 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASTRA-bench: Evaluating Tool-Use Agent Reasoning and Action Planning with Personal User Context
Mar 02, 2026Next-generation AI must manage vast personal data, diverse tools, and multi-step reasoning, yet most benchmarks remain context-free and single-turn. We present ASTRA-bench (Assistant Skills in Tool-use, Reasoning \& Action-planning), a benchmark that uniquely unifies time-evolving personal context with an interactive toolbox and complex user intents. Our event-driven pipeline generates 2,413 scenarios across four protagonists, grounded in longitudinal life events and annotated by referential, functional, and informational complexity. Evaluation of state-of-the-art models (e.g., Claude-4.5-Opus, DeepSeek-V3.2) reveals significant performance degradation under high-complexity conditions, with argument generation emerging as the primary bottleneck. These findings expose critical limitations in current agents' ability to ground reasoning within messy personal context and orchestrate reliable multi-step plans. We release ASTRA-bench with a full execution environment and evaluation scripts to provide a diagnostic testbed for developing truly context-aware AI assistants.
AMUSE: Audio-Visual Benchmark and Alignment Framework for Agentic Multi-Speaker Understanding
Dec 18, 2025

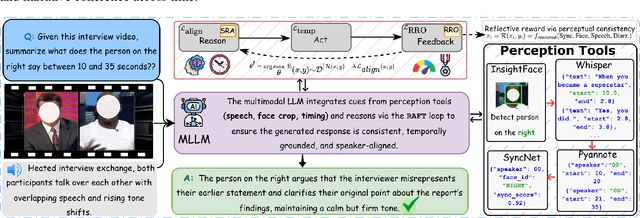
Recent multimodal large language models (MLLMs) such as GPT-4o and Qwen3-Omni show strong perception but struggle in multi-speaker, dialogue-centric settings that demand agentic reasoning tracking who speaks, maintaining roles, and grounding events across time. These scenarios are central to multimodal audio-video understanding, where models must jointly reason over audio and visual streams in applications such as conversational video assistants and meeting analytics. We introduce AMUSE, a benchmark designed around tasks that are inherently agentic, requiring models to decompose complex audio-visual interactions into planning, grounding, and reflection steps. It evaluates MLLMs across three modes zero-shot, guided, and agentic and six task families, including spatio-temporal speaker grounding and multimodal dialogue summarization. Across all modes, current models exhibit weak multi-speaker reasoning and inconsistent behavior under both non-agentic and agentic evaluation. Motivated by the inherently agentic nature of these tasks and recent advances in LLM agents, we propose RAFT, a data-efficient agentic alignment framework that integrates reward optimization with intrinsic multimodal self-evaluation as reward and selective parameter adaptation for data and parameter efficient updates. Using RAFT, we achieve up to 39.52\% relative improvement in accuracy on our benchmark. Together, AMUSE and RAFT provide a practical platform for examining agentic reasoning in multimodal models and improving their capabilities.
COMPASS: A Multi-Turn Benchmark for Tool-Mediated Planning & Preference Optimization
Oct 08, 2025



Real-world large language model (LLM) agents must master strategic tool use and user preference optimization through multi-turn interactions to assist users with complex planning tasks. We introduce COMPASS (Constrained Optimization through Multi-turn Planning and Strategic Solutions), a benchmark that evaluates agents on realistic travel-planning scenarios. We cast travel planning as a constrained preference optimization problem, where agents must satisfy hard constraints while simultaneously optimizing soft user preferences. To support this, we build a realistic travel database covering transportation, accommodation, and ticketing for 20 U.S. National Parks, along with a comprehensive tool ecosystem that mirrors commercial booking platforms. Evaluating state-of-the-art models, we uncover two critical gaps: (i) an acceptable-optimal gap, where agents reliably meet constraints but fail to optimize preferences, and (ii) a plan-coordination gap, where performance collapses on multi-service (flight and hotel) coordination tasks, especially for open-source models. By grounding reasoning and planning in a practical, user-facing domain, COMPASS provides a benchmark that directly measures an agent's ability to optimize user preferences in realistic tasks, bridging theoretical advances with real-world impact.
