 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative Multi-Agent Transfer Learning with Level-Adaptive Credit Assignment
Jun 03, 2021
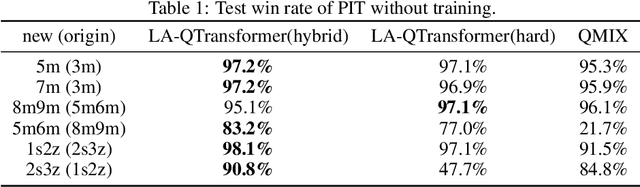
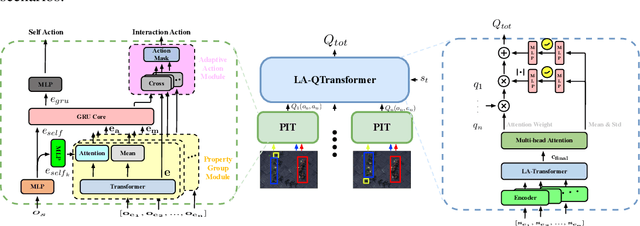
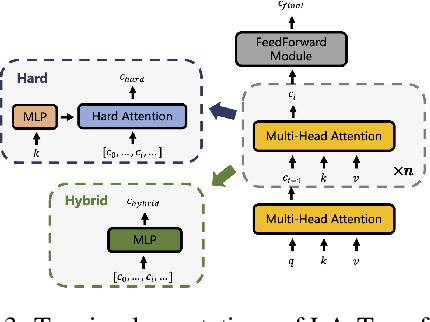
Extending transfer learning to cooperative multi-agent reinforcement learning (MARL) has recently received much attention. In contrast to the single-agent setting, the coordination indispensable in cooperative MARL constrains each agent's policy. However, existing transfer methods focus exclusively on agent policy and ignores coordination knowledge. We propose a new architecture that realizes robust coordination knowledge transfer through appropriate decomposition of the overall coordination into several coordination patterns. We use a novel mixing network named level-adaptive QTransformer (LA-QTransformer) to realize agent coordination that considers credit assignment, with appropriate coordination patterns for different agents realized by a novel level-adaptive Transformer (LA-Transformer) dedicated to the transfer of coordination knowledge. In addition, we use a novel agent network named Population Invariant agent with Transformer (PIT) to realize the coordination transfer in more varieties of scenarios. Extensive experiments in StarCraft II micro-management show that LA-QTransformer together with PIT achieves superior performance compared with state-of-the-art baselines.
Learning Symbolic Rules for Interpretable Deep Reinforcement Learning
Mar 16, 2021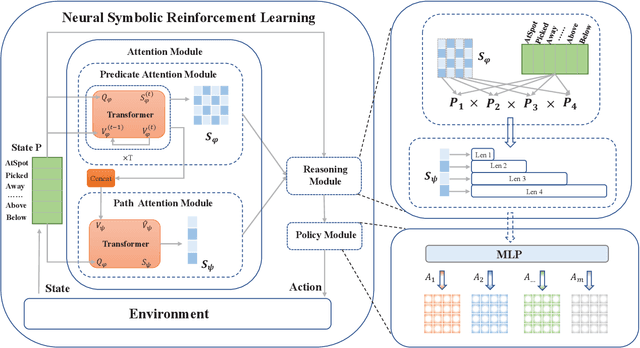

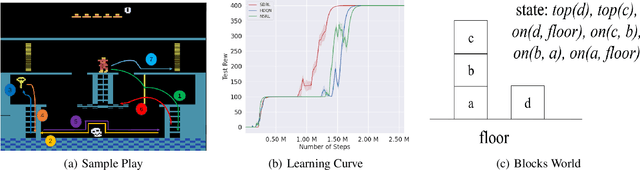
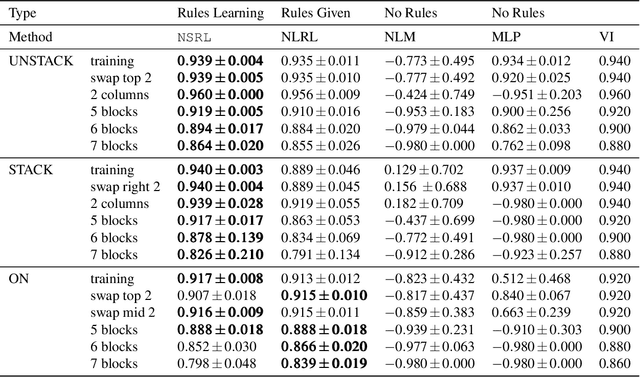
Recent progress in deep reinforcement learning (DRL) can be largely attributed to the use of neural networks. However, this black-box approach fails to explain the learned policy in a human understandable way. To address this challenge and improve the transparency, we propose a Neural Symbolic Reinforcement Learning framework by introducing symbolic logic into DRL. This framework features a fertilization of reasoning and learning modules, enabling end-to-end learning with prior symbolic knowledge. Moreover, interpretability is achieved by extracting the logical rules learned by the reasoning module in a symbolic rule space. The experimental results show that our framework has better interpretability, along with competing performance in comparison to state-of-the-art approaches.
