 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCT-Mask: Discrete Cosine Transform Mask Representation for Instance Segmentation
Nov 19, 2020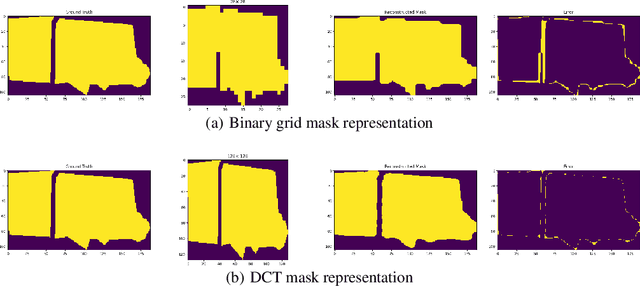
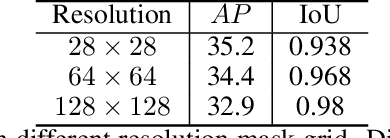
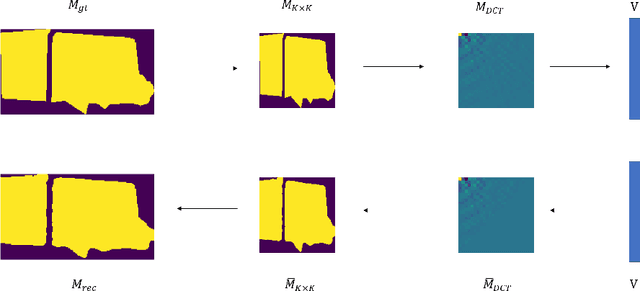
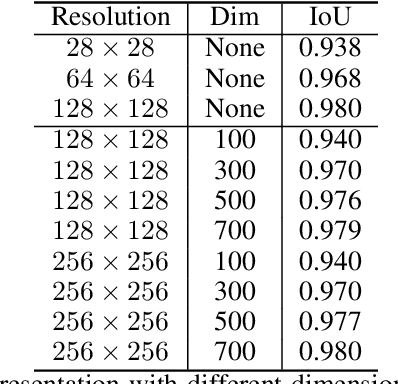
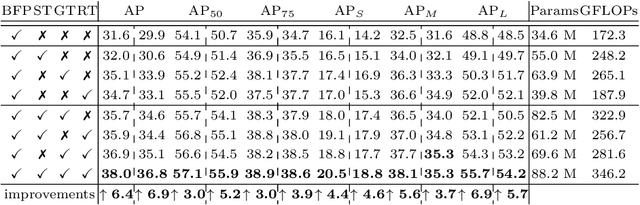
Binary grid mask representation is broadly used in instance segmentation. A representative instantiation is Mask R-CNN which predicts masks on a $28\times 28$ binary grid. Generally, a low-resolution grid is not sufficient to capture the details, while a high-resolution grid dramatically increases the training complexity. In this paper, we propose a new mask representation by applying the discrete cosine transform(DCT) to encode the high-resolution binary grid mask into a compact vector. Our method, termed DCT-Mask, could be easily integrated into most pixel-based instance segmentation methods. Without any bells and whistles, DCT-Mask yields significant gains on different frameworks, backbones, datasets, and training schedules. It does not require any pre-processing or pre-training, and almost no harm to the running speed. Especially, for higher-quality annotations and more complex backbones, our method has a greater improvement. Moreover, we analyze the performance of our method from the perspective of the quality of mask representation. The main reason why DCT-Mask works well is that it obtains a high-quality mask representation with low complexity. Code will be made available.
