 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Multi-model Online Conformal Prediction
Jan 04, 2026Conformal prediction is a framework for uncertainty quantification that constructs prediction sets for previously unseen data, guaranteeing coverage of the true label with a specified probability. However, the efficiency of these prediction sets, measured by their size, depends on the choice of the underlying learning model. Relying on a single fixed model may lead to suboptimal performance in online environments, as a single model may not consistently perform well across all time steps. To mitigate this, prior work has explored selecting a model from a set of candidates. However, this approach becomes computationally expensive as the number of candidate models increases. Moreover, poorly performing models in the set may also hinder the effectiveness. To tackle this challenge, this work develops a novel multi-model online conformal prediction algorithm that reduces computational complexity and improves prediction efficiency. At each time step, a bipartite graph is generated to identify a subset of effective models, from which a model is selected to construct the prediction set. Experiments demonstrate that our method outperforms existing multi-model conformal prediction techniques in terms of both prediction set size and computational efficiency.
Topology Identification and Inference over Graphs
Dec 11, 2025
Topology identification and inference of processes evolving over graphs arise in timely applications involving brain, transportation, financial, power, as well as social and information networks. This chapter provides an overview of graph topology identification and statistical inference methods for multidimensional relational data. Approaches for undirected links connecting graph nodes are outlined, going all the way from correlation metrics to covariance selection, and revealing ties with smooth signal priors. To account for directional (possibly causal) relations among nodal variables and address the limitations of linear time-invariant models in handling dynamic as well as nonlinear dependencies, a principled framework is surveyed to capture these complexities through judiciously selected kernels from a prescribed dictionary. Generalizations are also described via structural equations and vector autoregressions that can exploit attributes such as low rank, sparsity, acyclicity, and smoothness to model dynamic processes over possibly time-evolving topologies. It is argued that this approach supports both batch and online learning algorithms with convergence rate guarantees, is amenable to tensor (that is, multi-way array) formulations as well as decompositions that are well-suited for multidimensional network data, and can seamlessly leverage high-order statistical information.
Deploying AI for Signal Processing education: Selected challenges and intriguing opportunities
Sep 10, 2025Powerful artificial intelligence (AI) tools that have emerged in recent years -- including large language models, automated coding assistants, and advanced image and speech generation technologies -- are the result of monumental human achievements. These breakthroughs reflect mastery across multiple technical disciplines and the resolution of significant technological challenges. However, some of the most profound challenges may still lie ahead. These challenges are not purely technical but pertain to the fair and responsible use of AI in ways that genuinely improve the global human condition. This article explores one promising application aligned with that vision: the use of AI tools to facilitate and enhance education, with a specific focus on signal processing (SP). It presents two interrelated perspectives: identifying and addressing technical limitations, and applying AI tools in practice to improve educational experiences. Primers are provided on several core technical issues that arise when using AI in educational settings, including how to ensure fairness and inclusivity, handle hallucinated outputs, and achieve efficient use of resources. These and other considerations -- such as transparency, explainability, and trustworthiness -- are illustrated through the development of an immersive, structured, and reliable "smart textbook." The article serves as a resource for researchers and educators seeking to advance AI's role in engineering education.
Online Learning and Coverage of Unknown Fields Using Random-Feature Gaussian Processes
Sep 09, 2025This paper proposes a framework for multi-robot systems to perform simultaneous learning and coverage of the domain of interest characterized by an unknown and potentially time-varying density function. To overcome the limitations of Gaussian Process (GP) regression, we employ Random Feature GP (RFGP) and its online variant (O-RFGP) that enables online and incremental inference. By integrating these with Voronoi-based coverage control and Upper Confidence Bound (UCB) sampling strategy, a team of robots can adaptively focus on important regions while refining the learned spatial field for efficient coverage. Under mild assumptions, we provide theoretical guarantees and evaluate the framework through simulations in time-invariant scenarios. Furthermore, its effectiveness in time-varying settings is demonstrated through additional simulations and a physical experiment.