Addressing Action Oscillations through Learning Policy Inertia
Mar 03, 2021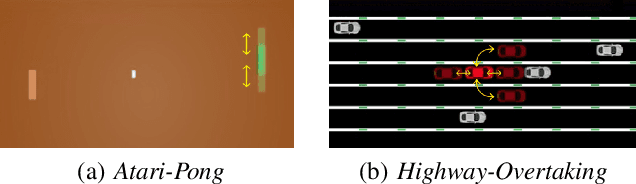
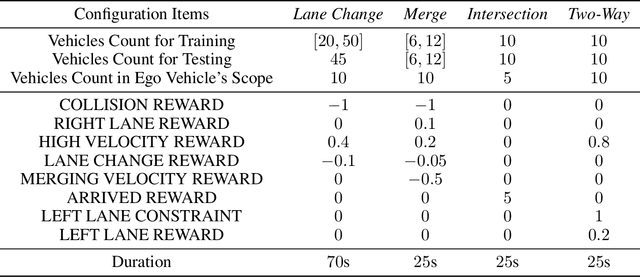
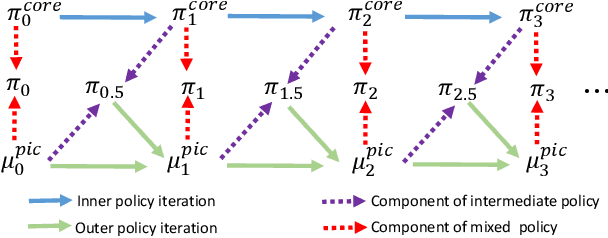

Deep reinforcement learning (DRL) algorithms have been demonstrated to be effective in a wide range of challenging decision making and control tasks. However, these methods typically suffer from severe action oscillations in particular in discrete action setting, which means that agents select different actions within consecutive steps even though states only slightly differ. This issue is often neglected since the policy is usually evaluated by its cumulative rewards only. Action oscillation strongly affects the user experience and can even cause serious potential security menace especially in real-world domains with the main concern of safety, such as autonomous driving. To this end, we introduce Policy Inertia Controller (PIC) which serves as a generic plug-in framework to off-the-shelf DRL algorithms, to enables adaptive trade-off between the optimality and smoothness of the learned policy in a formal way. We propose Nested Policy Iteration as a general training algorithm for PIC-augmented policy which ensures monotonically non-decreasing updates under some mild conditions. Further, we derive a practical DRL algorithm, namely Nested Soft Actor-Critic. Experiments on a collection of autonomous driving tasks and several Atari games suggest that our approach demonstrates substantial oscillation reduction in comparison to a range of commonly adopted baselines with almost no performance degradation.
