 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTGBFormer: Transformer-GraphFormer Blender Network for Video Object Detection
Mar 18, 2025Video object detection has made significant progress in recent years thanks to convolutional neural networks (CNNs) and vision transformers (ViTs). Typically, CNNs excel at capturing local features but struggle to model global representations. Conversely, ViTs are adept at capturing long-range global features but face challenges in representing local feature details. Off-the-shelf video object detection methods solely rely on CNNs or ViTs to conduct feature aggregation, which hampers their capability to simultaneously leverage global and local information, thereby resulting in limited detection performance. In this paper, we propose a Transformer-GraphFormer Blender Network (TGBFormer) for video object detection, with three key technical improvements to fully exploit the advantages of transformers and graph convolutional networks while compensating for their limitations. First, we develop a spatial-temporal transformer module to aggregate global contextual information, constituting global representations with long-range feature dependencies. Second, we introduce a spatial-temporal GraphFormer module that utilizes local spatial and temporal relationships to aggregate features, generating new local representations that are complementary to the transformer outputs. Third, we design a global-local feature blender module to adaptively couple transformer-based global representations and GraphFormer-based local representations. Extensive experiments demonstrate that our TGBFormer establishes new state-of-the-art results on the ImageNet VID dataset. Particularly, our TGBFormer achieves 86.5% mAP while running at around 41.0 FPS on a single Tesla A100 GPU.
DehazeMamba: SAR-guided Optical Remote Sensing Image Dehazing with Adaptive State Space Model
Mar 17, 2025



Optical remote sensing image dehazing presents significant challenges due to its extensive spatial scale and highly non-uniform haze distribution, which traditional single-image dehazing methods struggle to address effectively. While Synthetic Aperture Radar (SAR) imagery offers inherently haze-free reference information for large-scale scenes, existing SAR-guided dehazing approaches face two critical limitations: the integration of SAR information often diminishes the quality of haze-free regions, and the instability of feature quality further exacerbates cross-modal domain shift. To overcome these challenges, we introduce DehazeMamba, a novel SAR-guided dehazing network built on a progressive haze decoupling fusion strategy. Our approach incorporates two key innovations: a Haze Perception and Decoupling Module (HPDM) that dynamically identifies haze-affected regions through optical-SAR difference analysis, and a Progressive Fusion Module (PFM) that mitigates domain shift through a two-stage fusion process based on feature quality assessment. To facilitate research in this domain, we present MRSHaze, a large-scale benchmark dataset comprising 8,000 pairs of temporally synchronized, precisely geo-registered SAR-optical images with high resolution and diverse haze conditions. Extensive experiments demonstrate that DehazeMamba significantly outperforms state-of-the-art methods, achieving a 0.73 dB improvement in PSNR and substantial enhancements in downstream tasks such as semantic segmentation. The dataset is available at https://github.com/mmic-lcl/Datasets-and-benchmark-code.
AdaReTaKe: Adaptive Redundancy Reduction to Perceive Longer for Video-language Understanding
Mar 16, 2025Multimodal Large Language Models (MLLMs) have revolutionized video understanding, yet are still limited by context length when processing long videos. Recent methods compress videos by leveraging visual redundancy uniformly, yielding promising results. Nevertheless, our quantitative analysis shows that redundancy varies significantly across time and model layers, necessitating a more flexible compression strategy. We propose AdaReTaKe, a training-free method that flexibly reduces visual redundancy by allocating compression ratios among time and layers with theoretical guarantees. Integrated into state-of-the-art MLLMs, AdaReTaKe improves processing capacity from 256 to 2048 frames while preserving critical information. Experiments on VideoMME, MLVU, LongVideoBench, and LVBench datasets demonstrate that AdaReTaKe outperforms existing methods by 2.3% and 2.8% for 7B and 72B models, respectively, with even greater improvements of 5.9% and 6.0% on the longest LVBench. Our code is available at https://github.com/SCZwangxiao/video-FlexReduc.git.
CAD-VAE: Leveraging Correlation-Aware Latents for Comprehensive Fair Disentanglement
Mar 11, 2025



