 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniAPO: Unified Multimodal Automated Prompt Optimization
Aug 25, 2025



Prompting is fundamental to unlocking the full potential of large language models. To automate and enhance this process, automatic prompt optimization (APO) has been developed, demonstrating effectiveness primarily in text-only input scenarios. However, extending existing APO methods to multimodal tasks, such as video-language generation introduces two core challenges: (i) visual token inflation, where long visual token sequences restrict context capacity and result in insufficient feedback signals; (ii) a lack of process-level supervision, as existing methods focus on outcome-level supervision and overlook intermediate supervision, limiting prompt optimization. We present UniAPO: Unified Multimodal Automated Prompt Optimization, the first framework tailored for multimodal APO. UniAPO adopts an EM-inspired optimization process that decouples feedback modeling and prompt refinement, making the optimization more stable and goal-driven. To further address the aforementioned challenges, we introduce a short-long term memory mechanism: historical feedback mitigates context limitations, while historical prompts provide directional guidance for effective prompt optimization. UniAPO achieves consistent gains across text, image, and video benchmarks, establishing a unified framework for efficient and transferable prompt optimization.
Cream of the Crop: Harvesting Rich, Scalable and Transferable Multi-Modal Data for Instruction Fine-Tuning
Mar 17, 2025The hypothesis that pretrained large language models (LLMs) necessitate only minimal supervision during the fine-tuning (SFT) stage (Zhou et al., 2024) has been substantiated by recent advancements in data curation and selection research. However, their stability and generalizability are compromised due to the vulnerability to experimental setups and validation protocols, falling short of surpassing random sampling (Diddee & Ippolito, 2024; Xia et al., 2024b). Built upon LLMs, multi-modal LLMs (MLLMs), combined with the sheer token volume and heightened heterogeneity of data sources, amplify both the significance and complexity of data selection. To harvest multi-modal instructional data in a robust and efficient manner, we re-define the granularity of the quality metric by decomposing it into 14 vision-language-related capabilities, and introduce multi-modal rich scorers to evaluate the capabilities of each data candidate. To promote diversity, in light of the inherent objective of the alignment stage, we take interaction style as diversity indicator and use a multi-modal rich styler to identify data instruction patterns. In doing so, our multi-modal rich scorers and styler (mmSSR) guarantee that high-scoring information is conveyed to users in diversified forms. Free from embedding-based clustering or greedy sampling, mmSSR efficiently scales to millions of data with varying budget constraints, supports customization for general or specific capability acquisition, and facilitates training-free generalization to new domains for curation. Across 10+ experimental settings, validated by 14 multi-modal benchmarks, we demonstrate consistent improvements over random sampling, baseline strategies and state-of-the-art selection methods, achieving 99.1% of full performance with only 30% of the 2.6M data.
EVLM: An Efficient Vision-Language Model for Visual Understanding
Jul 19, 2024



In the field of multi-modal language models, the majority of methods are built on an architecture similar to LLaVA. These models use a single-layer ViT feature as a visual prompt, directly feeding it into the language models alongside textual tokens. However, when dealing with long sequences of visual signals or inputs such as videos, the self-attention mechanism of language models can lead to significant computational overhead. Additionally, using single-layer ViT features makes it challenging for large language models to perceive visual signals fully. This paper proposes an efficient multi-modal language model to minimize computational costs while enabling the model to perceive visual signals as comprehensively as possible. Our method primarily includes: (1) employing cross-attention to image-text interaction similar to Flamingo. (2) utilize hierarchical ViT features. (3) introduce the Mixture of Experts (MoE) mechanism to enhance model effectiveness. Our model achieves competitive scores on public multi-modal benchmarks and performs well in tasks such as image captioning and video captioning.