Foresee then Evaluate: Decomposing Value Estimation with Latent Future Prediction
Mar 03, 2021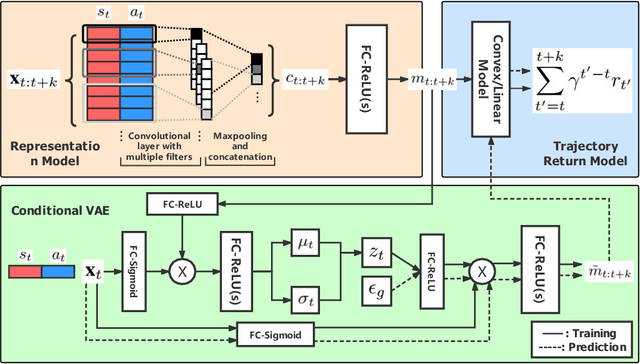

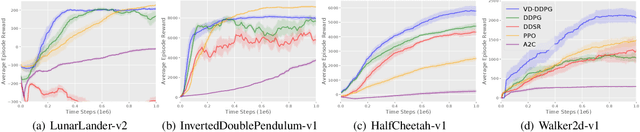
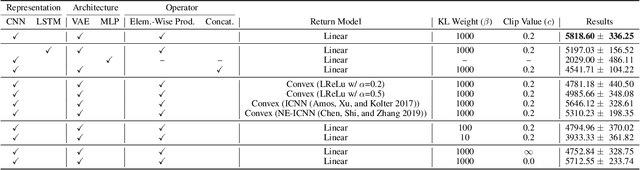
Value function is the central notion of Reinforcement Learning (RL). Value estimation, especially with function approximation, can be challenging since it involves the stochasticity of environmental dynamics and reward signals that can be sparse and delayed in some cases. A typical model-free RL algorithm usually estimates the values of a policy by Temporal Difference (TD) or Monte Carlo (MC) algorithms directly from rewards, without explicitly taking dynamics into consideration. In this paper, we propose Value Decomposition with Future Prediction (VDFP), providing an explicit two-step understanding of the value estimation process: 1) first foresee the latent future, 2) and then evaluate it. We analytically decompose the value function into a latent future dynamics part and a policy-independent trajectory return part, inducing a way to model latent dynamics and returns separately in value estimation. Further, we derive a practical deep RL algorithm, consisting of a convolutional model to learn compact trajectory representation from past experiences, a conditional variational auto-encoder to predict the latent future dynamics and a convex return model that evaluates trajectory representation. In experiments, we empirically demonstrate the effectiveness of our approach for both off-policy and on-policy RL in several OpenAI Gym continuous control tasks as well as a few challenging variants with delayed reward.
SMARTS: Scalable Multi-Agent Reinforcement Learning Training School for Autonomous Driving
Nov 01, 2020
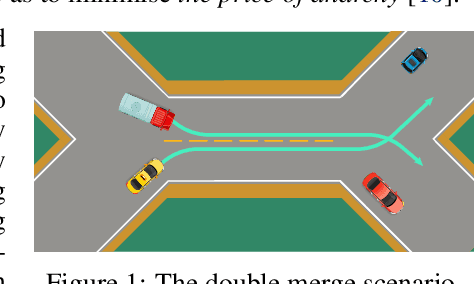
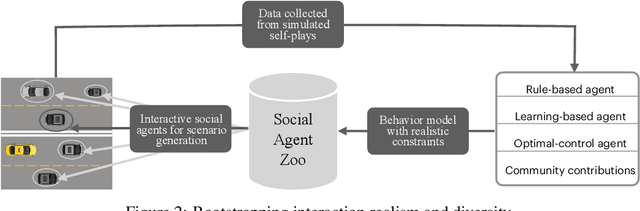
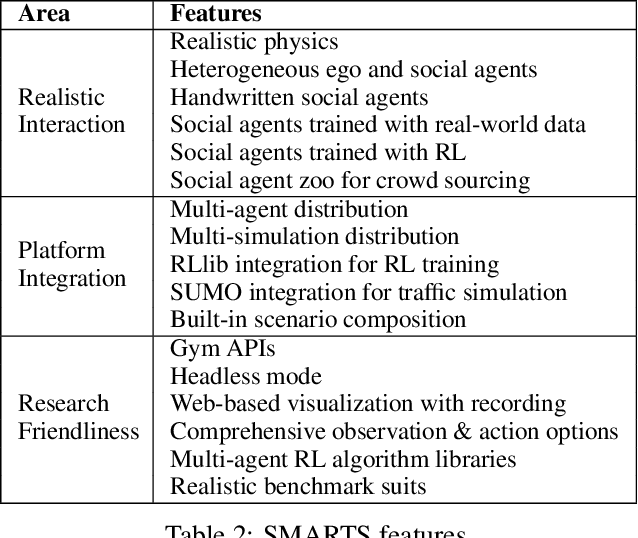
Multi-agent interaction is a fundamental aspect of autonomous driving in the real world. Despite more than a decade of research and development, the problem of how to competently interact with diverse road users in diverse scenarios remains largely unsolved. Learning methods have much to offer towards solving this problem. But they require a realistic multi-agent simulator that generates diverse and competent driving interactions. To meet this need, we develop a