 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular 3D Lane Detection via Structure Uncertainty-Aware Network with Curve-Point Queries
Nov 17, 2025Monocular 3D lane detection is challenged by aleatoric uncertainty arising from inherent observation noise. Existing methods rely on simplified geometric assumptions, such as independent point predictions or global planar modeling, failing to capture structural variations and aleatoric uncertainty in real-world scenarios. In this paper, we propose MonoUnc, a bird's-eye view (BEV)-free 3D lane detector that explicitly models aleatoric uncertainty informed by local lane structures. Specifically, 3D lanes are projected onto the front-view (FV) space and approximated by parametric curves. Guided by curve predictions, curve-point query embeddings are dynamically generated for lane point predictions in 3D space. Each segment formed by two adjacent points is modeled as a 3D Gaussian, parameterized by the local structure and uncertainty estimations. Accordingly, a novel 3D Gaussian matching loss is designed to constrain these parameters jointly. Experiments on the ONCE-3DLanes and OpenLane datasets demonstrate that MonoUnc outperforms previous state-of-the-art (SoTA) methods across all benchmarks under stricter evaluation criteria. Additionally, we propose two comprehensive evaluation metrics for ONCE-3DLanes, calculating the average and maximum bidirectional Chamfer distances to quantify global and local errors. Codes are released at https://github.com/lrx02/MonoUnc.
TableLoRA: Low-rank Adaptation on Table Structure Understanding for Large Language Models
Mar 06, 2025



Tabular data are crucial in many fields and their understanding by large language models (LLMs) under high parameter efficiency paradigm is important. However, directly applying parameter-efficient fine-tuning (PEFT) techniques to tabular tasks presents significant challenges, particularly in terms of better table serialization and the representation of two-dimensional structured information within a one-dimensional sequence. To address this, we propose TableLoRA, a module designed to improve LLMs' understanding of table structure during PEFT. It incorporates special tokens for serializing tables with special token encoder and uses 2D LoRA to encode low-rank information on cell positions. Experiments on four tabular-related datasets demonstrate that TableLoRA consistently outperforms vanilla LoRA and surpasses various table encoding methods tested in control experiments. These findings reveal that TableLoRA, as a table-specific LoRA, enhances the ability of LLMs to process tabular data effectively, especially in low-parameter settings, demonstrating its potential as a robust solution for handling table-related tasks.
Flexible 3D Lane Detection by Hierarchical Shape MatchingFlexible 3D Lane Detection by Hierarchical Shape Matching
Aug 13, 2024



As one of the basic while vital technologies for HD map construction, 3D lane detection is still an open problem due to varying visual conditions, complex typologies, and strict demands for precision. In this paper, an end-to-end flexible and hierarchical lane detector is proposed to precisely predict 3D lane lines from point clouds. Specifically, we design a hierarchical network predicting flexible representations of lane shapes at different levels, simultaneously collecting global instance semantics and avoiding local errors. In the global scope, we propose to regress parametric curves w.r.t adaptive axes that help to make more robust predictions towards complex scenes, while in the local vision the structure of lane segment is detected in each of the dynamic anchor cells sampled along the global predicted curves. Moreover, corresponding global and local shape matching losses and anchor cell generation strategies are designed. Experiments on two datasets show that we overwhelm current top methods under high precision standards, and full ablation studies also verify each part of our method. Our codes will be released at https://github.com/Doo-do/FHLD.
CONLINE: Complex Code Generation and Refinement with Online Searching and Correctness Testing
Mar 20, 2024Large Language Models (LLMs) have revolutionized code generation ability by converting natural language descriptions into executable code. However, generating complex code within real-world scenarios remains challenging due to intricate structures, subtle bugs, understanding of advanced data types, and lack of supplementary contents. To address these challenges, we introduce the CONLINE framework, which enhances code generation by incorporating planned online searches for information retrieval and automated correctness testing for iterative refinement. CONLINE also serializes the complex inputs and outputs to improve comprehension and generate test case to ensure the framework's adaptability for real-world applications. CONLINE is validated through rigorous experiments on the DS-1000 and ClassEval datasets. It shows that CONLINE substantially improves the quality of complex code generation, highlighting its potential to enhance the practicality and reliability of LLMs in generating intricate code.