Learning to Reason for Hallucination Span Detection
Oct 02, 2025



Large language models (LLMs) often generate hallucinations -- unsupported content that undermines reliability. While most prior works frame hallucination detection as a binary task, many real-world applications require identifying hallucinated spans, which is a multi-step decision making process. This naturally raises the question of whether explicit reasoning can help the complex task of detecting hallucination spans. To answer this question, we first evaluate pretrained models with and without Chain-of-Thought (CoT) reasoning, and show that CoT reasoning has the potential to generate at least one correct answer when sampled multiple times. Motivated by this, we propose RL4HS, a reinforcement learning framework that incentivizes reasoning with a span-level reward function. RL4HS builds on Group Relative Policy Optimization and introduces Class-Aware Policy Optimization to mitigate reward imbalance issue. Experiments on the RAGTruth benchmark (summarization, question answering, data-to-text) show that RL4HS surpasses pretrained reasoning models and supervised fine-tuning, demonstrating the necessity of reinforcement learning with span-level rewards for detecting hallucination spans.
Proxy-FDA: Proxy-based Feature Distribution Alignment for Fine-tuning Vision Foundation Models without Forgetting
May 30, 2025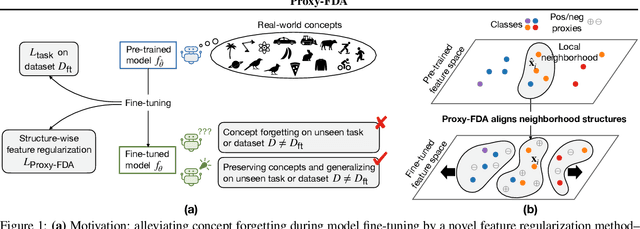
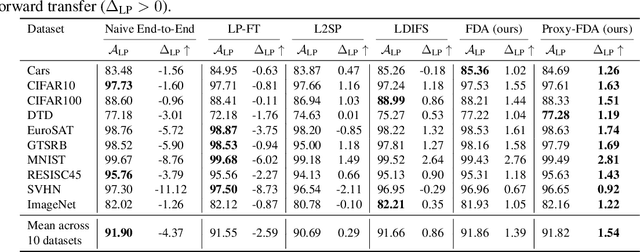
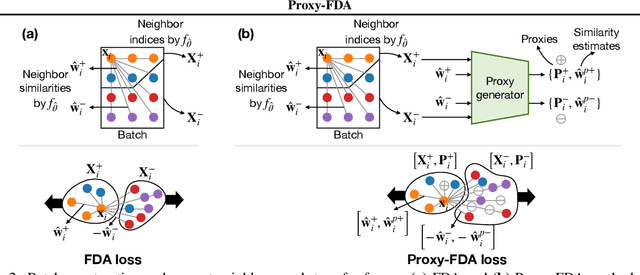
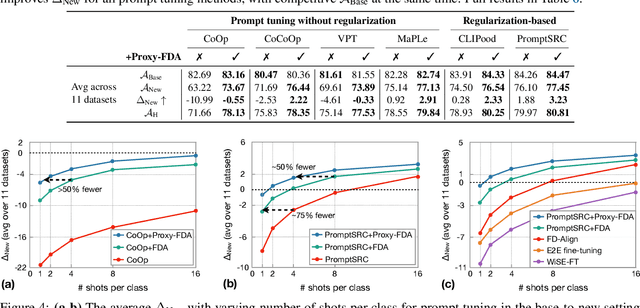
Vision foundation models pre-trained on massive data encode rich representations of real-world concepts, which can be adapted to downstream tasks by fine-tuning. However, fine-tuning foundation models on one task often leads to the issue of concept forgetting on other tasks. Recent methods of robust fine-tuning aim to mitigate forgetting of prior knowledge without affecting the fine-tuning performance. Knowledge is often preserved by matching the original and fine-tuned model weights or feature pairs. However, such point-wise matching can be too strong, without explicit awareness of the feature neighborhood structures that encode rich knowledge as well. We propose a novel regularization method Proxy-FDA that explicitly preserves the structural knowledge in feature space. Proxy-FDA performs Feature Distribution Alignment (using nearest neighbor graphs) between the pre-trained and fine-tuned feature spaces, and the alignment is further improved by informative proxies that are generated dynamically to increase data diversity. Experiments show that Proxy-FDA significantly reduces concept forgetting during fine-tuning, and we find a strong correlation between forgetting and a distributional distance metric (in comparison to L2 distance). We further demonstrate Proxy-FDA's benefits in various fine-tuning settings (end-to-end, few-shot and continual tuning) and across different tasks like image classification, captioning and VQA.