dedicated simulation platform called SMARTS (Scalable Multi-Agent RL Training School). SMARTS supports the training, accumulation, and use of diverse behavior models of road users. These are in turn used to create increasingly more realistic and diverse interactions that enable deeper and broader research on multi-agent interaction. In this paper, we describe the design goals of SMARTS, explain its basic architecture and its key features, and illustrate its use through concrete multi-agent experiments on interactive scenarios. We open-source the SMARTS platform and the associated benchmark tasks and evaluation metrics to encourage and empower research on multi-agent learning for autonomous driving. Our code is available at https://github.com/huawei-noah/SMARTS.
What About Taking Policy as Input of Value Function: Policy-extended Value Function Approximator
Oct 19, 2020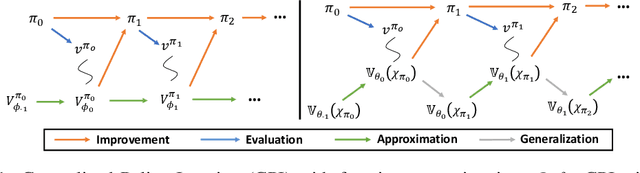

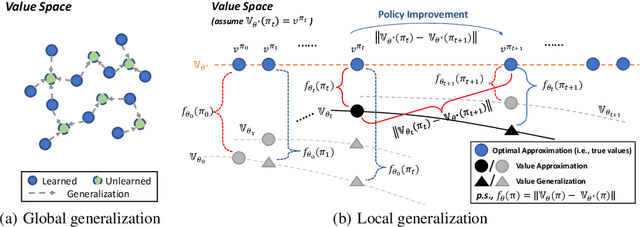
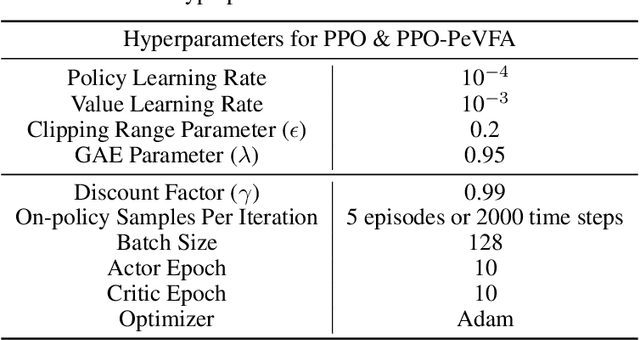
The value function lies in the heart of Reinforcement Learning (RL), which defines the long-term evaluation of a policy in a given state. In this paper, we propose Policy-extended Value Function Approximator (PeVFA) which extends the conventional value to be not only a function of state but also an explicit policy representation. Such an extension enables PeVFA to preserve values of multiple policies in contrast to a conventional one with limited capacity for only one policy, inducing the new characteristic of \emph{value generalization among policies}. From both the theoretical and empirical lens, we study value generalization along the policy improvement path (called local generalization), from which we derive a new form of Generalized Policy Iteration with PeVFA to improve the conventional learning process. Besides, we propose a framework to learn the representation of an RL policy, studying several different approaches to learn an effective policy representation from policy network parameters and state-action pairs through contrastive learning and action prediction. In our experiments, Proximal Policy Optimization (PPO) with PeVFA significantly outperforms its vanilla counterpart in MuJoCo continuous control tasks, demonstrating the effectiveness of value generalization offered by PeVFA and policy representation learning.