On Mitigating Hard Clusters for Face Clustering
Jul 25, 2022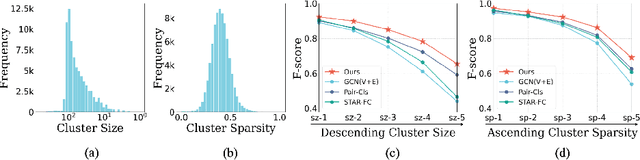
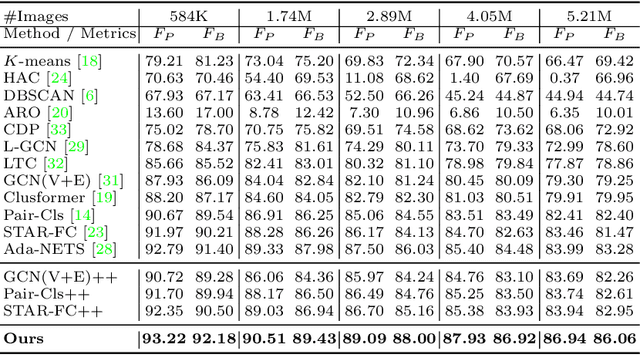
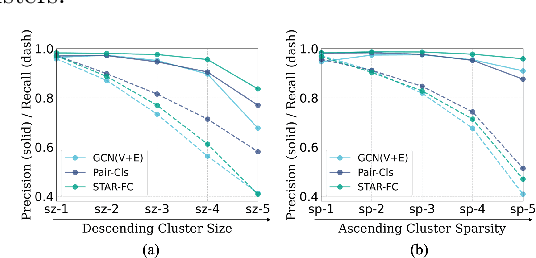
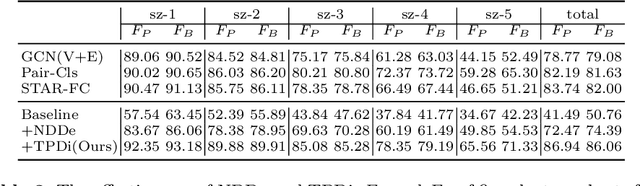
Face clustering is a promising way to scale up face recognition systems using large-scale unlabeled face images. It remains challenging to identify small or sparse face image clusters that we call hard clusters, which is caused by the heterogeneity, \ie, high variations in size and sparsity, of the clusters. Consequently, the conventional way of using a uniform threshold (to identify clusters) often leads to a terrible misclassification for the samples that should belong to hard clusters. We tackle this problem by leveraging the neighborhood information of samples and inferring the cluster memberships (of samples) in a probabilistic way. We introduce two novel modules, Neighborhood-Diffusion-based Density (NDDe) and Transition-Probability-based Distance (TPDi), based on which we can simply apply the standard Density Peak Clustering algorithm with a uniform threshold. Our experiments on multiple benchmarks show that each module contributes to the final performance of our method, and by incorporating them into other advanced face clustering methods, these two modules can boost the performance of these methods to a new state-of-the-art. Code is available at: https://github.com/echoanran/On-Mitigating-Hard-Clusters.
Simulated annealing for optimization of graphs and sequences
Oct 01, 2021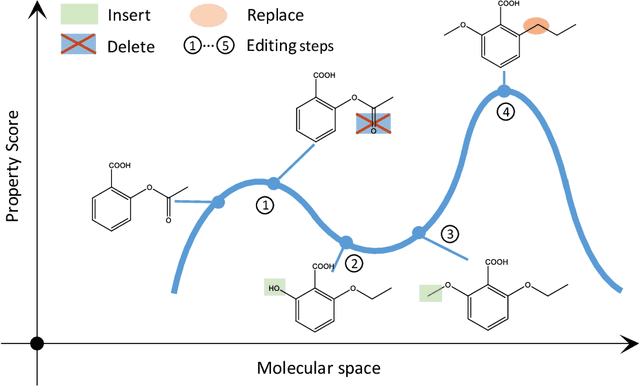