Causal Intervention for Weakly-Supervised Semantic Segmentation
Oct 07, 2020
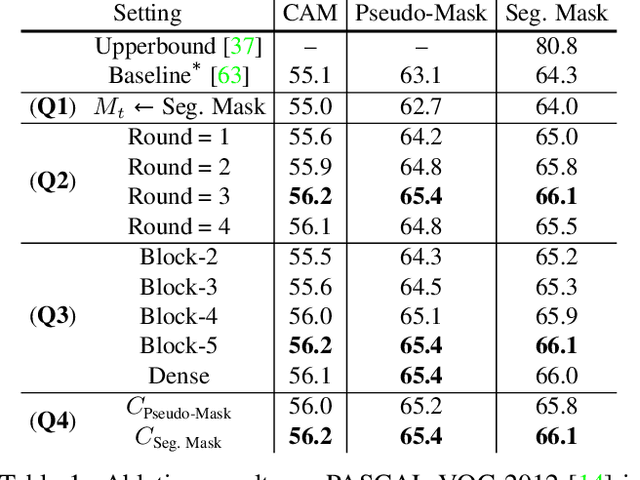

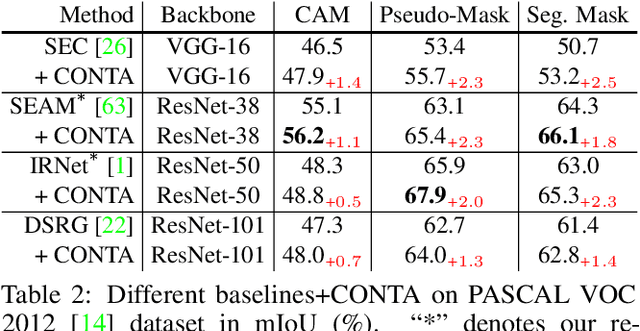
We present a causal inference framework to improve Weakly-Supervised Semantic Segmentation (WSSS). Specifically, we aim to generate better pixel-level pseudo-masks by using only image-level labels -- the most crucial step in WSSS. We attribute the cause of the ambiguous boundaries of pseudo-masks to the confounding context, e.g., the correct image-level classification of "horse" and "person" may be not only due to the recognition of each instance, but also their co-occurrence context, making the model inspection (e.g., CAM) hard to distinguish between the boundaries. Inspired by this, we propose a structural causal model to analyze the causalities among images, contexts, and class labels. Based on it, we develop a new method: Context Adjustment (CONTA), to remove the confounding bias in image-level classification and thus provide better pseudo-masks as ground-truth for the subsequent segmentation model. On PASCAL VOC 2012 and MS-COCO, we show that CONTA boosts various popular WSSS methods to new state-of-the-arts.
Feature Pyramid Transformer
Jul 18, 2020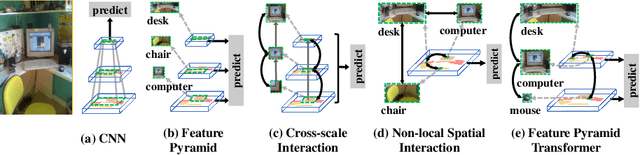
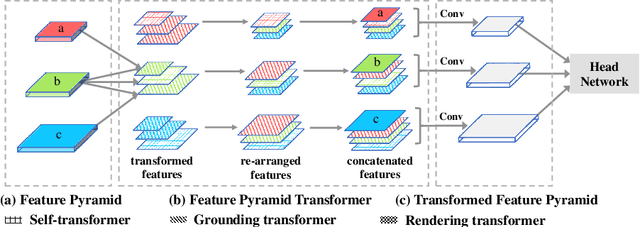

Feature interactions across space and scales underpin modern visual recognition systems because they introduce beneficial visual contexts. Conventionally, spatial contexts are passively hidden in the CNN's increasing receptive fields or actively encoded by non-local convolution. Yet, the non-local spatial interactions are not across scales, and thus they fail to capture the non-local contexts of objects (or parts) residing in different scales. To this end, we propose a fully active feature interaction across both space and scales, called Feature Pyramid Transformer (FPT). It transforms any feature pyramid into another feature pyramid of the same size but with richer contexts, by using three specially designed transformers in self-level, top-down, and bottom-up interaction fashion. FPT serves as a generic visual backbone with fair computational overhead. We conduct extensive experiments in both instance-level (i.e., object detection and instance segmentation) and pixel-level segmentation tasks, using various backbones and head networks, and observe consistent improvement over all the baselines and the state-of-the-art methods.