Towards Effective Context for Meta-Reinforcement Learning: an Approach based on Contrastive Learning
Oct 07, 2020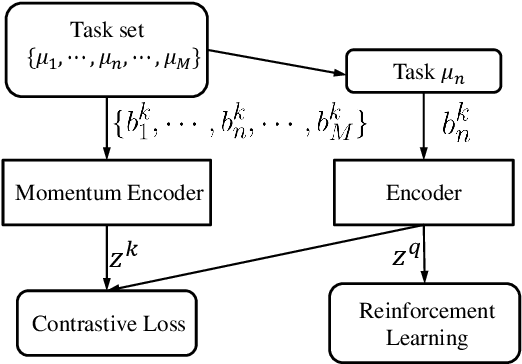

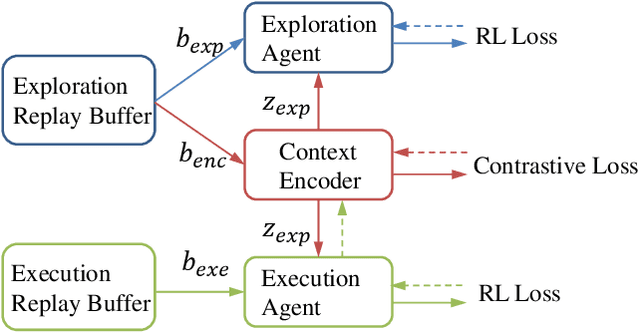
Context, the embedding of previous collected trajectories, is a powerful construct for Meta-Reinforcement Learning (Meta-RL) algorithms. By conditioning on an effective context, Meta-RL policies can easily generalize to new tasks within a few adaptation steps. We argue that improving the quality of context involves answering two questions: 1. How to train a compact and sufficient encoder that can embed the task-specific information contained in prior trajectories? 2. How to collect informative trajectories of which the corresponding context reflects the specification of tasks? To this end, we propose a novel Meta-RL framework called CCM (Contrastive learning augmented Context-based Meta-RL). We first focus on the contrastive nature behind different tasks and leverage it to train a compact and sufficient context encoder. Further, we train a separate exploration policy and theoretically derive a new information-gain-based objective which aims to collect informative trajectories in a few steps. Empirically, we evaluate our approaches on common benchmarks as well as several complex sparse-reward environments. The experimental results show that CCM outperforms state-of-the-art algorithms by addressing previously mentioned problems respectively.
Triple-GAIL: A Multi-Modal Imitation Learning Framework with Generative Adversarial Nets
May 22, 2020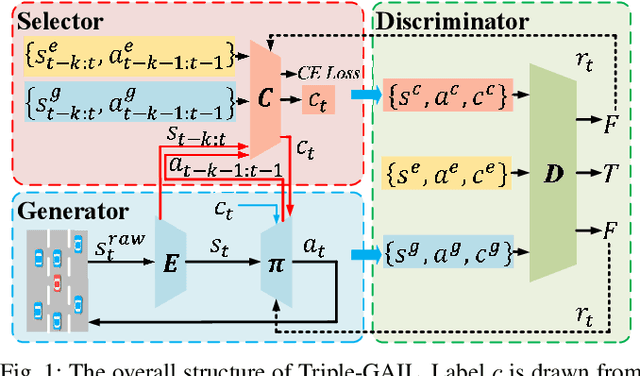
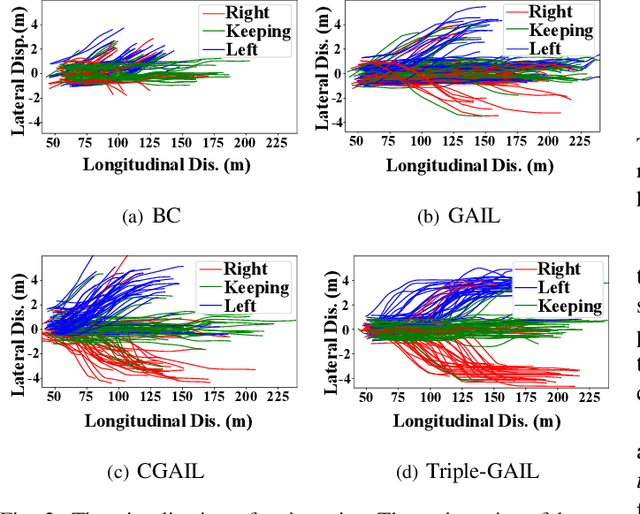

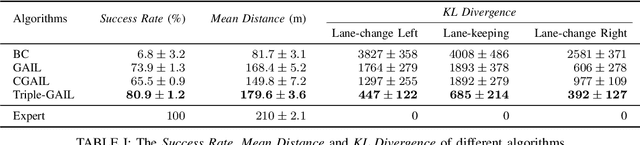
