughness, metallic, albedo, and transparency in real images. Our method capitalizes on the generative prior of text-to-image models known for photorealism, employing a scalar value and instructions to alter low-level material properties. Addressing the lack of datasets with controlled material attributes, we generated an object-centric synthetic dataset with physically-based materials. Fine-tuning a modified pre-trained text-to-image model on this synthetic dataset enables us to edit material properties in real-world images while preserving all other attributes. We show the potential application of our model to material edited NeRFs.
Fine-grained Controllable Video Generation via Object Appearance and Context
Dec 05, 2023



Text-to-video generation has shown promising results. However, by taking only natural languages as input, users often face difficulties in providing detailed information to precisely control the model's output. In this work, we propose fine-grained controllable video generation (FACTOR) to achieve detailed control. Specifically, FACTOR aims to control objects' appearances and context, including their location and category, in conjunction with the text prompt. To achieve detailed control, we propose a unified framework to jointly inject control signals into the existing text-to-video model. Our model consists of a joint encoder and adaptive cross-attention layers. By optimizing the encoder and the inserted layer, we adapt the model to generate videos that are aligned with both text prompts and fine-grained control. Compared to existing methods relying on dense control signals such as edge maps, we provide a more intuitive and user-friendly interface to allow object-level fine-grained control. Our method achieves controllability of object appearances without finetuning, which reduces the per-subject optimization efforts for the users. Extensive experiments on standard benchmark datasets and user-provided inputs validate that our model obtains a 70% improvement in controllability metrics over competitive baselines.
Controllable One-Shot Face Video Synthesis With Semantic Aware Prior
Apr 27, 2023The one-shot talking-head synthesis task aims to animate a source image to another pose and expression, which is dictated by a driving frame. Recent methods rely on warping the appearance feature extracted from the source, by using motion fields estimated from the sparse keypoints, that are learned in an unsupervised manner. Due to their lightweight formulation, they are suitable for video conferencing with reduced bandwidth. However, based on our study, current methods suffer from two major limitations: 1) unsatisfactory generation quality in the case of large head poses and the existence of observable pose misalignment between the source and the first frame in driving videos. 2) fail to capture fine yet critical face motion details due to the lack of semantic understanding and appropriate face geometry regularization. To address these shortcomings, we propose a novel method that leverages the rich face prior information, the proposed model can generate face videos with improved semantic consistency (improve baseline by $7\%$ in average keypoint distance) and expression-preserving (outperform baseline by $15 \%$ in average emotion embedding distance) under equivalent bandwidth. Additionally, incorporating such prior information provides us with a convenient interface to achieve highly controllable generation in terms of both pose and expression.