 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Aware Answer Preservation under Audio Compression for Large Audio Language Models
May 07, 2026Large audio language models (LALMs) are increasingly used to reason over long audio clips, yet deployment often compresses audio before inference to reduce memory and latency. The risk is that compression can leave aggregate accuracy acceptable while sharply degrading answers for a deployment-critical query family. We study answer-preserving audio compression, judging a compressor by the excess answer-error it induces, especially for the worst-affected family. We formulate this theoretically as a compressor acceptance-rejection criterion, derive a practical sign-off protocol that returns compression budgets satisfying worst-family checks with statistical confidence, and evaluate it on five multiple-choice audio question-answering benchmarks with two Qwen-based backbones. The protocol exposes hidden family-level damage, shows that the chosen query-family partition can change the approved budget, and identifies regimes where query-conditioned compression helps maintain answer preservation.
LALM-as-a-Judge: Benchmarking Large Audio-Language Models for Safety Evaluation in Multi-Turn Spoken Dialogues
Feb 04, 2026Spoken dialogues with and between voice agents are becoming increasingly common, yet assessing them for their socially harmful content such as violence, harassment, and hate remains text-centric and fails to account for audio-specific cues and transcription errors. We present LALM-as-a-Judge, the first controlled benchmark and systematic study of large audio-language models (LALMs) as safety judges for multi-turn spoken dialogues. We generate 24,000 unsafe and synthetic spoken dialogues in English that consist of 3-10 turns, by having a single dialogue turn including content with one of 8 harmful categories (e.g., violence) and on one of 5 grades, from very mild to severe. On 160 dialogues, 5 human raters confirmed reliable unsafe detection and a meaningful severity scale. We benchmark three open-source LALMs: Qwen2-Audio, Audio Flamingo 3, and MERaLiON as zero-shot judges that output a scalar safety score in [0,1] across audio-only, transcription-only, or multimodal inputs, along with a transcription-only LLaMA baseline. We measure the judges' sensitivity to detecting unsafe content, the specificity in ordering severity levels, and the stability of the score in dialogue turns. Results reveal architecture- and modality-dependent trade-offs: the most sensitive judge is also the least stable across turns, while stable configurations sacrifice detection of mild harmful content. Transcription quality is a key bottleneck: Whisper-Large may significantly reduce sensitivity for transcription-only modes, while largely preserving severity ordering. Audio becomes crucial when paralinguistic cues or transcription fidelity are category-critical. We summarize all findings and provide actionable guidance for practitioners.
An Automated Tip-and-Cue Framework for Optimized Satellite Tasking and Visual Intelligence
Dec 10, 2025The proliferation of satellite constellations, coupled with reduced tasking latency and diverse sensor capabilities, has expanded the opportunities for automated Earth observation. This paper introduces a fully automated Tip-and-Cue framework designed for satellite imaging tasking and scheduling. In this context, tips are generated from external data sources or analyses of prior satellite imagery, identifying spatiotemporal targets and prioritizing them for downstream planning. Corresponding cues are the imaging tasks formulated in response, which incorporate sensor constraints, timing requirements, and utility functions. The system autonomously generates candidate tasks, optimizes their scheduling across multiple satellites using continuous utility functions that reflect the expected value of each observation, and processes the resulting imagery using artificial-intelligence-based models, including object detectors and vision-language models. Structured visual reports are generated to support both interpretability and the identification of new insights for downstream tasking. The efficacy of the framework is demonstrated through a maritime vessel tracking scenario, utilizing Automatic Identification System (AIS) data for trajectory prediction, targeted observations, and the generation of actionable outputs. Maritime vessel tracking is a widely researched application, often used to benchmark novel approaches to satellite tasking, forecasting, and analysis. The system is extensible to broader applications such as smart-city monitoring and disaster response, where timely tasking and automated analysis are critical.