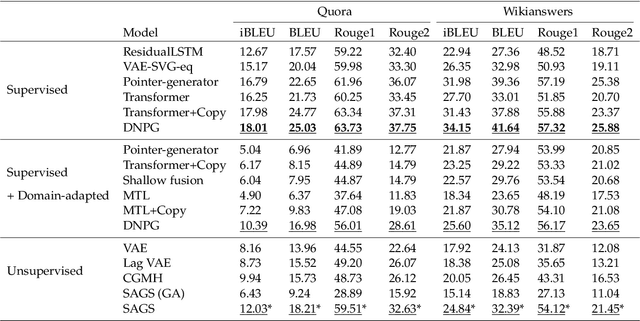
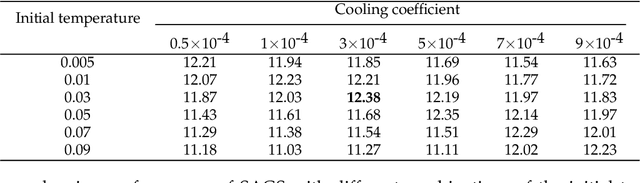
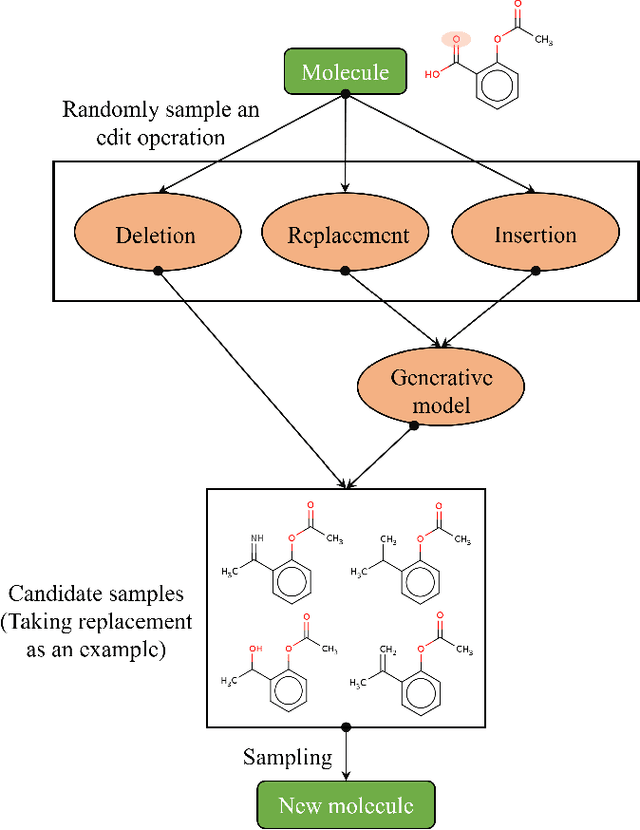
Optimization of discrete structures aims at generating a new structure with the better property given an existing one, which is a fundamental problem in machine learning. Different from the continuous optimization, the realistic applications of discrete optimization (e.g., text generation) are very challenging due to the complex and long-range constraints, including both syntax and semantics, in discrete structures. In this work, we present SAGS, a novel Simulated Annealing framework for Graph and Sequence optimization. The key idea is to integrate powerful neural networks into metaheuristics (e.g., simulated annealing, SA) to restrict the search space in discrete optimization. We start by defining a sophisticated objective function, involving the property of interest and pre-defined constraints (e.g., grammar validity). SAGS searches from the discrete space towards this objective by performing a sequence of local edits, where deep generative neural networks propose the editing content and thus can control the quality of editing. We evaluate SAGS on paraphrase generation and molecule generation for sequence optimization and graph optimization, respectively. Extensive results show that our approach achieves state-of-the-art performance compared with existing paraphrase generation methods in terms of both automatic and human evaluations. Further, SAGS also significantly outperforms all the previous methods in molecule generation.