Graph-Structured Feedback Multimodel Ensemble Online Conformal Prediction
Jun 26, 2025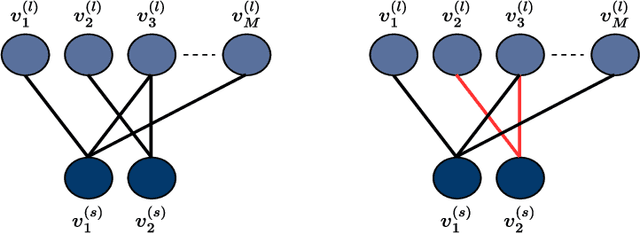
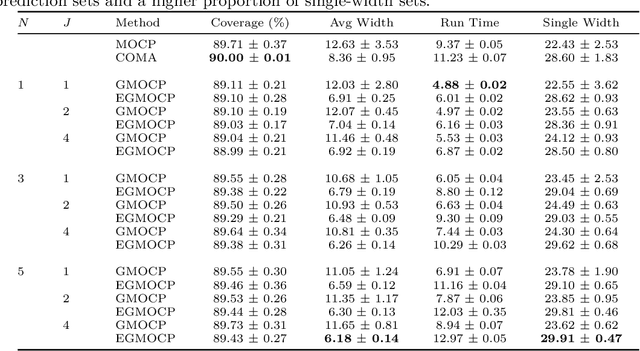
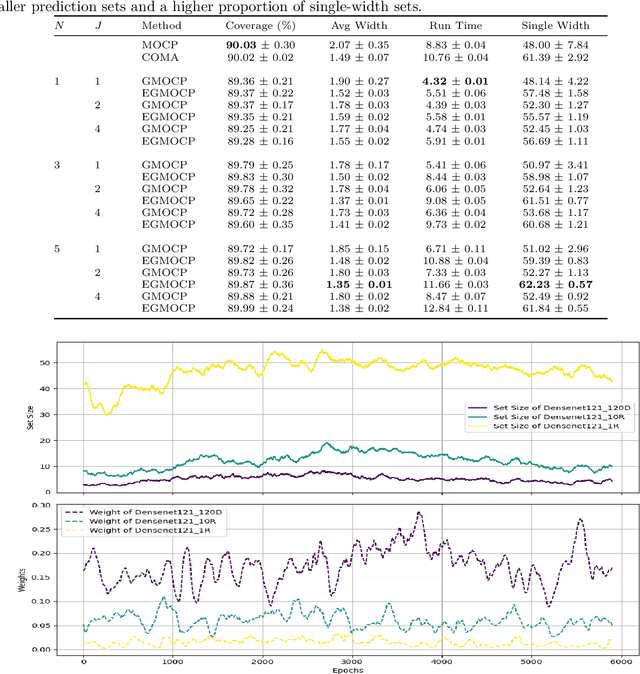
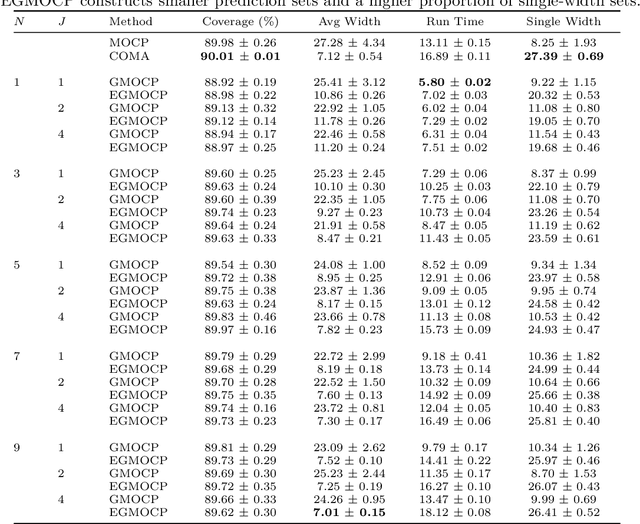
Online conformal prediction has demonstrated its capability to construct a prediction set for each incoming data point that covers the true label with a predetermined probability. To cope with potential distribution shift, multi-model online conformal prediction has been introduced to select and leverage different models from a preselected candidate set. Along with the improved flexibility, the choice of the preselected set also brings challenges. A candidate set that includes a large number of models may increase the computational complexity. In addition, the inclusion of irrelevant models with poor performance may negatively impact the performance and lead to unnecessarily large prediction sets. To address these challenges, we propose a novel multi-model online conformal prediction algorithm that identifies a subset of effective models at each time step by collecting feedback from a bipartite graph, which is refined upon receiving new data. A model is then selected from this subset to construct the prediction set, resulting in reduced computational complexity and smaller prediction sets. Additionally, we demonstrate that using prediction set size as feedback, alongside model loss, can significantly improve efficiency by constructing smaller prediction sets while still satisfying the required coverage guarantee. The proposed algorithms are proven to ensure valid coverage and achieve sublinear regret. Experiments on real and synthetic datasets validate that the proposed methods construct smaller prediction sets and outperform existing multi-model online conformal prediction approaches.