CoSSegGaussians: Compact and Swift Scene Segmenting 3D Gaussians with Dual Feature Fusion
Jan 30, 2024We propose Compact and Swift Segmenting 3D Gaussians(CoSSegGaussians), a method for compact 3D-consistent scene segmentation at fast rendering speed with only RGB images input. Previous NeRF-based segmentation methods have relied on time-consuming neural scene optimization. While recent 3D Gaussian Splatting has notably improved speed, existing Gaussian-based segmentation methods struggle to produce compact masks, especially in zero-shot segmentation. This issue probably stems from their straightforward assignment of learnable parameters to each Gaussian, resulting in a lack of robustness against cross-view inconsistent 2D machine-generated labels. Our method aims to address this problem by employing Dual Feature Fusion Network as Gaussians' segmentation field. Specifically, we first optimize 3D Gaussians under RGB supervision. After Gaussian Locating, DINO features extracted from images are applied through explicit unprojection, which are further incorporated with spatial features from the efficient point cloud processing network. Feature aggregation is utilized to fuse them in a global-to-local strategy for compact segmentation features. Experimental results show that our model outperforms baselines on both semantic and panoptic zero-shot segmentation task, meanwhile consumes less than 10% inference time compared to NeRF-based methods. Code and more results will be available at https://David-Dou.github.io/CoSSegGaussians
Text2Analysis: A Benchmark of Table Question Answering with Advanced Data Analysis and Unclear Queries
Dec 21, 2023Tabular data analysis is crucial in various fields, and large language models show promise in this area. However, current research mostly focuses on rudimentary tasks like Text2SQL and TableQA, neglecting advanced analysis like forecasting and chart generation. To address this gap, we developed the Text2Analysis benchmark, incorporating advanced analysis tasks that go beyond the SQL-compatible operations and require more in-depth analysis. We also develop five innovative and effective annotation methods, harnessing the capabilities of large language models to enhance data quality and quantity. Additionally, we include unclear queries that resemble real-world user questions to test how well models can understand and tackle such challenges. Finally, we collect 2249 query-result pairs with 347 tables. We evaluate five state-of-the-art models using three different metrics and the results show that our benchmark presents introduces considerable challenge in the field of tabular data analysis, paving the way for more advanced research opportunities.
An Efficient Wide-Range Pseudo-3D Vehicle Detection Using A Single Camera
Sep 15, 2023Wide-range and fine-grained vehicle detection plays a critical role in enabling active safety features in intelligent driving systems. However, existing vehicle detection methods based on rectangular bounding boxes (BBox) often struggle with perceiving wide-range objects, especially small objects at long distances. And BBox expression cannot provide detailed geometric shape and pose information of vehicles. This paper proposes a novel wide-range Pseudo-3D Vehicle Detection method based on images from a single camera and incorporates efficient learning methods. This model takes a spliced image as input, which is obtained by combining two sub-window images from a high-resolution image. This image format maximizes the utilization of limited image resolution to retain essential information about wide-range vehicle objects. To detect pseudo-3D objects, our model adopts specifically designed detection heads. These heads simultaneously output extended BBox and Side Projection Line (SPL) representations, which capture vehicle shapes and poses, enabling high-precision detection. To further enhance the performance of detection, a joint constraint loss combining both the object box and SPL is designed during model training, improving the efficiency, stability, and prediction accuracy of the model. Experimental results on our self-built dataset demonstrate that our model achieves favorable performance in wide-range pseudo-3D vehicle detection across multiple evaluation metrics. Our demo video has been placed at https://www.youtube.com/watch?v=1gk1PmsQ5Q8.
PBFormer: Capturing Complex Scene Text Shape with Polynomial Band Transformer
Aug 29, 2023



We present PBFormer, an efficient yet powerful scene text detector that unifies the transformer with a novel text shape representation Polynomial Band (PB). The representation has four polynomial curves to fit a text's top, bottom, left, and right sides, which can capture a text with a complex shape by varying polynomial coefficients. PB has appealing features compared with conventional representations: 1) It can model different curvatures with a fixed number of parameters, while polygon-points-based methods need to utilize a different number of points. 2) It can distinguish adjacent or overlapping texts as they have apparent different curve coefficients, while segmentation-based or points-based methods suffer from adhesive spatial positions. PBFormer combines the PB with the transformer, which can directly generate smooth text contours sampled from predicted curves without interpolation. A parameter-free cross-scale pixel attention (CPA) module is employed to highlight the feature map of a suitable scale while suppressing the other feature maps. The simple operation can help detect small-scale texts and is compatible with the one-stage DETR framework, where no postprocessing exists for NMS. Furthermore, PBFormer is trained with a shape-contained loss, which not only enforces the piecewise alignment between the ground truth and the predicted curves but also makes curves' positions and shapes consistent with each other. Without bells and whistles about text pre-training, our method is superior to the previous state-of-the-art text detectors on the arbitrary-shaped text datasets.