Towards Fine-grained Human Pose Transfer with Detail Replenishing Network
May 26, 2020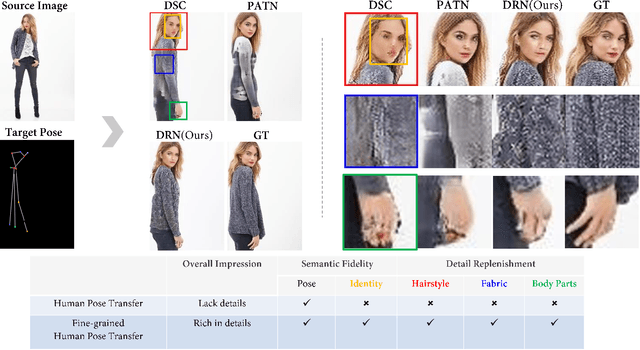
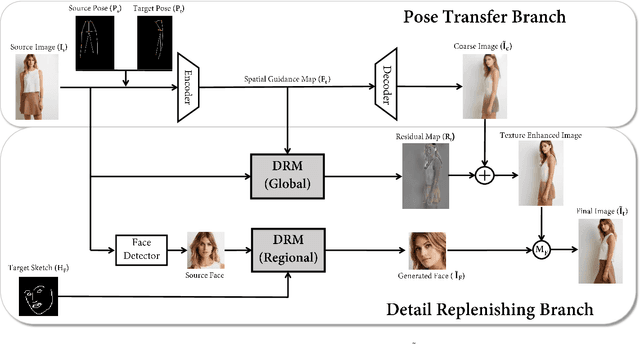
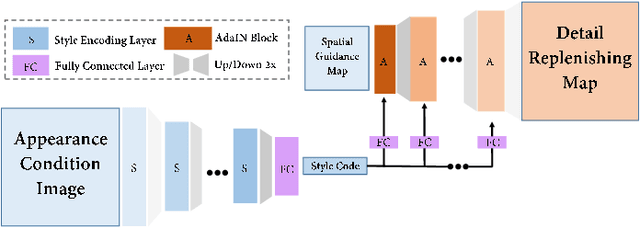

Human pose transfer (HPT) is an emerging research topic with huge potential in fashion design, media production, online advertising and virtual reality. For these applications, the visual realism of fine-grained appearance details is crucial for production quality and user engagement. However, existing HPT methods often suffer from three fundamental issues: detail deficiency, content ambiguity and style inconsistency, which severely degrade the visual quality and realism of generated images. Aiming towards real-world applications, we develop a more challenging yet practical HPT setting, termed as Fine-grained Human Pose Transfer (FHPT), with a higher focus on semantic fidelity and detail replenishment. Concretely, we analyze the potential design flaws of existing methods via an illustrative example, and establish the core FHPT methodology by combing the idea of content synthesis and feature transfer together in a mutually-guided fashion. Thereafter, we substantiate the proposed methodology with a Detail Replenishing Network (DRN) and a corresponding coarse-to-fine model training scheme. Moreover, we build up a complete suite of fine-grained evaluation protocols to address the challenges of FHPT in a comprehensive manner, including semantic analysis, structural detection and perceptual quality assessment. Extensive experiments on the DeepFashion benchmark dataset have verified the power of proposed benchmark against start-of-the-art works, with 12\%-14\% gain on top-10 retrieval recall, 5\% higher joint localization accuracy, and near 40\% gain on face identity preservation. Moreover, the evaluation results offer further insights to the subject matter, which could inspire many promising future works along this direction.