Is Noise Conditioning Necessary? A Unified Theory of Unconditional Graph Diffusion Models
May 28, 2025Explicit noise-level conditioning is widely regarded as essential for the effective operation of Graph Diffusion Models (GDMs). In this work, we challenge this assumption by investigating whether denoisers can implicitly infer noise levels directly from corrupted graph structures, potentially eliminating the need for explicit noise conditioning. To this end, we develop a theoretical framework centered on Bernoulli edge-flip corruptions and extend it to encompass more complex scenarios involving coupled structure-attribute noise. Extensive empirical evaluations on both synthetic and real-world graph datasets, using models such as GDSS and DiGress, provide strong support for our theoretical findings. Notably, unconditional GDMs achieve performance comparable or superior to their conditioned counterparts, while also offering reductions in parameters (4-6%) and computation time (8-10%). Our results suggest that the high-dimensional nature of graph data itself often encodes sufficient information for the denoising process, opening avenues for simpler, more efficient GDM architectures.
Beyond Editing Pairs: Fine-Grained Instructional Image Editing via Multi-Scale Learnable Regions
May 25, 2025



Current text-driven image editing methods typically follow one of two directions: relying on large-scale, high-quality editing pair datasets to improve editing precision and diversity, or exploring alternative dataset-free techniques. However, constructing large-scale editing datasets requires carefully designed pipelines, is time-consuming, and often results in unrealistic samples or unwanted artifacts. Meanwhile, dataset-free methods may suffer from limited instruction comprehension and restricted editing capabilities. Faced with these challenges, the present work develops a novel paradigm for instruction-driven image editing that leverages widely available and enormous text-image pairs, instead of relying on editing pair datasets. Our approach introduces a multi-scale learnable region to localize and guide the editing process. By treating the alignment between images and their textual descriptions as supervision and learning to generate task-specific editing regions, our method achieves high-fidelity, precise, and instruction-consistent image editing. Extensive experiments demonstrate that the proposed approach attains state-of-the-art performance across various tasks and benchmarks, while exhibiting strong adaptability to various types of generative models.
Unlearning Algorithmic Biases over Graphs
May 20, 2025



The growing enforcement of the right to be forgotten regulations has propelled recent advances in certified (graph) unlearning strategies to comply with data removal requests from deployed machine learning (ML) models. Motivated by the well-documented bias amplification predicament inherent to graph data, here we take a fresh look at graph unlearning and leverage it as a bias mitigation tool. Given a pre-trained graph ML model, we develop a training-free unlearning procedure that offers certifiable bias mitigation via a single-step Newton update on the model weights. This way, we contribute a computationally lightweight alternative to the prevalent training- and optimization-based fairness enhancement approaches, with quantifiable performance guarantees. We first develop a novel fairness-aware nodal feature unlearning strategy along with refined certified unlearning bounds for this setting, whose impact extends beyond the realm of graph unlearning. We then design structural unlearning methods endowed with principled selection mechanisms over nodes and edges informed by rigorous bias analyses. Unlearning these judiciously selected elements can mitigate algorithmic biases with minimal impact on downstream utility (e.g., node classification accuracy). Experimental results over real networks corroborate the bias mitigation efficacy of our unlearning strategies, and delineate markedly favorable utility-complexity trade-offs relative to retraining from scratch using augmented graph data obtained via removals.