While deep generative models have significantly advanced representation learning, they may inherit or amplify biases and fairness issues by encoding sensitive attributes alongside predictive features. Enforcing strict independence in disentanglement is often unrealistic when target and sensitive factors are naturally correlated. To address this challenge, we propose CAD-VAE (Correlation-Aware Disentangled VAE), which introduces a correlated latent code to capture the shared information between target and sensitive attributes. Given this correlated latent, our method effectively separates overlapping factors without extra domain knowledge by directly minimizing the conditional mutual information between target and sensitive codes. A relevance-driven optimization strategy refines the correlated code by efficiently capturing essential correlated features and eliminating redundancy. Extensive experiments on benchmark datasets demonstrate that CAD-VAE produces fairer representations, realistic counterfactuals, and improved fairness-aware image editing.
Large Language Model Guided Progressive Feature Alignment for Multimodal UAV Object Detection
Mar 10, 2025



Existing multimodal UAV object detection methods often overlook the impact of semantic gaps between modalities, which makes it difficult to achieve accurate semantic and spatial alignments, limiting detection performance. To address this problem, we propose a Large Language Model (LLM) guided Progressive feature Alignment Network called LPANet, which leverages the semantic features extracted from a large language model to guide the progressive semantic and spatial alignment between modalities for multimodal UAV object detection. To employ the powerful semantic representation of LLM, we generate the fine-grained text descriptions of each object category by ChatGPT and then extract the semantic features using the large language model MPNet. Based on the semantic features, we guide the semantic and spatial alignments in a progressive manner as follows. First, we design the Semantic Alignment Module (SAM) to pull the semantic features and multimodal visual features of each object closer, alleviating the semantic differences of objects between modalities. Second, we design the Explicit Spatial alignment Module (ESM) by integrating the semantic relations into the estimation of feature-level offsets, alleviating the coarse spatial misalignment between modalities. Finally, we design the Implicit Spatial alignment Module (ISM), which leverages the cross-modal correlations to aggregate key features from neighboring regions to achieve implicit spatial alignment. Comprehensive experiments on two public multimodal UAV object detection datasets demonstrate that our approach outperforms state-of-the-art multimodal UAV object detectors.
Sign Language Translation using Frame and Event Stream: Benchmark Dataset and Algorithms
Mar 09, 2025Accurate sign language understanding serves as a crucial communication channel for individuals with disabilities. Current sign language translation algorithms predominantly rely on RGB frames, which may be limited by fixed frame rates, variable lighting conditions, and motion blur caused by rapid hand movements. Inspired by the recent successful application of event cameras in other fields, we propose to leverage event streams to assist RGB cameras in capturing gesture data, addressing the various challenges mentioned above. Specifically, we first collect a large-scale RGB-Event sign language translation dataset using the DVS346 camera, termed VECSL, which contains 15,676 RGB-Event samples, 15,191 glosses, and covers 2,568 Chinese characters. These samples were gathered across a diverse range of indoor and outdoor environments, capturing multiple viewing angles, varying light intensities, and different camera motions. Due to the absence of benchmark algorithms for comparison in this new task, we retrained and evaluated multiple state-of-the-art SLT algorithms, and believe that this benchmark can effectively support subsequent related research. Additionally, we propose a novel RGB-Event sign language translation framework (i.e., M$^2$-SLT) that incorporates fine-grained micro-sign and coarse-grained macro-sign retrieval, achieving state-of-the-art results on the proposed dataset. Both the source code and dataset will be released on https://github.com/Event-AHU/OpenESL.
AutoMisty: A Multi-Agent LLM Framework for Automated Code Generation in the Misty Social Robot
Mar 09, 2025The social robot's open API allows users to customize open-domain interactions. However, it remains inaccessible to those without programming experience. In this work, we introduce AutoMisty, the first multi-agent collaboration framework powered by large language models (LLMs), to enable the seamless generation of executable Misty robot code from natural language instructions. AutoMisty incorporates four specialized agent modules to manage task decomposition, assignment, problem-solving, and result synthesis. Each agent incorporates a two-layer optimization mechanism, with self-reflection for iterative refinement and human-in-the-loop for better alignment with user preferences. AutoMisty ensures a transparent reasoning process, allowing users to iteratively refine tasks through natural language feedback for precise execution. To evaluate AutoMisty's effectiveness, we designed a benchmark task set spanning four levels of complexity and conducted experiments in a real Misty robot environment. Extensive evaluations demonstrate that AutoMisty not only consistently generates high-quality code but also enables precise code control, significantly outperforming direct reasoning with ChatGPT-4o and ChatGPT-o1. All code, optimized APIs, and experimental videos will be publicly released through the webpage: https://wangxiaoshawn.github.io/AutoMisty.html
Biomedical Foundation Model: A Survey
Mar 03, 2025Foundation models, first introduced in 2021, are large-scale pre-trained models (e.g., large language models (LLMs) and vision-language models (VLMs)) that learn from extensive unlabeled datasets through unsupervised methods, enabling them to excel in diverse downstream tasks. These models, like GPT, can be adapted to various applications such as question answering and visual understanding, outperforming task-specific AI models and earning their name due to broad applicability across fields. The development of biomedical foundation models marks a significant milestone in leveraging artificial intelligence (AI) to understand complex biological phenomena and advance medical research and practice. This survey explores the potential of foundation models across diverse domains within biomedical fields, including computational biology, drug discovery and development, clinical informatics, medical imaging, and public health. The purpose of this survey is to inspire ongoing research in the application of foundation models to health science.
HAIC: Improving Human Action Understanding and Generation with Better Captions for Multi-modal Large Language Models
Feb 28, 2025

