 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient Speech-Text Jointly Decoding within One Speech Language Model
Jun 04, 2025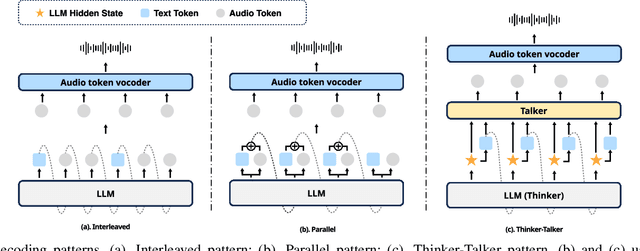
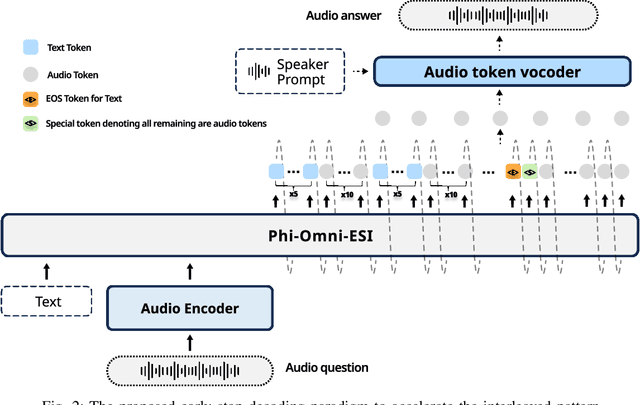


Speech language models (Speech LMs) enable end-to-end speech-text modelling within a single model, offering a promising direction for spoken dialogue systems. The choice of speech-text jointly decoding paradigm plays a critical role in performance, efficiency, and alignment quality. In this work, we systematically compare representative joint speech-text decoding strategies-including the interleaved, and parallel generation paradigms-under a controlled experimental setup using the same base language model, speech tokenizer and training data. Our results show that the interleaved approach achieves the best alignment. However it suffers from slow inference due to long token sequence length. To address this, we propose a novel early-stop interleaved (ESI) pattern that not only significantly accelerates decoding but also yields slightly better performance. Additionally, we curate high-quality question answering (QA) datasets to further improve speech QA performance.
Phi-Omni-ST: A multimodal language model for direct speech-to-speech translation
Jun 04, 2025Speech-aware language models (LMs) have demonstrated capabilities in understanding spoken language while generating text-based responses. However, enabling them to produce speech output efficiently and effectively remains a challenge. In this paper, we present Phi-Omni-ST, a multimodal LM for direct speech-to-speech translation (ST), built on the open-source Phi-4 MM model. Phi-Omni-ST extends its predecessor by generating translated speech using an audio transformer head that predicts audio tokens with a delay relative to text tokens, followed by a streaming vocoder for waveform synthesis. Our experimental results on the CVSS-C dataset demonstrate Phi-Omni-ST's superior performance, significantly surpassing existing baseline models trained on the same dataset. Furthermore, when we scale up the training data and the model size, Phi-Omni-ST reaches on-par performance with the current SOTA model.
Sentinel: Scheduling Live Streams with Proactive Anomaly Detection in Crowdsourced Cloud-Edge Platforms
May 29, 2025With the rapid growth of live streaming services, Crowdsourced Cloud-edge service Platforms (CCPs) are playing an increasingly important role in meeting the increasing demand. Although stream scheduling plays a critical role in optimizing CCPs' revenue, most optimization strategies struggle to achieve practical results due to various anomalies in unstable CCPs. Additionally, the substantial scale of CCPs magnifies the difficulties of anomaly detection in time-sensitive scheduling. To tackle these challenges, this paper proposes Sentinel, a proactive anomaly detection-based scheduling framework. Sentinel models the scheduling process as a two-stage Pre-Post-Scheduling paradigm: in the pre-scheduling stage, Sentinel conducts anomaly detection and constructs a strategy pool; in the post-scheduling stage, upon request arrival, it triggers an appropriate scheduling based on a pre-generated strategy to implement the scheduling process. Extensive experiments on realistic datasets show that Sentinel significantly reduces anomaly frequency by 70%, improves revenue by 74%, and doubles the scheduling speed.
Accelerating Flow-Matching-Based Text-to-Speech via Empirically Pruned Step Sampling
May 26, 2025