FocalLens: Instruction Tuning Enables Zero-Shot Conditional Image Representations
Apr 11, 2025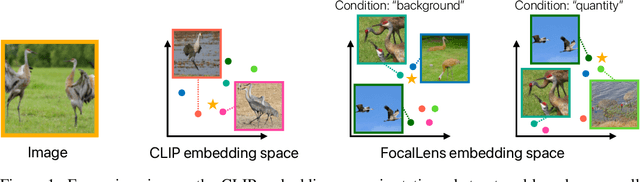
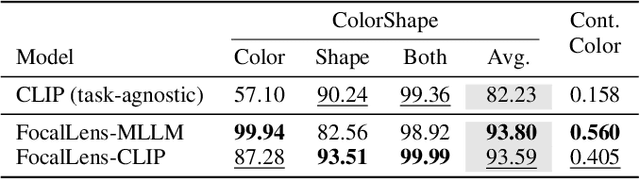
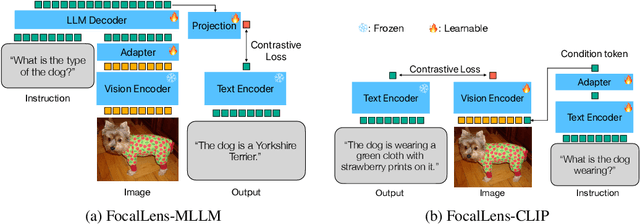
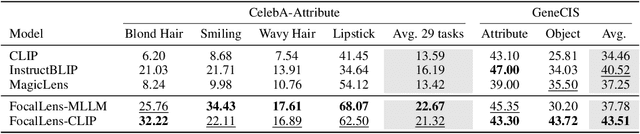
Visual understanding is inherently contextual -- what we focus on in an image depends on the task at hand. For instance, given an image of a person holding a bouquet of flowers, we may focus on either the person such as their clothing, or the type of flowers, depending on the context of interest. Yet, most existing image encoding paradigms represent an image as a fixed, generic feature vector, overlooking the potential needs of prioritizing varying visual information for different downstream use cases. In this work, we introduce FocalLens, a conditional visual encoding method that produces different representations for the same image based on the context of interest, expressed flexibly through natural language. We leverage vision instruction tuning data and contrastively finetune a pretrained vision encoder to take natural language instructions as additional inputs for producing conditional image representations. Extensive experiments validate that conditional image representation from FocalLens better pronounce the visual features of interest compared to generic features produced by standard vision encoders like CLIP. In addition, we show FocalLens further leads to performance improvements on a range of downstream tasks including image-image retrieval, image classification, and image-text retrieval, with an average gain of 5 and 10 points on the challenging SugarCrepe and MMVP-VLM benchmarks, respectively.