Gradient Centralization: A New Optimization Technique for Deep Neural Networks
Apr 08, 2020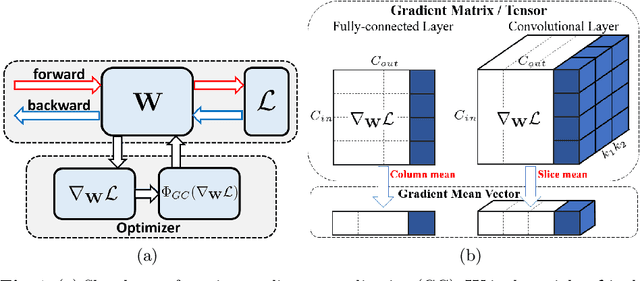
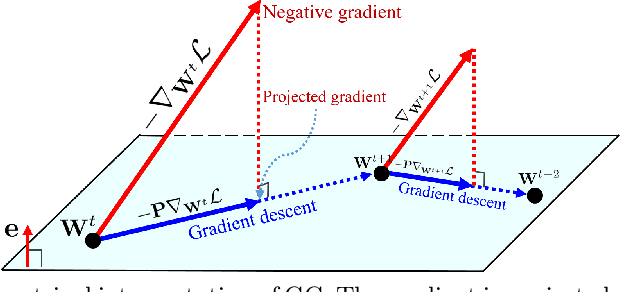

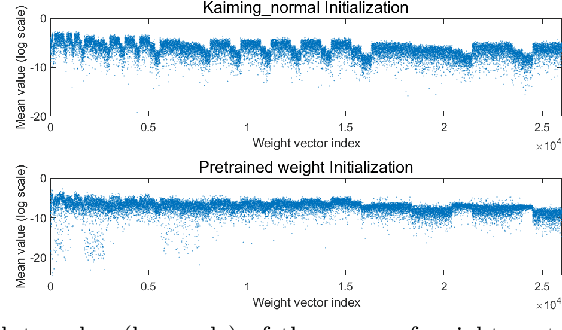
Optimization techniques are of great importance to effectively and efficiently train a deep neural network (DNN). It has been shown that using the first and second order statistics (e.g., mean and variance) to perform Z-score standardization on network activations or weight vectors, such as batch normalization (BN) and weight standardization (WS), can improve the training performance. Different from these existing methods that mostly operate on activations or weights, we present a new optimization technique, namely gradient centralization (GC), which operates directly on gradients by centralizing the gradient vectors to have zero mean. GC can be viewed as a projected gradient descent method with a constrained loss function. We show that GC can regularize both the weight space and output feature space so that it can boost the generalization performance of DNNs. Moreover, GC improves the Lipschitzness of the loss function and its gradient so that the training process becomes more efficient and stable. GC is very simple to implement and can be easily embedded into existing gradient based DNN optimizers with only one line of code. It can also be directly used to fine-tune the pre-trained DNNs. Our experiments on various applications, including general image classification, fine-grained image classification, detection and segmentation, demonstrate that GC can consistently improve the performance of DNN learning. The code of GC can be found at https://github.com/Yonghongwei/Gradient-Centralization.
A Survey on Deep Hashing Methods
Mar 04, 2020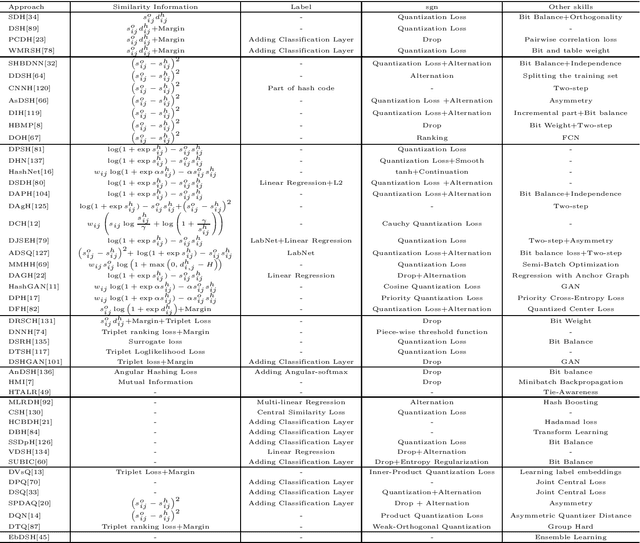
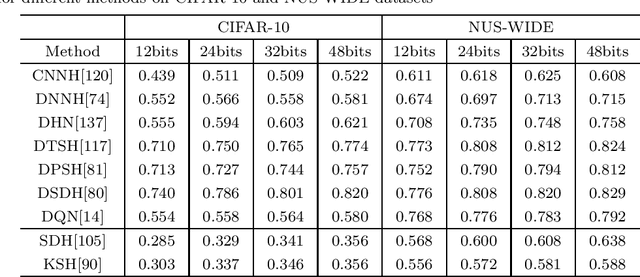
Nearest neighbor search is to find the data points in the database such that the distances from them to the query are the smallest, which is a fundamental problem in various domains, such as computer vision, recommendation systems and machine learning. Hashing is one of the most widely used method for its computational and storage efficiency. With the development of deep learning, deep hashing methods show more advantages than traditional methods. In this paper, we present a comprehensive survey of the deep hashing algorithms. Based on the loss function, we categorize deep supervised hashing methods according to the manners of preserving the similarities into: pairwise similarity preserving, multiwise similarity preserving, implicit similarity preserving, as well as quantization. In addition, we also introduce some other topics such as deep unsupervised hashing and multi-modal deep hashing methods. Meanwhile, we also present some commonly used public datasets and the scheme to measure the performance of deep hashing algorithms. Finally, we discussed some potential research directions in the conclusion.