Flow-matching-based text-to-speech (TTS) models, such as Voicebox, E2 TTS, and F5-TTS, have attracted significant attention in recent years. These models require multiple sampling steps to reconstruct speech from noise, making inference speed a key challenge. Reducing the number of sampling steps can greatly improve inference efficiency. To this end, we introduce Fast F5-TTS, a training-free approach to accelerate the inference of flow-matching-based TTS models. By inspecting the sampling trajectory of F5-TTS, we identify redundant steps and propose Empirically Pruned Step Sampling (EPSS), a non-uniform time-step sampling strategy that effectively reduces the number of sampling steps. Our approach achieves a 7-step generation with an inference RTF of 0.030 on an NVIDIA RTX 3090 GPU, making it 4 times faster than the original F5-TTS while maintaining comparable performance. Furthermore, EPSS performs well on E2 TTS models, demonstrating its strong generalization ability.
Adaptive Spatial Transcriptomics Interpolation via Cross-modal Cross-slice Modeling
May 15, 2025Spatial transcriptomics (ST) is a promising technique that characterizes the spatial gene profiling patterns within the tissue context. Comprehensive ST analysis depends on consecutive slices for 3D spatial insights, whereas the missing intermediate tissue sections and high costs limit the practical feasibility of generating multi-slice ST. In this paper, we propose C2-STi, the first attempt for interpolating missing ST slices at arbitrary intermediate positions between adjacent ST slices. Despite intuitive, effective ST interpolation presents significant challenges, including 1) limited continuity across heterogeneous tissue sections, 2) complex intrinsic correlation across genes, and 3) intricate cellular structures and biological semantics within each tissue section. To mitigate these challenges, in C2-STi, we design 1) a distance-aware local structural modulation module to adaptively capture cross-slice deformations and enhance positional correlations between ST slices, 2) a pyramid gene co-expression correlation module to capture multi-scale biological associations among genes, and 3) a cross-modal alignment module that integrates the ST-paired hematoxylin and eosin (H&E)-stained images to filter and align the essential cellular features across ST and H\&E images. Extensive experiments on the public dataset demonstrate our superiority over state-of-the-art approaches on both single-slice and multi-slice ST interpolation. Codes are available at https://github.com/XiaofeiWang2018/C2-STi.
GLRD: Global-Local Collaborative Reason and Debate with PSL for 3D Open-Vocabulary Detection
Mar 26, 2025



The task of LiDAR-based 3D Open-Vocabulary Detection (3D OVD) requires the detector to learn to detect novel objects from point clouds without off-the-shelf training labels. Previous methods focus on the learning of object-level representations and ignore the scene-level information, thus it is hard to distinguish objects with similar classes. In this work, we propose a Global-Local Collaborative Reason and Debate with PSL (GLRD) framework for the 3D OVD task, considering both local object-level information and global scene-level information. Specifically, LLM is utilized to perform common sense reasoning based on object-level and scene-level information, where the detection result is refined accordingly. To further boost the LLM's ability of precise decisions, we also design a probabilistic soft logic solver (OV-PSL) to search for the optimal solution, and a debate scheme to confirm the class of confusable objects. In addition, to alleviate the uneven distribution of classes, a static balance scheme (SBC) and a dynamic balance scheme (DBC) are designed. In addition, to reduce the influence of noise in data and training, we further propose Reflected Pseudo Labels Generation (RPLG) and Background-Aware Object Localization (BAOL). Extensive experiments conducted on ScanNet and SUN RGB-D demonstrate the superiority of GLRD, where absolute improvements in mean average precision are $+2.82\%$ on SUN RGB-D and $+3.72\%$ on ScanNet in the partial open-vocabulary setting. In the full open-vocabulary setting, the absolute improvements in mean average precision are $+4.03\%$ on ScanNet and $+14.11\%$ on SUN RGB-D.
Zero-Shot Audio-Visual Editing via Cross-Modal Delta Denoising
Mar 26, 2025