Generative adversarial imitation learning (GAIL) has shown promising results by taking advantage of generative adversarial nets, especially in the field of robot learning. However, the requirement of isolated single modal demonstrations limits the scalability of the approach to real world scenarios such as autonomous vehicles' demand for a proper understanding of human drivers' behavior. In this paper, we propose a novel multi-modal GAIL framework, named Triple-GAIL, that is able to learn skill selection and imitation jointly from both expert demonstrations and continuously generated experiences with data augmentation purpose by introducing an auxiliary skill selector. We provide theoretical guarantees on the convergence to optima for both of the generator and the selector respectively. Experiments on real driver trajectories and real-time strategy game datasets demonstrate that Triple-GAIL can better fit multi-modal behaviors close to the demonstrators and outperforms state-of-the-art methods.
Multi-Agent Interactions Modeling with Correlated Policies
Jan 20, 2020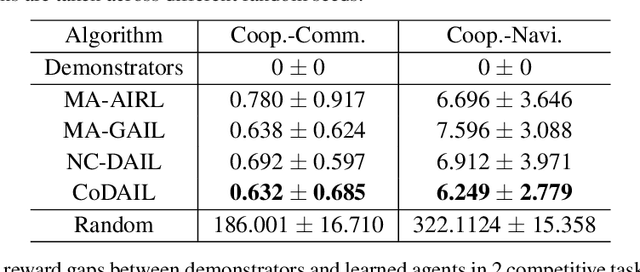
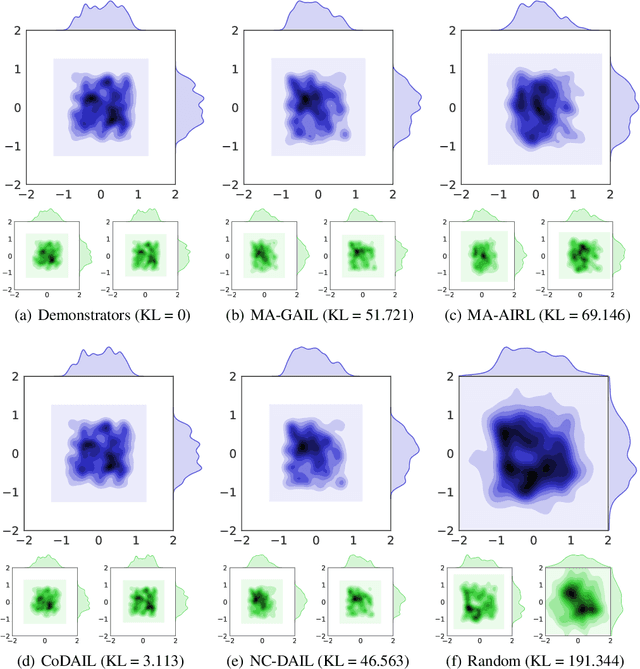
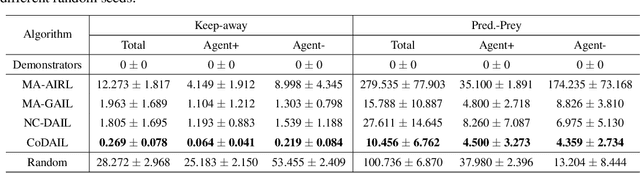
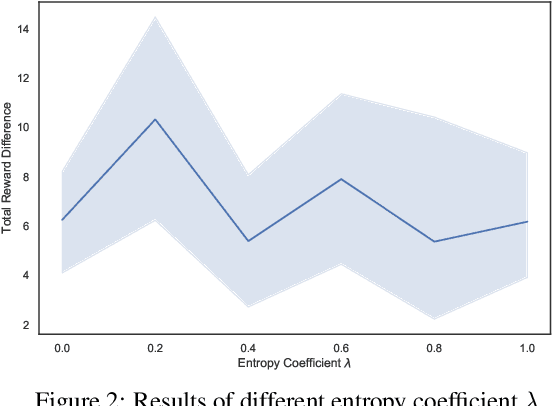
In multi-agent systems, complex interacting behaviors arise due to the high correlations among agents. However, previous work on modeling multi-agent interactions from demonstrations is primarily constrained by assuming the independence among policies and their reward structures. In this paper, we cast the multi-agent interactions modeling problem into a multi-agent imitation learning framework with explicit modeling of correlated policies by approximating opponents' policies, which can recover