Quantization Networks
Nov 28, 2019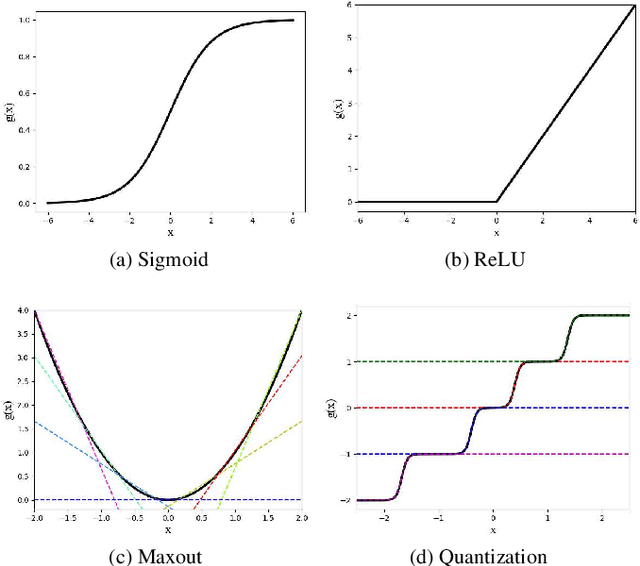
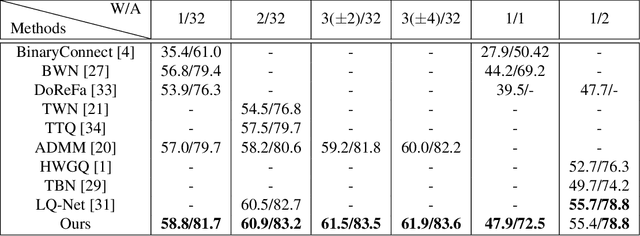

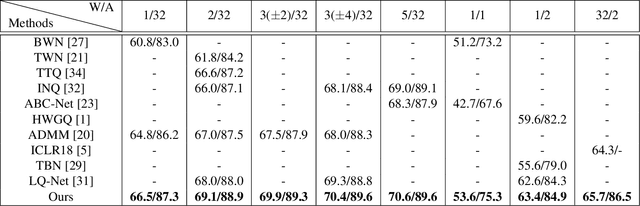
Although deep neural networks are highly effective, their high computational and memory costs severely challenge their applications on portable devices. As a consequence, low-bit quantization, which converts a full-precision neural network into a low-bitwidth integer version, has been an active and promising research topic. Existing methods formulate the low-bit quantization of networks as an approximation or optimization problem. Approximation-based methods confront the gradient mismatch problem, while optimization-based methods are only suitable for quantizing weights and could introduce high computational cost in the training stage. In this paper, we propose a novel perspective of interpreting and implementing neural network quantization by formulating low-bit quantization as a differentiable non-linear function (termed quantization function). The proposed quantization function can be learned in a lossless and end-to-end manner and works for any weights and activations of neural networks in a simple and uniform way. Extensive experiments on image classification and object detection tasks show that our quantization networks outperform the state-of-the-art methods. We believe that the proposed method will shed new insights on the interpretation of neural network quantization. Our code is available at https://github.com/aliyun/alibabacloud-quantization-networks.