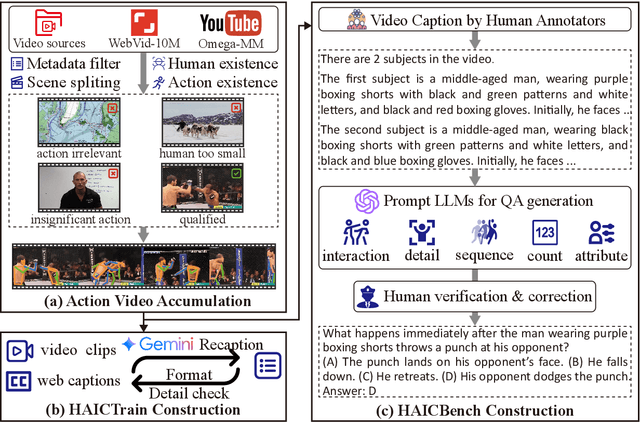
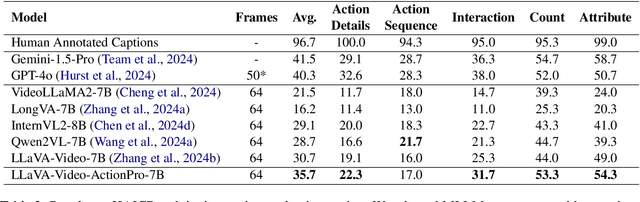
Recent Multi-modal Large Language Models (MLLMs) have made great progress in video understanding. However, their performance on videos involving human actions is still limited by the lack of high-quality data. To address this, we introduce a two-stage data annotation pipeline. First, we design strategies to accumulate videos featuring clear human actions from the Internet. Second, videos are annotated in a standardized caption format that uses human attributes to distinguish individuals and chronologically details their actions and interactions. Through this pipeline, we curate two datasets, namely HAICTrain and HAICBench. \textbf{HAICTrain} comprises 126K video-caption pairs generated by Gemini-Pro and verified for training purposes. Meanwhile, \textbf{HAICBench} includes 500 manually annotated video-caption pairs and 1,400 QA pairs, for a comprehensive evaluation of human action understanding. Experimental results demonstrate that training with HAICTrain not only significantly enhances human understanding abilities across 4 benchmarks, but can also improve text-to-video generation results. Both the HAICTrain and HAICBench are released at https://huggingface.co/datasets/KuaishouHAIC/HAIC.
Langevin Multiplicative Weights Update with Applications in Polynomial Portfolio Management
Feb 26, 2025



We consider nonconvex optimization problem over simplex, and more generally, a product of simplices. We provide an algorithm, Langevin Multiplicative Weights Update (LMWU) for solving global optimization problems by adding a noise scaling with the non-Euclidean geometry in the simplex. Non-convex optimization has been extensively studied by machine learning community due to its application in various scenarios such as neural network approximation and finding Nash equilibrium. Despite recent progresses on provable guarantee of escaping and avoiding saddle point (convergence to local minima) and global convergence of Langevin gradient based method without constraints, the global optimization with constraints is less studied. We show that LMWU algorithm is provably convergent to interior global minima with a non-asymptotic convergence analysis. We verify the efficiency of the proposed algorithm in real data set from polynomial portfolio management, where optimization of a highly non-linear objective function plays a crucial role.