 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneReason Technical Report
Jun 04, 2026Generative recommendation models in the OneRec family have been widely deployed in many real-world services, such as short-video, live-streaming, advertising, and e-commerce. However, these generative models can only benefit from the scaling advantage, while their reasoning ability is hard to activate, since we cannot construct meaningful Chain-of-Thought (CoT) sequences consisting of itemic tokens only. Inspired by the success of the reasoning-style ``think before answer'' paradigm in the LLM field, we conduct preliminary studies (i.e., OneRec-Think, OpenOneRec) to explore reasoning capability in generative recommendation. Nevertheless, we notice an unexpected phenomenon: the thinking mode does not show advantages over the non-thinking mode. Drawing insights from recent findings on CoT robustness in multi-modal language models, we argue that effective reasoning in recommendation rests on two factors: perception, the ability to ground itemic tokens in their underlying language semantics, and cognition, the ability to reorganize a user's behavior sequence into coherent latent interest points. We therefore propose OneReason, which includes: (1) strong itemic token perception in pre-training, (2) a three-level cognition-enhanced CoT format for recommendation tasks in SFT, and (3) a specialize-then-unify training recipe in RL to enhance the thinking ability.
Kwai Summary Attention Technical Report
Apr 27, 2026Long-context ability, has become one of the most important iteration direction of next-generation Large Language Models, particularly in semantic understanding/reasoning, code agentic intelligence and recommendation system. However, the standard softmax attention exhibits quadratic time complexity with respect to sequence length. As the sequence length increases, this incurs substantial overhead in long-context settings, leading the training and inference costs of extremely long sequences deteriorate rapidly. Existing solutions mitigate this issue through two technique routings: i) Reducing the KV cache per layer, such as from the head-level compression GQA, and the embedding dimension-level compression MLA, but the KV cache remains linearly dependent on the sequence length at a 1:1 ratio. ii) Interleaving with KV Cache friendly architecture, such as local attention SWA, linear kernel GDN, but often involve trade-offs among KV Cache and long-context modeling effectiveness. Besides the two technique routings, we argue that there exists an intermediate path not well explored: {Maintaining a linear relationship between the KV cache and sequence length, but performing semantic-level compression through a specific ratio $k$}. This $O(n/k)$ path does not pursue a ``minimum KV cache'', but rather trades acceptable memory costs for complete, referential, and interpretable retention of long distant dependency. Motivated by this, we propose Kwai Summary Attention (KSA), a novel attention mechanism that reduces sequence modeling cost by compressing historical contexts into learnable summary tokens.
Kelix Technical Report
Feb 12, 2026Autoregressive large language models (LLMs) scale well by expressing diverse tasks as sequences of discrete natural-language tokens and training with next-token prediction, which unifies comprehension and generation under self-supervision. Extending this paradigm to multimodal data requires a shared, discrete representation across modalities. However, most vision-language models (VLMs) still rely on a hybrid interface: discrete text tokens paired with continuous Vision Transformer (ViT) features. Because supervision is largely text-driven, these models are often biased toward understanding and cannot fully leverage large-scale self-supervised learning on non-text data. Recent work has explored discrete visual tokenization to enable fully autoregressive multimodal modeling, showing promising progress toward unified understanding and generation. Yet existing discrete vision tokens frequently lose information due to limited code capacity, resulting in noticeably weaker understanding than continuous-feature VLMs. We present Kelix, a fully discrete autoregressive unified model that closes the understanding gap between discrete and continuous visual representations.
Improving Knowledge Graph Embedding Using Simple Constraints
May 08, 2018
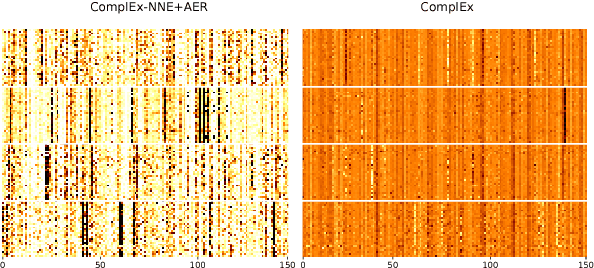
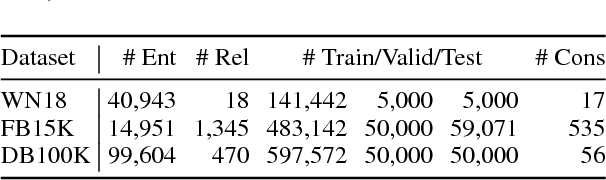
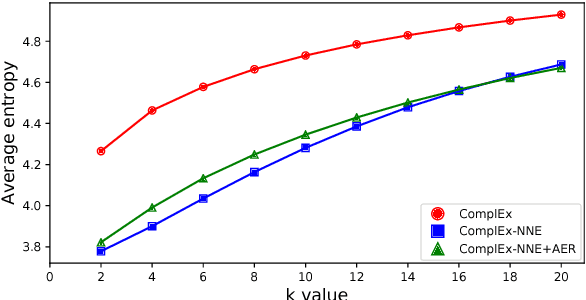
Embedding knowledge graphs (KGs) into continuous vector spaces is a focus of current research. Early works performed this task via simple models developed over KG triples. Recent attempts focused on either designing more complicated triple scoring models, or incorporating extra information beyond triples. This paper, by contrast, investigates the potential of using very simple constraints to improve KG embedding. We examine non-negativity constraints on entity representations and approximate entailment constraints on relation representations. The former help to learn compact and interpretable representations for entities. The latter further encode regularities of logical entailment between relations into their distributed representations. These constraints impose prior beliefs upon the structure of the embedding space, without negative impacts on efficiency or scalability. Evaluation on WordNet, Freebase, and DBpedia shows that our approach is simple yet surprisingly effective, significantly and consistently outperforming competitive baselines. The constraints imposed indeed improve model interpretability, leading to a substantially increased structuring of the embedding space. Code and data are available at https://github.com/iieir-km/ComplEx-NNE_AER.