MAPSS: Manifold-based Assessment of Perceptual Source Separation
Sep 11, 2025Objective assessment of source-separation systems still mismatches subjective human perception, especially when leakage and self-distortion interact. We introduce the Perceptual Separation (PS) and Perceptual Match (PM), the first pair of measures that functionally isolate these two factors. Our intrusive method begins with generating a bank of fundamental distortions for each reference waveform signal in the mixture. Distortions, references, and their respective system outputs from all sources are then independently encoded by a pre-trained self-supervised learning model. These representations are aggregated and projected onto a manifold via diffusion maps, which aligns Euclidean distances on the manifold with dissimilarities of the encoded waveforms. On this manifold, the PM measures the Mahalanobis distance from each output to its attributed cluster that consists of its reference and distortions embeddings, capturing self-distortion. The PS accounts for the Mahalanobis distance of the output to the attributed and to the closest non-attributed clusters, quantifying leakage. Both measures are differentiable and granular, operating at a resolution as low as 50 frames per second. We further derive, for both measures, deterministic error radius and non-asymptotic, high-probability confidence intervals (CIs). Experiments on English, Spanish, and music mixtures show that the PS and PM nearly always achieve the highest linear correlation coefficients with human mean-opinion scores than 14 competitors, reaching as high as 86.36% for speech and 87.21% for music. We observe, at worst, an error radius of 1.39% and a probabilistic 95% CI of 12.21% for these coefficients, which improves reliable and informed evaluation. Using mutual information, the measures complement each other most as their values decrease, suggesting they are jointly more informative as system performance degrades.
Summary of the NOTSOFAR-1 Challenge: Highlights and Learnings
Jan 28, 2025



The first Natural Office Talkers in Settings of Far-field Audio Recordings (NOTSOFAR-1) Challenge is a pivotal initiative that sets new benchmarks by offering datasets more representative of the needs of real-world business applications than those previously available. The challenge provides a unique combination of 280 recorded meetings across 30 diverse environments, capturing real-world acoustic conditions and conversational dynamics, and a 1000-hour simulated training dataset, synthesized with enhanced authenticity for real-world generalization, incorporating 15,000 real acoustic transfer functions. In this paper, we provide an overview of the systems submitted to the challenge and analyze the top-performing approaches, hypothesizing the factors behind their success. Additionally, we highlight promising directions left unexplored by participants. By presenting key findings and actionable insights, this work aims to drive further innovation and progress in DASR research and applications.
NOTSOFAR-1 Challenge: New Datasets, Baseline, and Tasks for Distant Meeting Transcription
Jan 16, 2024

We introduce the first Natural Office Talkers in Settings of Far-field Audio Recordings (``NOTSOFAR-1'') Challenge alongside datasets and baseline system. The challenge focuses on distant speaker diarization and automatic speech recognition (DASR) in far-field meeting scenarios, with single-channel and known-geometry multi-channel tracks, and serves as a launch platform for two new datasets: First, a benchmarking dataset of 315 meetings, averaging 6 minutes each, capturing a broad spectrum of real-world acoustic conditions and conversational dynamics. It is recorded across 30 conference rooms, featuring 4-8 attendees and a total of 35 unique speakers. Second, a 1000-hour simulated training dataset, synthesized with enhanced authenticity for real-world generalization, incorporating 15,000 real acoustic transfer functions. The tasks focus on single-device DASR, where multi-channel devices always share the same known geometry. This is aligned with common setups in actual conference rooms, and avoids technical complexities associated with multi-device tasks. It also allows for the development of geometry-specific solutions. The NOTSOFAR-1 Challenge aims to advance research in the field of distant conversational speech recognition, providing key resources to unlock the potential of data-driven methods, which we believe are currently constrained by the absence of comprehensive high-quality training and benchmarking datasets.
Deep Learning Interviews: Hundreds of fully solved job interview questions from a wide range of key topics in AI
Jan 04, 2022The second edition of Deep Learning Interviews is home to hundreds of fully-solved problems, from a wide range of key topics in AI. It is designed to both rehearse interview or exam specific topics and provide machine learning MSc / PhD. students, and those awaiting an interview a well-organized overview of the field. The problems it poses are tough enough to cut your teeth on and to dramatically improve your skills-but they're framed within thought-provoking questions and engaging stories. That is what makes the volume so specifically valuable to students and job seekers: it provides them with the ability to speak confidently and quickly on any relevant topic, to answer technical questions clearly and correctly, and to fully understand the purpose and meaning of interview questions and answers. Those are powerful, indispensable advantages to have when walking into the interview room. The book's contents is a large inventory of numerous topics relevant to DL job interviews and graduate level exams. That places this work at the forefront of the growing trend in science to teach a core set of practical mathematical and computational skills. It is widely accepted that the training of every computer scientist must include the fundamental theorems of ML, and AI appears in the curriculum of nearly every university. This volume is designed as an excellent reference for graduates of such programs.
