 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleDL: Towards Scalable and Efficient Runtime Prediction for Distributed Deep Learning Workloads
Nov 13, 2025Deep neural networks (DNNs) form the cornerstone of modern AI services, supporting a wide range of applications, including autonomous driving, chatbots, and recommendation systems. As models increase in size and complexity, DNN workloads such as training and inference tasks impose unprecedented demands on distributed computing resources, making accurate runtime prediction essential for optimizing development and resource allocation. Traditional methods rely on additive computational unit models, limiting their accuracy and generalizability. In contrast, graph-enhanced modeling improves performance but significantly increases data collection costs. Therefore, there is a critical need for a method that strikes a balance between accuracy, generalizability, and data collection costs. To address these challenges, we propose ScaleDL, a novel runtime prediction framework that combines nonlinear layer-wise modeling with graph neural network (GNN)-based cross-layer interaction mechanism, enabling accurate DNN runtime prediction and hierarchical generalizability across different network architectures. Additionally, we employ the D-optimal method to reduce data collection costs. Experiments on the workloads of five popular DNN models demonstrate that ScaleDL enhances runtime prediction accuracy and generalizability, achieving 6 times lower MRE and 5 times lower RMSE compared to baseline models.
MetaEformer: Unveiling and Leveraging Meta-patterns for Complex and Dynamic Systems Load Forecasting
Jun 15, 2025Time series forecasting is a critical and practical problem in many real-world applications, especially for industrial scenarios, where load forecasting underpins the intelligent operation of modern systems like clouds, power grids and traffic networks.However, the inherent complexity and dynamics of these systems present significant challenges. Despite advances in methods such as pattern recognition and anti-non-stationarity have led to performance gains, current methods fail to consistently ensure effectiveness across various system scenarios due to the intertwined issues of complex patterns, concept-drift, and few-shot problems. To address these challenges simultaneously, we introduce a novel scheme centered on fundamental waveform, a.k.a., meta-pattern. Specifically, we develop a unique Meta-pattern Pooling mechanism to purify and maintain meta-patterns, capturing the nuanced nature of system loads. Complementing this, the proposed Echo mechanism adaptively leverages the meta-patterns, enabling a flexible and precise pattern reconstruction. Our Meta-pattern Echo transformer (MetaEformer) seamlessly incorporates these mechanisms with the transformer-based predictor, offering end-to-end efficiency and interpretability of core processes. Demonstrating superior performance across eight benchmarks under three system scenarios, MetaEformer marks a significant advantage in accuracy, with a 37% relative improvement on fifteen state-of-the-art baselines.
Sentinel: Scheduling Live Streams with Proactive Anomaly Detection in Crowdsourced Cloud-Edge Platforms
May 29, 2025With the rapid growth of live streaming services, Crowdsourced Cloud-edge service Platforms (CCPs) are playing an increasingly important role in meeting the increasing demand. Although stream scheduling plays a critical role in optimizing CCPs' revenue, most optimization strategies struggle to achieve practical results due to various anomalies in unstable CCPs. Additionally, the substantial scale of CCPs magnifies the difficulties of anomaly detection in time-sensitive scheduling. To tackle these challenges, this paper proposes Sentinel, a proactive anomaly detection-based scheduling framework. Sentinel models the scheduling process as a two-stage Pre-Post-Scheduling paradigm: in the pre-scheduling stage, Sentinel conducts anomaly detection and constructs a strategy pool; in the post-scheduling stage, upon request arrival, it triggers an appropriate scheduling based on a pre-generated strategy to implement the scheduling process. Extensive experiments on realistic datasets show that Sentinel significantly reduces anomaly frequency by 70%, improves revenue by 74%, and doubles the scheduling speed.
One for All: Unified Workload Prediction for Dynamic Multi-tenant Edge Cloud Platforms
Jun 02, 2023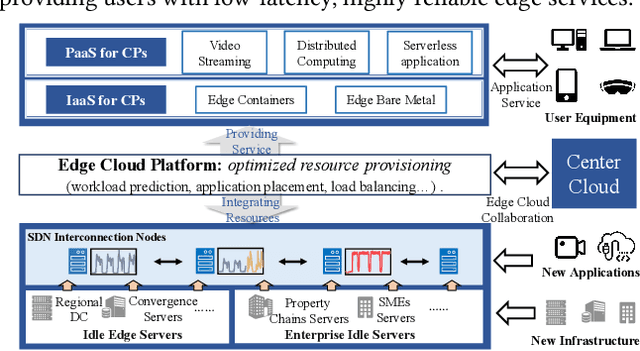
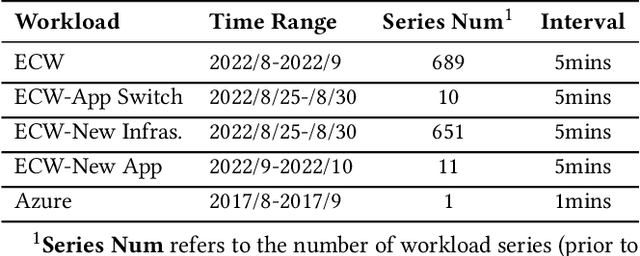
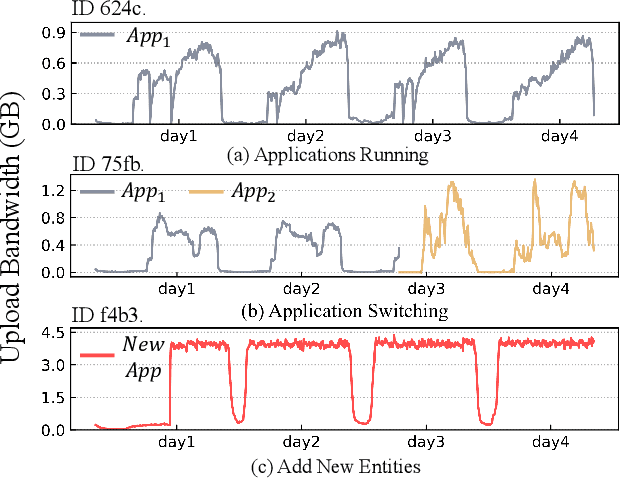
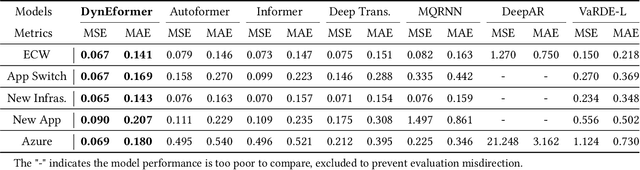
Workload prediction in multi-tenant edge cloud platforms (MT-ECP) is vital for efficient application deployment and resource provisioning. However, the heterogeneous application patterns, variable infrastructure performance, and frequent deployments in MT-ECP pose significant challenges for accurate and efficient workload prediction. Clustering-based methods for dynamic MT-ECP modeling often incur excessive costs due to the need to maintain numerous data clusters and models, which leads to excessive costs. Existing end-to-end time series prediction methods are challenging to provide consistent prediction performance in dynamic MT-ECP. In this paper, we propose an end-to-end framework with global pooling and static content awareness, DynEformer, to provide a unified workload prediction scheme for dynamic MT-ECP. Meticulously designed global pooling and information merging mechanisms can effectively identify and utilize global application patterns to drive local workload predictions. The integration of static content-aware mechanisms enhances model robustness in real-world scenarios. Through experiments on five real-world datasets, DynEformer achieved state-of-the-art in the dynamic scene of MT-ECP and provided a unified end-to-end prediction scheme for MT-ECP.