SSAH: Semi-supervised Adversarial Deep Hashing with Self-paced Hard Sample Generation
Nov 20, 2019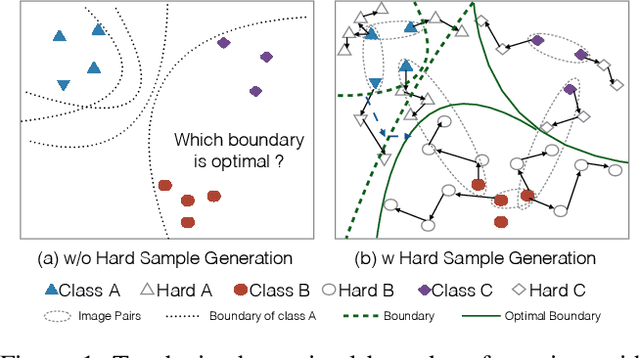
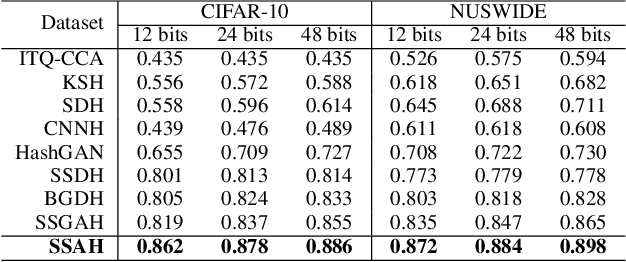
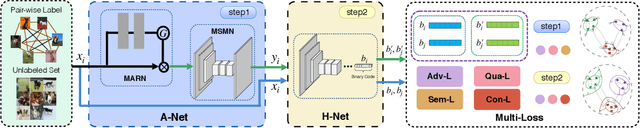
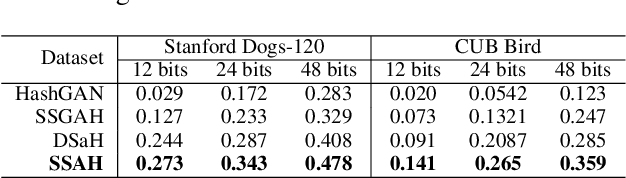
Deep hashing methods have been proved to be effective and efficient for large-scale Web media search. The success of these data-driven methods largely depends on collecting sufficient labeled data, which is usually a crucial limitation in practical cases. The current solutions to this issue utilize Generative Adversarial Network (GAN) to augment data in semi-supervised learning. However, existing GAN-based methods treat image generations and hashing learning as two isolated processes, leading to generation ineffectiveness. Besides, most works fail to exploit the semantic information in unlabeled data. In this paper, we propose a novel Semi-supervised Self-pace Adversarial Hashing method, named SSAH to solve the above problems in a unified framework. The SSAH method consists of an adversarial network (A-Net) and a hashing network (H-Net). To improve the quality of generative images, first, the A-Net learns hard samples with multi-scale occlusions and multi-angle rotated deformations which compete against the learning of accurate hashing codes. Second, we design a novel self-paced hard generation policy to gradually increase the hashing difficulty of generated samples. To make use of the semantic information in unlabeled ones, we propose a semi-supervised consistent loss. The experimental results show that our method can significantly improve state-of-the-art models on both the widely-used hashing datasets and fine-grained datasets.
Extracting Visual Knowledge from the Internet: Making Sense of Image Data
Jun 07, 2019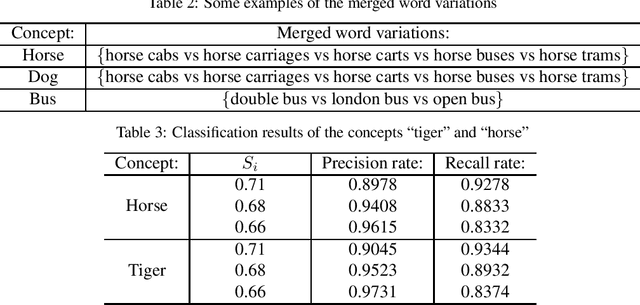
Recent successes in visual recognition can be primarily attributed to feature representation, learning algorithms, and the ever-increasing size of labeled training data. Extensive research has been devoted to the first two, but much less attention has been paid to the third. Due to the high cost of manual labeling, the size of recent efforts such as ImageNet is still relatively small in respect to daily applications. In this work, we mainly focus on how to automatically generate identifying image data for a given visual concept on a vast scale. With the generated image data, we can train a robust recognition model for the given concept. We evaluate the proposed webly supervised approach on the benchmark Pascal VOC 2007 dataset and the results demonstrates the superiority of our proposed approach in image data collection.