Objective Metrics to Evaluate Residual-Echo Suppression During Double-Talk
Jul 15, 2021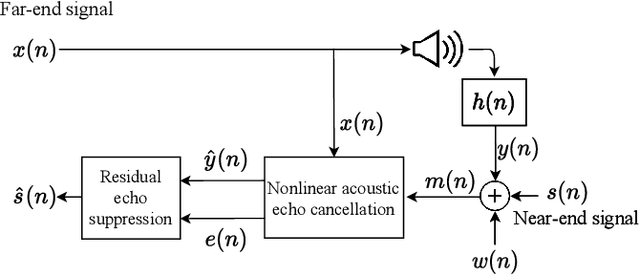
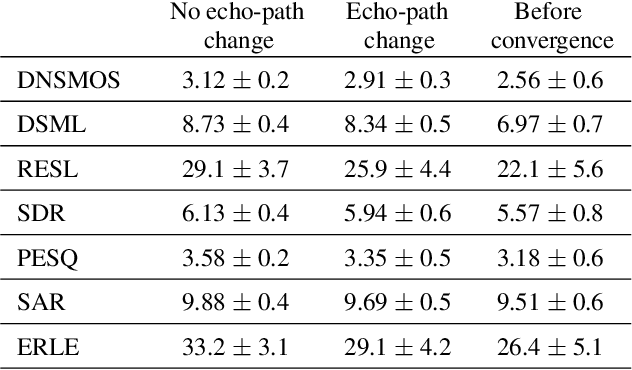
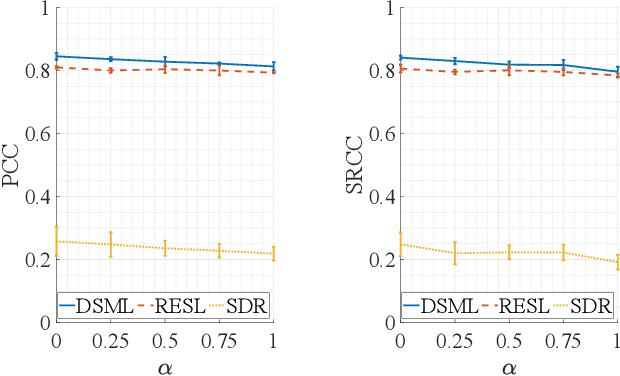
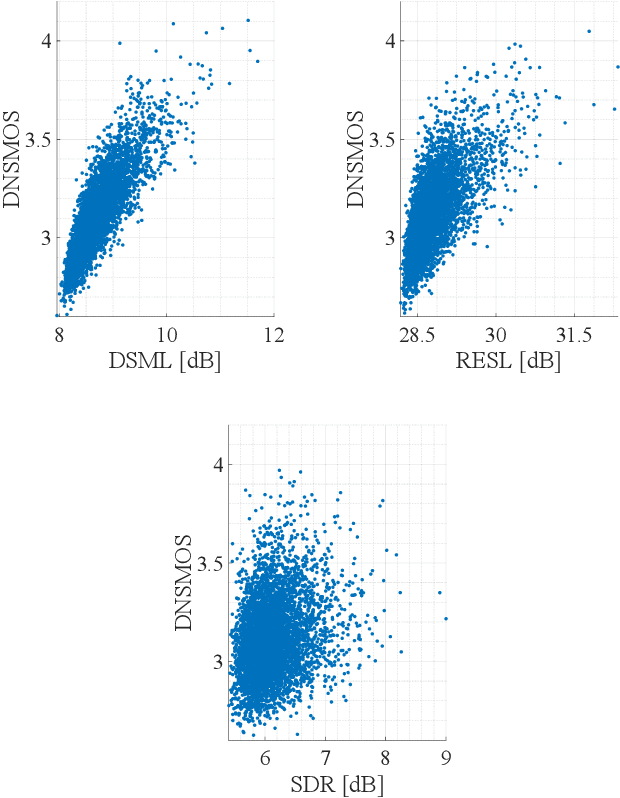
Human subjective evaluation is optimal to assess speech quality for human perception. The recently introduced deep noise suppression mean opinion score (DNSMOS) metric was shown to estimate human ratings with great accuracy. The signal-to-distortion ratio (SDR) metric is widely used to evaluate residual-echo suppression (RES) systems by estimating speech quality during double-talk. However, since the SDR is affected by both speech distortion and residual-echo presence, it does not correlate well with human ratings according to the DNSMOS. To address that, we introduce two objective metrics to separately quantify the desired-speech maintained level (DSML) and residual-echo suppression level (RESL) during double-talk. These metrics are evaluated using a deep learning-based RES-system with a tunable design parameter. Using 280 hours of real and simulated recordings, we show that the DSML and RESL correlate well with the DNSMOS with high generalization to various setups. Also, we empirically investigate the relation between tuning the RES-system design parameter and the DSML-RESL tradeoff it creates and offer a practical design scheme for dynamic system requirements.