agents' policies that can regenerate similar interactions. Consequently, we develop a Decentralized Adversarial Imitation Learning algorithm with Correlated policies (CoDAIL), which allows for decentralized training and execution. Various experiments demonstrate that CoDAIL can better regenerate complex interactions close to the demonstrators and outperforms state-of-the-art multi-agent imitation learning methods. Our code is available at \url{https://github.com/apexrl/CoDAIL}.
Neighborhood Cognition Consistent Multi-Agent Reinforcement Learning
Dec 03, 2019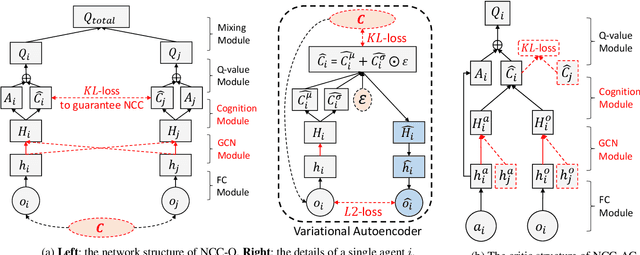
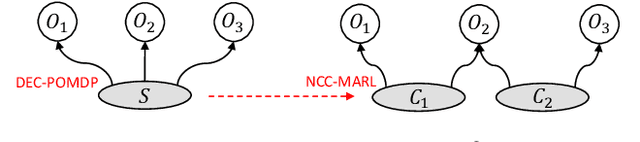
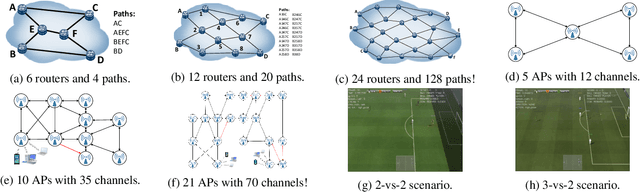
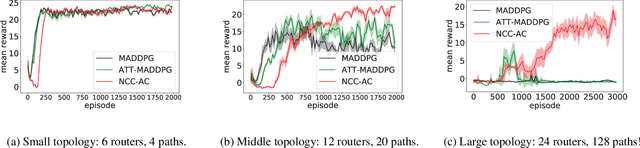
Social psychology and real experiences show that cognitive consistency plays an important role to keep human society in order: if people have a more consistent cognition about their environments, they are more likely to achieve better cooperation. Meanwhile, only cognitive consistency within a neighborhood matters because humans only interact directly with their neighbors. Inspired by these observations, we take the first step to introduce \emph{neighborhood cognitive consistency} (NCC) into multi-agent reinforcement learning (MARL). Our NCC design is quite general and can be easily combined with existing MARL methods. As examples, we propose neighborhood cognition consistent deep Q-learning and Actor-Critic to facilitate large-scale multi-agent cooperations. Extensive experiments on several challenging tasks (i.e., packet routing, wifi configuration, and Google football player control) justify the superior performance of our methods compared with state-of-the-art MARL approaches.