Automated Segmentation of Pulmonary Lobes using Coordination-Guided Deep Neural Networks
Apr 19, 2019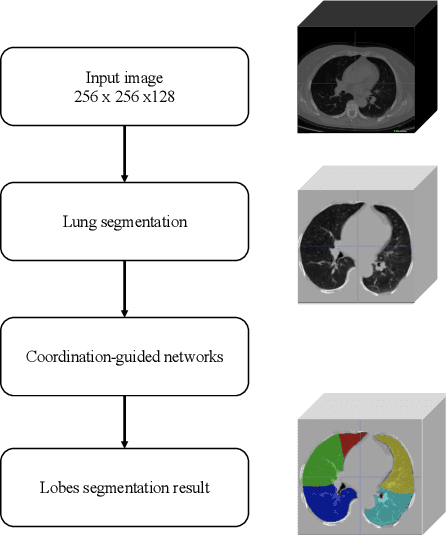
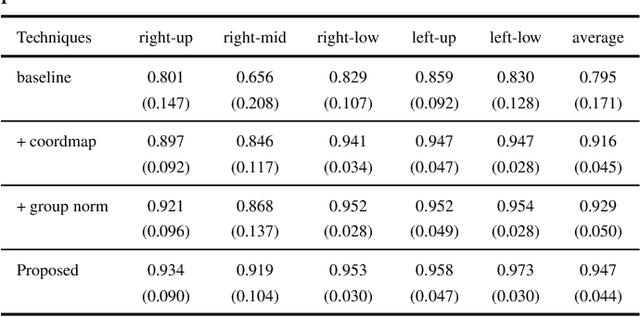
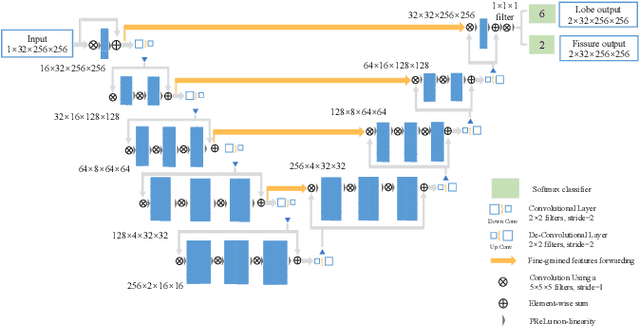
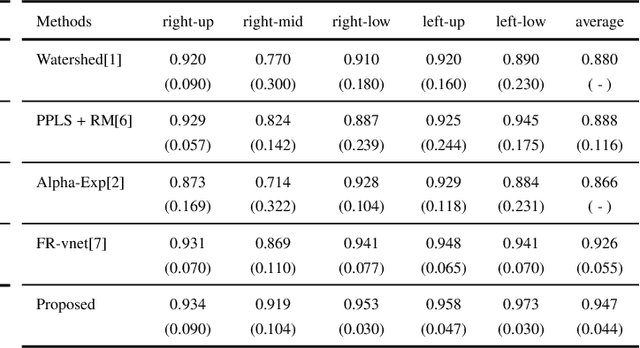
The identification of pulmonary lobes is of great importance in disease diagnosis and treatment. A few lung diseases have regional disorders at lobar level. Thus, an accurate segmentation of pulmonary lobes is necessary. In this work, we propose an automated segmentation of pulmonary lobes using coordination-guided deep neural networks from chest CT images. We first employ an automated lung segmentation to extract the lung area from CT image, then exploit volumetric convolutional neural network (V-net) for segmenting the pulmonary lobes. To reduce the misclassification of different lobes, we therefore adopt coordination-guided convolutional layers (CoordConvs) that generate additional feature maps of the positional information of pulmonary lobes. The proposed model is trained and evaluated on a few publicly available datasets and has achieved the state-of-the-art accuracy with a mean Dice coefficient index of 0.947 $\pm$ 0.044.