Multiclass Permanent Magnets Superstructure for Indoor Localization using Artificial Intelligence
Jul 14, 2021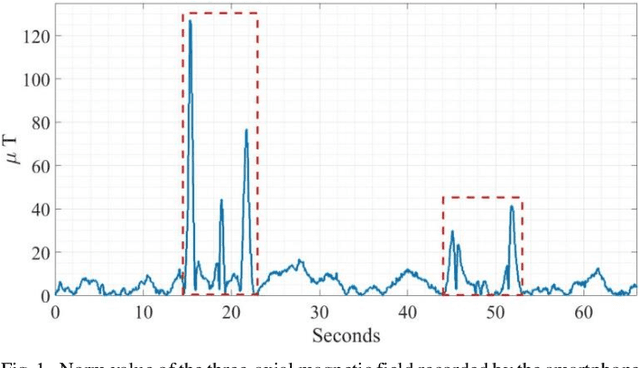
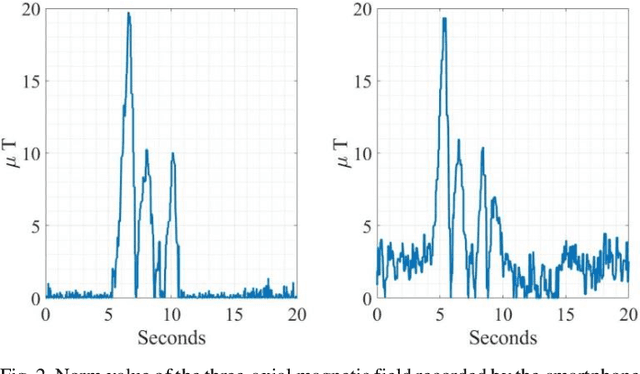
Smartphones have become a popular tool for indoor localization and position estimation of users. Existing solutions mainly employ Wi-Fi, RFID, and magnetic sensing techniques to track movements in crowded venues. These are highly sensitive to magnetic clutters and depend on local ambient magnetic fields, which frequently degrades their performance. Also, these techniques often require pre-known mapping surveys of the area, or the presence of active beacons, which are not always available. We embed small-volume and large-moment magnets in pre-known locations and arrange them in specific geometric constellations that create magnetic superstructure patterns of supervised magnetic signatures. These signatures constitute an unambiguous magnetic environment with respect to the moving sensor carrier. The localization algorithm learns the unique patterns of the scattered magnets during training and detects them from the ongoing streaming of data during localization. Our contribution is twofold. First, we deploy passive permanent magnets that do not require a power supply, in contrast to active magnetic transmitters. Second, we perform localization based on smartphone motion rather than on static positioning of the magnetometer. In our previous study, we considered a single superstructure pattern. Here, we present an extended version of that algorithm for multi-superstructure localization, which covers a broader localization area of the user. Experimental results demonstrate localization accuracy of 95% with a mean localization error of less than 1m using artificial intelligence.