TiC-LM: A Web-Scale Benchmark for Time-Continual LLM Pretraining
Apr 02, 2025Large Language Models (LLMs) trained on historical web data inevitably become outdated. We investigate evaluation strategies and update methods for LLMs as new data becomes available. We introduce a web-scale dataset for time-continual pretraining of LLMs derived from 114 dumps of Common Crawl (CC) - orders of magnitude larger than previous continual language modeling benchmarks. We also design time-stratified evaluations across both general CC data and specific domains (Wikipedia, StackExchange, and code documentation) to assess how well various continual learning methods adapt to new data while retaining past knowledge. Our findings demonstrate that, on general CC data, autoregressive meta-schedules combined with a fixed-ratio replay of older data can achieve comparable held-out loss to re-training from scratch, while requiring significantly less computation (2.6x). However, the optimal balance between incorporating new data and replaying old data differs as replay is crucial to avoid forgetting on generic web data but less so on specific domains.
LangDA: Building Context-Awareness via Language for Domain Adaptive Semantic Segmentation
Mar 17, 2025Unsupervised domain adaptation for semantic segmentation (DASS) aims to transfer knowledge from a label-rich source domain to a target domain with no labels. Two key approaches in DASS are (1) vision-only approaches using masking or multi-resolution crops, and (2) language-based approaches that use generic class-wise prompts informed by target domain (e.g. "a {snowy} photo of a {class}"). However, the former is susceptible to noisy pseudo-labels that are biased to the source domain. The latter does not fully capture the intricate spatial relationships of objects -- key for dense prediction tasks. To this end, we propose LangDA. LangDA addresses these challenges by, first, learning contextual relationships between objects via VLM-generated scene descriptions (e.g. "a pedestrian is on the sidewalk, and the street is lined with buildings."). Second, LangDA aligns the entire image features with text representation of this context-aware scene caption and learns generalized representations via text. With this, LangDA sets the new state-of-the-art across three DASS benchmarks, outperforming existing methods by 2.6%, 1.4% and 3.9%.
Mutual Reinforcement of LLM Dialogue Synthesis and Summarization Capabilities for Few-Shot Dialogue Summarization
Feb 24, 2025In this work, we propose Mutual Reinforcing Data Synthesis (MRDS) within LLMs to improve few-shot dialogue summarization task. Unlike prior methods that require external knowledge, we mutually reinforce the LLM\'s dialogue synthesis and summarization capabilities, allowing them to complement each other during training and enhance overall performances. The dialogue synthesis capability is enhanced by directed preference optimization with preference scoring from summarization capability. The summarization capability is enhanced by the additional high quality dialogue-summary paired data produced by the dialogue synthesis capability. By leveraging the proposed MRDS mechanism, we elicit the internal knowledge of LLM in the format of synthetic data, and use it to augment the few-shot real training dataset. Empirical results demonstrate that our method improves dialogue summarization, achieving a 1.5% increase in ROUGE scores and a 0.3% improvement in BERT scores in few-shot settings. Furthermore, our method attains the highest average scores in human evaluations, surpassing both the pre-trained models and the baselines fine-tuned solely for summarization tasks.
Synth4Seg -- Learning Defect Data Synthesis for Defect Segmentation using Bi-level Optimization
Oct 24, 2024Defect segmentation is crucial for quality control in advanced manufacturing, yet data scarcity poses challenges for state-of-the-art supervised deep learning. Synthetic defect data generation is a popular approach for mitigating data challenges. However, many current methods simply generate defects following a fixed set of rules, which may not directly relate to downstream task performance. This can lead to suboptimal performance and may even hinder the downstream task. To solve this problem, we leverage a novel bi-level optimization-based synthetic defect data generation framework. We use an online synthetic defect generation module grounded in the commonly-used Cut\&Paste framework, and adopt an efficient gradient-based optimization algorithm to solve the bi-level optimization problem. We achieve simultaneous training of the defect segmentation network, and learn various parameters of the data synthesis module by maximizing the validation performance of the trained defect segmentation network. Our experimental results on benchmark datasets under limited data settings show that the proposed bi-level optimization method can be used for learning the most effective locations for pasting synthetic defects thereby improving the segmentation performance by up to 18.3\% when compared to pasting defects at random locations. We also demonstrate up to 2.6\% performance gain by learning the importance weights for different augmentation-specific defect data sources when compared to giving equal importance to all the data sources.