Head-Tail Cooperative Learning Network for Unbiased Scene Graph Generation
Aug 23, 2023Scene Graph Generation (SGG) as a critical task in image understanding, facing the challenge of head-biased prediction caused by the long-tail distribution of predicates. However, current unbiased SGG methods can easily prioritize improving the prediction of tail predicates while ignoring the substantial sacrifice in the prediction of head predicates, leading to a shift from head bias to tail bias. To address this issue, we propose a model-agnostic Head-Tail Collaborative Learning (HTCL) network that includes head-prefer and tail-prefer feature representation branches that collaborate to achieve accurate recognition of both head and tail predicates. We also propose a self-supervised learning approach to enhance the prediction ability of the tail-prefer feature representation branch by constraining tail-prefer predicate features. Specifically, self-supervised learning converges head predicate features to their class centers while dispersing tail predicate features as much as possible through contrast learning and head center loss. We demonstrate the effectiveness of our HTCL by applying it to various SGG models on VG150, Open Images V6 and GQA200 datasets. The results show that our method achieves higher mean Recall with a minimal sacrifice in Recall and achieves a new state-of-the-art overall performance. Our code is available at https://github.com/wanglei0618/HTCL.
Inferring Tabular Analysis Metadata by Infusing Distribution and Knowledge Information
Sep 02, 2022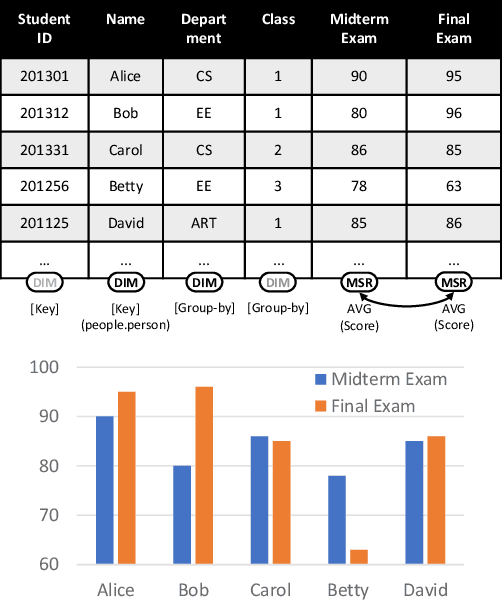
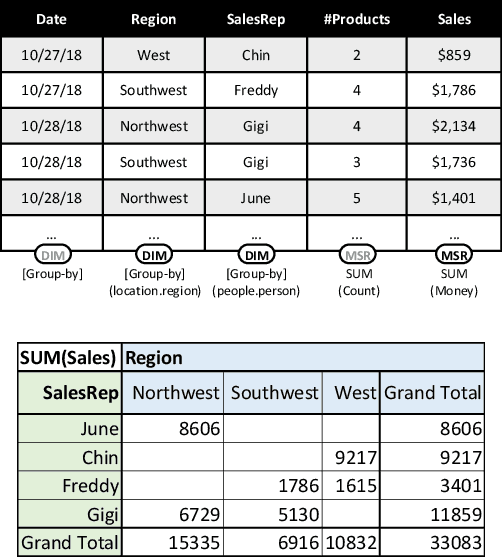
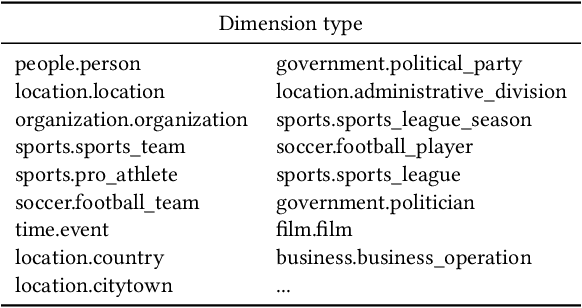
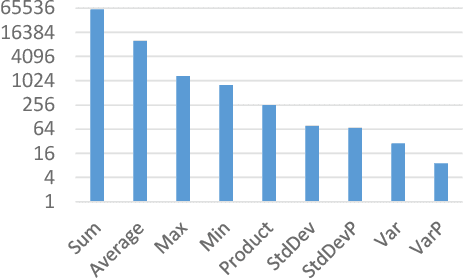
Many data analysis tasks heavily rely on a deep understanding of tables (multi-dimensional data). Across the tasks, there exist comonly used metadata attributes of table fields / columns. In this paper, we identify four such analysis metadata: Measure/dimension dichotomy, common field roles, semantic field type, and default aggregation function. While those metadata face challenges of insufficient supervision signals, utilizing existing knowledge and understanding distribution. To inference these metadata for a raw table, we propose our multi-tasking Metadata model which fuses field distribution and knowledge graph information into pre-trained tabular models. For model training and evaluation, we collect a large corpus (~582k tables from private spreadsheet and public tabular datasets) of analysis metadata by using diverse smart supervisions from downstream tasks. Our best model has accuracy = 98%, hit rate at top-1 > 67%, accuracy > 80%, and accuracy = 88% for the four analysis metadata inference tasks, respectively. It outperforms a series of baselines that are based on rules, traditional machine learning methods, and pre-trained tabular models. Analysis metadata models are deployed in a popular data analysis product, helping downstream intelligent features such as insights mining, chart / pivot table recommendation, and natural language QA...