* Accepted to IEEE Transactions on Magnetics
Low power in-situ AI Calibration of a 3 Axial Magnetic Sensor
Jun 27, 2021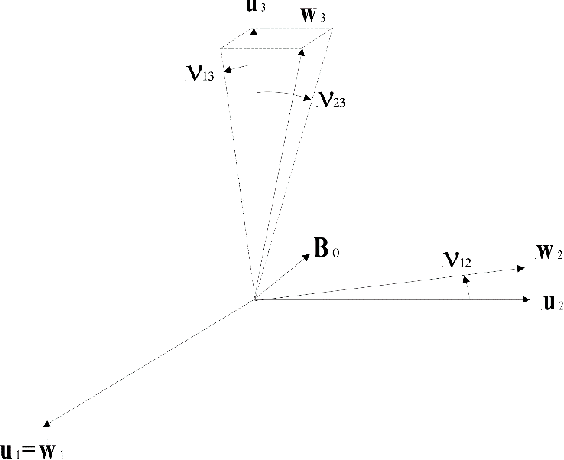
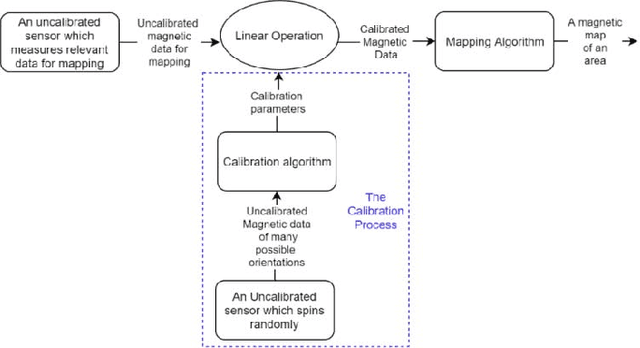
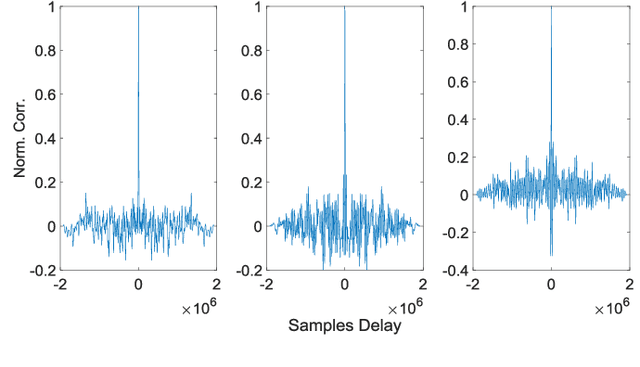
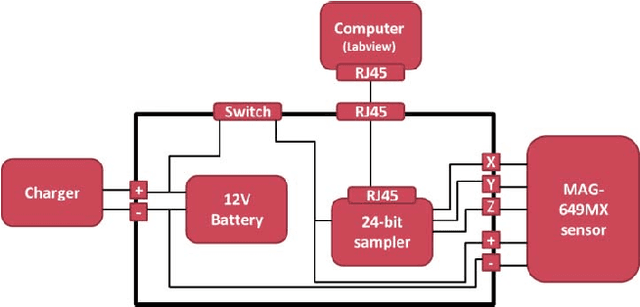
Magnetic surveys are conventionally performed by scanning a domain with a portable scalar magnetic sensor. Unfortunately, scalar magnetometers are expensive, power consuming and bulky. In many applications, calibrated vector magnetometers can be used to perform magnetic surveys. In recent years algorithms based on artificial intelligence (AI) achieve state-of-the-art results in many modern applications. In this work we investigate an AI algorithm for the classical scalar calibration of magnetometers. A simple, low cost method for performing a magnetic survey is presented. The method utilizes a low power consumption sensor with an AI calibration procedure that improves the common calibration methods and suggests an alternative to the conventional technology and algorithms. The setup of the survey system is optimized for quick deployment in-situ right before performing the magnetic survey. We present a calibration method based on a procedure of rotating the sensor in the natural earth magnetic field for an optimal time period. This technique can deal with a constant field offset and non-orthogonality issues and does not require any external reference. The calibration is done by finding an estimator that yields the calibration parameters and produces the best geometric fit to the sensor readings. A comprehensive model considering the physical, algorithmic and hardware properties of the magnetometer of the survey system is presented. The geometric ellipsoid fitting approach is parametrically tested. The calibration procedure reduced the root-mean-squared noise from the order of 104 nT to less than 10 nT with variance lower than 1 nT in a complete 360 degrees rotation in the natural earth magnetic field.
* Accepted to IEEE Transactions On Magnetics