* This article is an accepted manuscript of Neurocomputing. arXiv admin note: substantial text overlap with arXiv:1909.03588
Deep Unsupervised Hashing by Distilled Smooth Guidance
May 13, 2021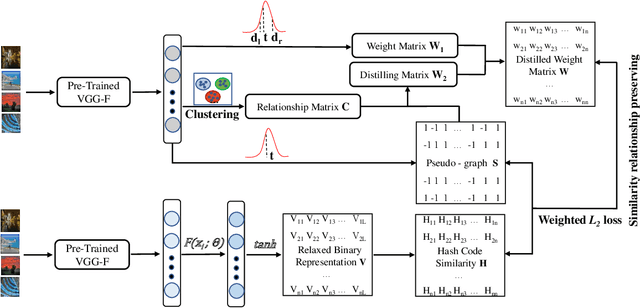
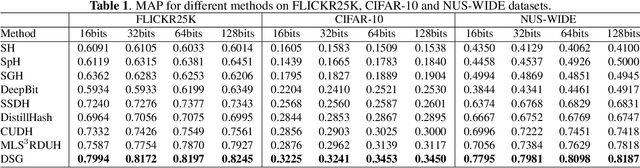

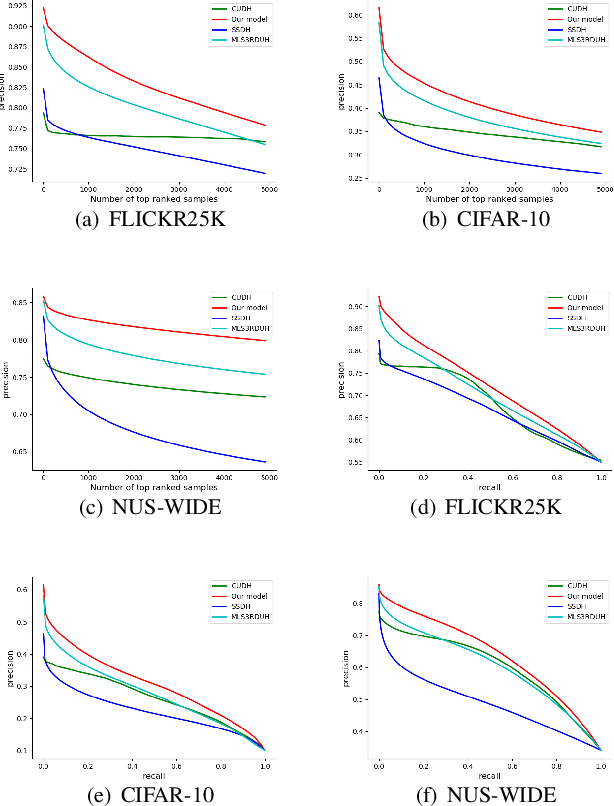
Hashing has been widely used in approximate nearest neighbor search for its storage and computational efficiency. Deep supervised hashing methods are not widely used because of the lack of labeled data, especially when the domain is transferred. Meanwhile, unsupervised deep hashing models can hardly achieve satisfactory performance due to the lack of reliable similarity signals. To tackle this problem, we propose a novel deep unsupervised hashing method, namely Distilled Smooth Guidance (DSG), which can learn a distilled dataset consisting of similarity signals as well as smooth confidence signals. To be specific, we obtain the similarity confidence weights based on the initial noisy similarity signals learned from local structures and construct a priority loss function for smooth similarity-preserving learning. Besides, global information based on clustering is utilized to distill the image pairs by removing contradictory similarity signals. Extensive experiments on three widely used benchmark datasets show that the proposed DSG consistently outperforms the state-of-the-art search methods.
* 7 pages, 3 figures
Graph Contrastive Clustering
Apr 03, 2021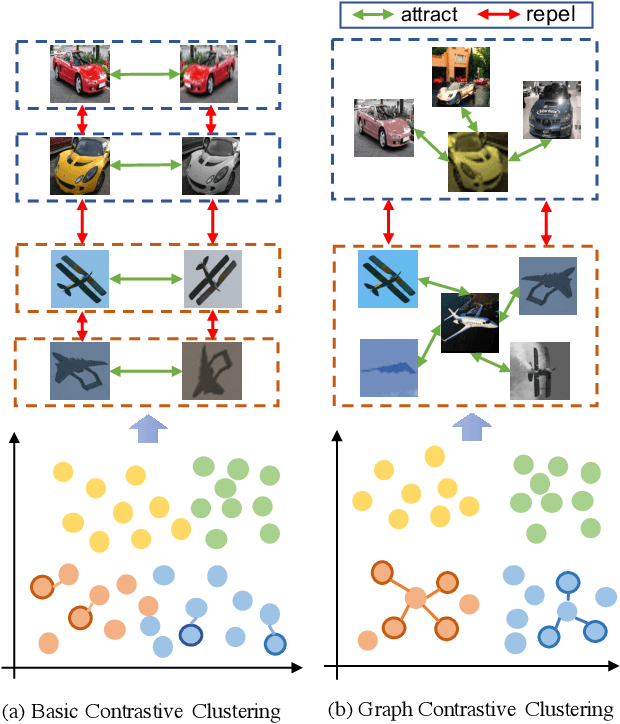