FairZK: A Scalable System to Prove Machine Learning Fairness in Zero-Knowledge
May 19, 2025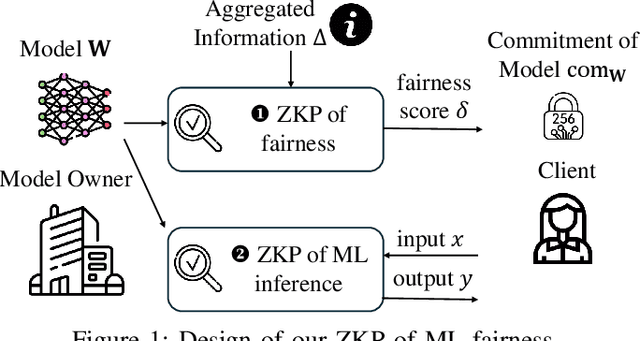

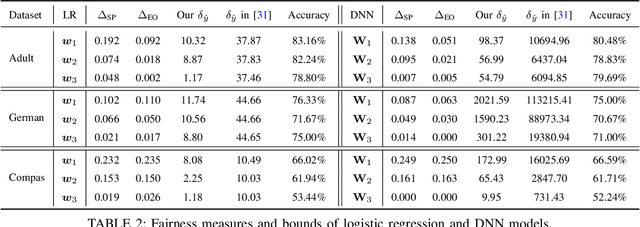
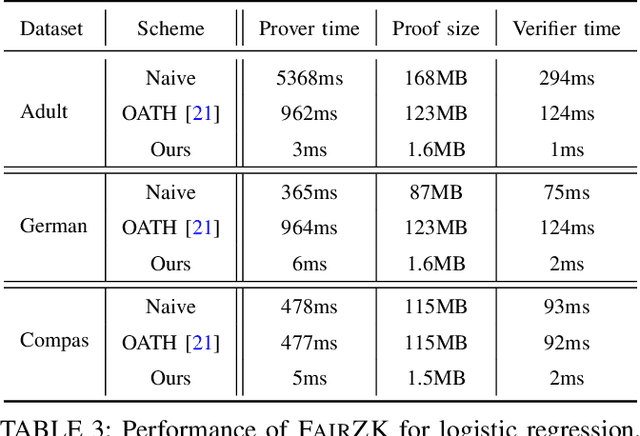
With the rise of machine learning techniques, ensuring the fairness of decisions made by machine learning algorithms has become of great importance in critical applications. However, measuring fairness often requires full access to the model parameters, which compromises the confidentiality of the models. In this paper, we propose a solution using zero-knowledge proofs, which allows the model owner to convince the public that a machine learning model is fair while preserving the secrecy of the model. To circumvent the efficiency barrier of naively proving machine learning inferences in zero-knowledge, our key innovation is a new approach to measure fairness only with model parameters and some aggregated information of the input, but not on any specific dataset. To achieve this goal, we derive new bounds for the fairness of logistic regression and deep neural network models that are tighter and better reflecting the fairness compared to prior work. Moreover, we develop efficient zero-knowledge proof protocols for common computations involved in measuring fairness, including the spectral norm of matrices, maximum, absolute value, and fixed-point arithmetic. We have fully implemented our system, FairZK, that proves machine learning fairness in zero-knowledge. Experimental results show that FairZK is significantly faster than the naive approach and an existing scheme that use zero-knowledge inferences as a subroutine. The prover time is improved by 3.1x--1789x depending on the size of the model and the dataset. FairZK can scale to a large model with 47 million parameters for the first time, and generates a proof for its fairness in 343 seconds. This is estimated to be 4 orders of magnitude faster than existing schemes, which only scale to small models with hundreds to thousands of parameters.
A Scalable System to Prove Machine Learning Fairness in Zero-Knowledge
May 12, 2025With the rise of machine learning techniques, ensuring the fairness of decisions made by machine learning algorithms has become of great importance in critical applications. However, measuring fairness often requires full access to the model parameters, which compromises the confidentiality of the models. In this paper, we propose a solution using zero-knowledge proofs, which allows the model owner to convince the public that a machine learning model is fair while preserving the secrecy of the model. To circumvent the efficiency barrier of naively proving machine learning inferences in zero-knowledge, our key innovation is a new approach to measure fairness only with model parameters and some aggregated information of the input, but not on any specific dataset. To achieve this goal, we derive new bounds for the fairness of logistic regression and deep neural network models that are tighter and better reflecting the fairness compared to prior work. Moreover, we develop efficient zero-knowledge proof protocols for common computations involved in measuring fairness, including the spectral norm of matrices, maximum, absolute value, and fixed-point arithmetic. We have fully implemented our system, FairZK, that proves machine learning fairness in zero-knowledge. Experimental results show that FairZK is significantly faster than the naive approach and an existing scheme that use zero-knowledge inferences as a subroutine. The prover time is improved by 3.1x--1789x depending on the size of the model and the dataset. FairZK can scale to a large model with 47 million parameters for the first time, and generates a proof for its fairness in 343 seconds. This is estimated to be 4 orders of magnitude faster than existing schemes, which only scale to small models with hundreds to thousands of parameters.