In this paper, we introduce zero-shot audio-video editing, a novel task that requires transforming original audio-visual content to align with a specified textual prompt without additional model training. To evaluate this task, we curate a benchmark dataset, AvED-Bench, designed explicitly for zero-shot audio-video editing. AvED-Bench includes 110 videos, each with a 10-second duration, spanning 11 categories from VGGSound. It offers diverse prompts and scenarios that require precise alignment between auditory and visual elements, enabling robust evaluation. We identify limitations in existing zero-shot audio and video editing methods, particularly in synchronization and coherence between modalities, which often result in inconsistent outcomes. To address these challenges, we propose AvED, a zero-shot cross-modal delta denoising framework that leverages audio-video interactions to achieve synchronized and coherent edits. AvED demonstrates superior results on both AvED-Bench and the recent OAVE dataset to validate its generalization capabilities. Results are available at https://genjib.github.io/project_page/AVED/index.html
Joint Modelling Histology and Molecular Markers for Cancer Classification
Feb 11, 2025



Cancers are characterized by remarkable heterogeneity and diverse prognosis. Accurate cancer classification is essential for patient stratification and clinical decision-making. Although digital pathology has been advancing cancer diagnosis and prognosis, the paradigm in cancer pathology has shifted from purely relying on histology features to incorporating molecular markers. There is an urgent need for digital pathology methods to meet the needs of the new paradigm. We introduce a novel digital pathology approach to jointly predict molecular markers and histology features and model their interactions for cancer classification. Firstly, to mitigate the challenge of cross-magnification information propagation, we propose a multi-scale disentangling module, enabling the extraction of multi-scale features from high-magnification (cellular-level) to low-magnification (tissue-level) whole slide images. Further, based on the multi-scale features, we propose an attention-based hierarchical multi-task multi-instance learning framework to simultaneously predict histology and molecular markers. Moreover, we propose a co-occurrence probability-based label correlation graph network to model the co-occurrence of molecular markers. Lastly, we design a cross-modal interaction module with the dynamic confidence constrain loss and a cross-modal gradient modulation strategy, to model the interactions of histology and molecular markers. Our experiments demonstrate that our method outperforms other state-of-the-art methods in classifying glioma, histology features and molecular markers. Our method promises to promote precise oncology with the potential to advance biomedical research and clinical applications. The code is available at https://github.com/LHY1007/M3C2
Streaming Speaker Change Detection and Gender Classification for Transducer-Based Multi-Talker Speech Translation
Feb 04, 2025



Streaming multi-talker speech translation is a task that involves not only generating accurate and fluent translations with low latency but also recognizing when a speaker change occurs and what the speaker's gender is. Speaker change information can be used to create audio prompts for a zero-shot text-to-speech system, and gender can help to select speaker profiles in a conventional text-to-speech model. We propose to tackle streaming speaker change detection and gender classification by incorporating speaker embeddings into a transducer-based streaming end-to-end speech translation model. Our experiments demonstrate that the proposed methods can achieve high accuracy for both speaker change detection and gender classification.
Summary of the NOTSOFAR-1 Challenge: Highlights and Learnings
Jan 28, 2025



The first Natural Office Talkers in Settings of Far-field Audio Recordings (NOTSOFAR-1) Challenge is a pivotal initiative that sets new benchmarks by offering datasets more representative of the needs of real-world business applications than those previously available. The challenge provides a unique combination of 280 recorded meetings across 30 diverse environments, capturing real-world acoustic conditions and conversational dynamics, and a 1000-hour simulated training dataset, synthesized with enhanced authenticity for real-world generalization, incorporating 15,000 real acoustic transfer functions. In this paper, we provide an overview of the systems submitted to the challenge and analyze the top-performing approaches, hypothesizing the factors behind their success. Additionally, we highlight promising directions left unexplored by participants. By presenting key findings and actionable insights, this work aims to drive further innovation and progress in DASR research and applications.