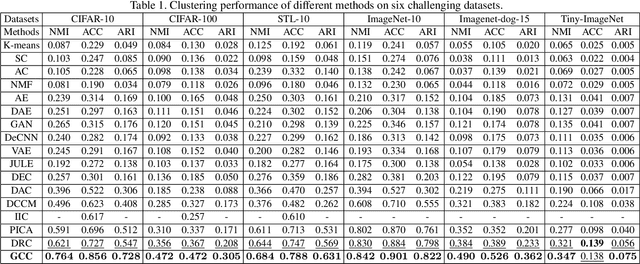
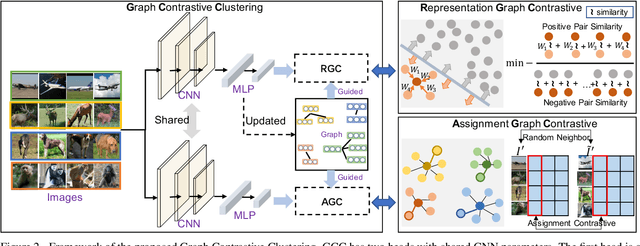
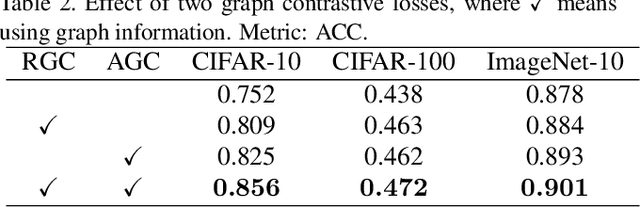
Recently, some contrastive learning methods have been proposed to simultaneously learn representations and clustering assignments, achieving significant improvements. However, these methods do not take the category information and clustering objective into consideration, thus the learned representations are not optimal for clustering and the performance might be limited. Towards this issue, we first propose a novel graph contrastive learning framework, which is then applied to the clustering task and we come up with the Graph Constrastive Clustering~(GCC) method. Different from basic contrastive clustering that only assumes an image and its augmentation should share similar representation and clustering assignments, we lift the instance-level consistency to the cluster-level consistency with the assumption that samples in one cluster and their augmentations should all be similar. Specifically, on the one hand, the graph Laplacian based contrastive loss is proposed to learn more discriminative and clustering-friendly features. On the other hand, a novel graph-based contrastive learning strategy is proposed to learn more compact clustering assignments. Both of them incorporate the latent category information to reduce the intra-cluster variance while increasing the inter-cluster variance. Experiments on six commonly used datasets demonstrate the superiority of our proposed approach over the state-of-the-art methods.
CIMON: Towards High-quality Hash Codes
Nov 05, 2020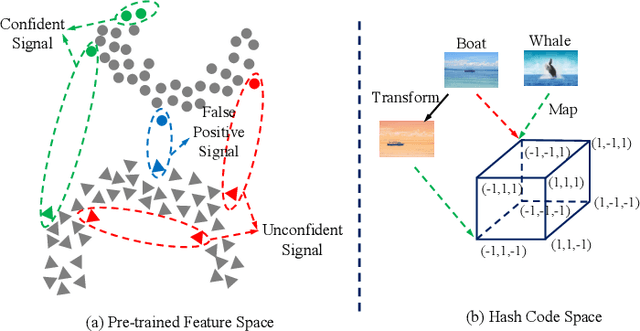
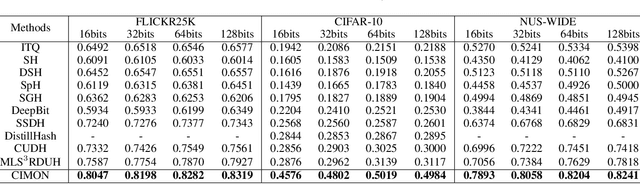
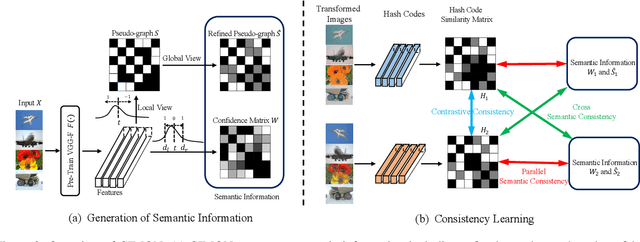
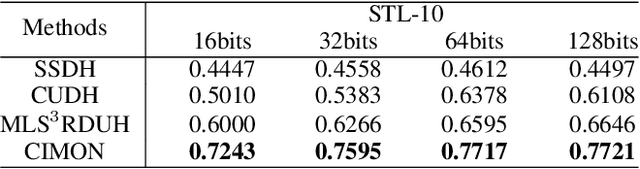
Recently, hashing is widely-used in approximate nearest neighbor search for its storage and computational efficiency. Due to the lack of labeled data in practice, many studies focus on unsupervised hashing. Most of the unsupervised hashing methods learn to map images into semantic similarity-preserving hash codes by constructing local semantic similarity structure from the pre-trained model as guiding information, i.e., treating each point pair similar if their distance is small in feature space. However, due to the inefficient representation ability of the pre-trained model, many false positives and negatives in local semantic similarity will be introduced and lead to error propagation during hash code learning. Moreover, most of hashing methods ignore the basic characteristics of hash codes such as collisions, which will cause instability of hash codes to disturbance. In this paper, we propose a new method named Comprehensive sImilarity Mining and cOnsistency learNing (CIMON). First, we use global constraint learning and similarity statistical distribution to obtain reliable and smooth guidance. Second, image augmentation and consistency learning will be introduced to explore both semantic and contrastive consistency to derive robust hash codes with fewer collisions. Extensive experiments on several benchmark datasets show that the proposed method consistently outperforms a wide range of state-of-the-art methods in both retrieval performance and robustness.
Deep Robust Clustering by Contrastive Learning
Aug 27, 2020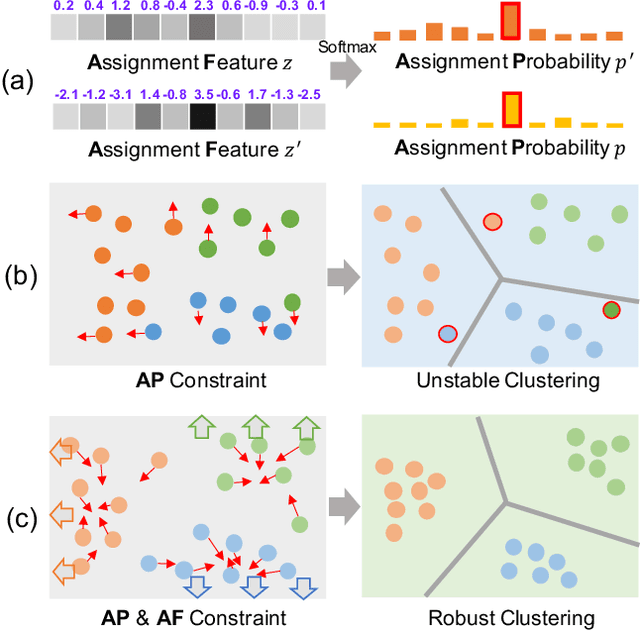
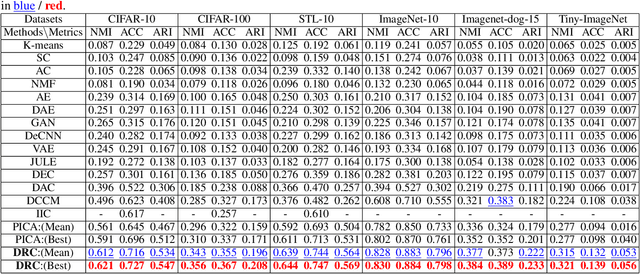
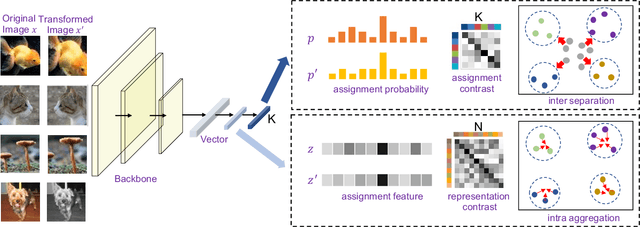

Recently, many unsupervised deep learning methods have been proposed to learn clustering with unlabelled data. By introducing data augmentation, most of the latest methods look into deep clustering from the perspective that the original image and its transformation should share similar semantic clustering assignment. However, the representation features could be quite different even they are assigned to the same cluster since softmax function is only sensitive to the maximum value. This may result in high intra-class diversities in the representation feature space, which will lead to unstable local optimal and thus harm the clustering performance. To address this drawback, we proposed Deep Robust Clustering (DRC). Different from existing methods, DRC looks into deep clustering from two perspectives of both semantic clustering assignment and representation feature, which can increase inter-class diversities and decrease intra-class diversities simultaneously. Furthermore, we summarized a general framework that can turn any maximizing mutual information into minimizing contrastive loss by investigating the internal relationship between mutual information and contrastive learning. And we successfully applied it in DRC to learn invariant features and robust clusters. Extensive experiments on six widely-adopted deep clustering benchmarks demonstrate the superiority of DRC in both stability and accuracy. e.g., attaining 71.6% mean accuracy on CIFAR-10, which is 7.1% higher than state-of-the-art results.
A Survey on Deep Hashing Methods
Mar 04, 2020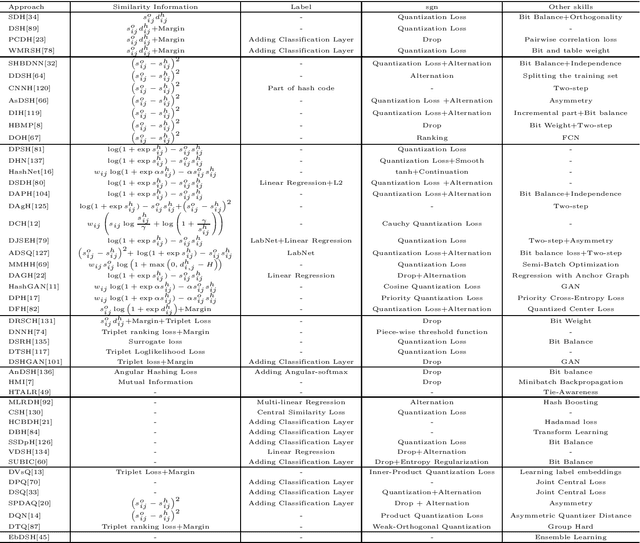
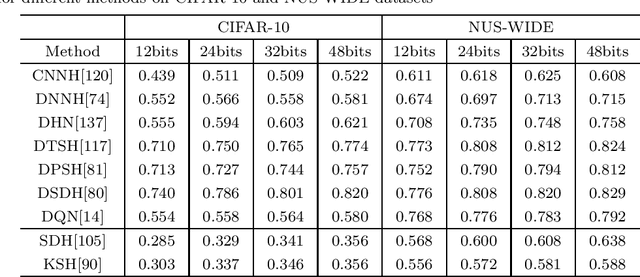
Nearest neighbor search is to find the data points in the database such that the distances from them to the query are the smallest, which is a fundamental problem in various domains, such as computer vision, recommendation systems and machine learning. Hashing is one of the most widely used method for its computational and storage efficiency. With the development of deep learning, deep hashing methods show more advantages than traditional methods. In this paper, we present a comprehensive survey of the deep hashing algorithms. Based on the loss function, we categorize deep supervised hashing methods according to the manners of preserving the similarities into: pairwise similarity preserving, multiwise similarity preserving, implicit similarity preserving, as well as quantization. In addition, we also introduce some other topics such as deep unsupervised hashing and multi-modal deep hashing methods. Meanwhile, we also present some commonly used public datasets and the scheme to measure the performance of deep hashing algorithms. Finally, we discussed some potential research directions in the conclusion.