 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdit Where You Mean: Region-Aware Adapter Injection for Mask-Free Local Image Editing
Apr 26, 2026Large diffusion transformers (DiTs) follow global editing instructions well but consistently leak local edits into unrelated regions, because joint-attention architectures offer no explicit channel telling the network where to apply the edit. We introduce REDEdit, a co-trained, instruction- and region-aware adapter framework that retrofits a frozen DiT into a precise local editor without modifying its backbone weights. A lightweight Block Adapter at every transformer block injects a structured condition stream that factorizes what to edit (instruction semantics) from where to edit (spatial mask); a learned SpatialGate routes the adapter signal selectively into the edit region while keeping the rest of the image near-identical to the source; and a Region-Aware Loss focuses the training objective on the changing pixels. Because these components make the backbone's internal representation mask-aware end-to-end, a thin MaskPredictor head trained jointly with the editor can ground the edit region directly from the instruction and source image eliminating any user-mask requirement at deployment. We evaluate on two complementary benchmarks: MagicBrush (paired ground-truth targets) to measure pixel-level preservation and edit accuracy, and Emu-Edit Test (no ground-truth images, 9 diverse edit categories) to stress-test instruction following and generalization across edit types. On both, REDEdit achieves state-of-the-art results, simultaneously outperforming mask-free and oracle-mask baselines. A seven-variant ablation cleanly isolates the contribution of each component.
EditCaption: Human-Aligned Instruction Synthesis for Image Editing via Supervised Fine-Tuning and Direct Preference Optimization
Apr 09, 2026High-quality training triplets (source-target image pairs with precise editing instructions) are a critical bottleneck for scaling instruction-guided image editing models. Vision-language models (VLMs) are widely used for automated instruction synthesis, but we identify three systematic failure modes in image-pair settings: orientation inconsistency (e.g., left/right confusion), viewpoint ambiguity, and insufficient fine-grained attribute description. Human evaluation shows that over 47% of instructions from strong baseline VLMs contain critical errors unusable for downstream training. We propose EditCaption, a scalable two-stage post-training pipeline for VLM-based instruction synthesis. Stage 1 builds a 100K supervised fine-tuning (SFT) dataset by combining GLM automatic annotation, EditScore-based filtering, and human refinement for spatial, directional, and attribute-level accuracy. Stage 2 collects 10K human preference pairs targeting the three failure modes and applies direct preference optimization (DPO) for alignment beyond SFT alone. On Eval-400, ByteMorph-Bench, and HQ-Edit, fine-tuned Qwen3-VL models outperform open-source baselines; the 235B model reaches 4.712 on Eval-400 (vs. Gemini-3-Pro 4.706, GPT-4.1 4.220, Kimi-K2.5 4.111) and 4.588 on ByteMorph-Bench (vs. Gemini-3-Pro 4.522, GPT-4.1 3.412). Human evaluation shows critical errors falling from 47.75% to 23% and correctness rising from 41.75% to 66%. The work offers a practical path to scalable, human-aligned instruction synthesis for image editing data.
PROMO: Promptable Outfitting for Efficient High-Fidelity Virtual Try-On
Mar 12, 2026Virtual Try-on (VTON) has become a core capability for online retail, where realistic try-on results provide reliable fit guidance, reduce returns, and benefit both consumers and merchants. Diffusion-based VTON methods achieve photorealistic synthesis, yet often rely on intricate architectures such as auxiliary reference networks and suffer from slow sampling, making the trade-off between fidelity and efficiency a persistent challenge. We approach VTON as a structured image editing problem that demands strong conditional generation under three key requirements: subject preservation, faithful texture transfer, and seamless harmonization. Under this perspective, our training framework is generic and transfers to broader image editing tasks. Moreover, the paired data produced by VTON constitutes a rich supervisory resource for training general-purpose editors. We present PROMO, a promptable virtual try-on framework built upon a Flow Matching DiT backbone with latent multi-modal conditional concatenation. By leveraging conditioning efficiency and self-reference mechanisms, our approach substantially reduces inference overhead. On standard benchmarks, PROMO surpasses both prior VTON methods and general image editing models in visual fidelity while delivering a competitive balance between quality and speed. These results demonstrate that flow-matching transformers, coupled with latent multi-modal conditioning and self-reference acceleration, offer an effective and training-efficient solution for high-quality virtual try-on.
IdGlow: Dynamic Identity Modulation for Multi-Subject Generation
Feb 28, 2026Multi-subject image generation requires seamlessly harmonizing multiple reference identities within a coherent scene. However, existing methods relying on rigid spatial masks or localized attention often struggle with the "stability-plasticity dilemma," particularly failing in tasks that require complex structural deformations, such as identity-preserving age transformation. To address this, we present IdGlow, a mask-free, progressive two-stage framework built upon Flow Matching diffusion models. In the supervised fine-tuning (SFT) stage, we introduce task-adaptive timestep scheduling aligned with diffusion generative dynamics: a linear decay schedule that progressively relaxes constraints for natural group composition, and a temporal gating mechanism that concentrates identity injection within a critical semantic window, successfully preserving adult facial semantics without overriding child-like anatomical structures. To resolve attribute leakage and semantic ambiguity without explicit layout inputs, we further integrate a badcase-driven Vision-Language Model (VLM) for precise, context-aware prompt synthesis. In the second stage, we design a Fine-Grained Group-Level Direct Preference Optimization (DPO) with a weighted margin formulation to simultaneously eliminate multi-subject artifacts, elevate texture harmony, and recalibrate identity fidelity towards real-world distributions. Extensive experiments on two challenging benchmarks -- direct multi-person fusion and age-transformed group generation -- demonstrate that IdGlow fundamentally mitigates the stability-plasticity conflict, achieving a superior Pareto balance between state-of-the-art facial fidelity and commercial-grade aesthetic quality.
XRL-Bench: A Benchmark for Evaluating and Comparing Explainable Reinforcement Learning Techniques
Feb 20, 2024



Reinforcement Learning (RL) has demonstrated substantial potential across diverse fields, yet understanding its decision-making process, especially in real-world scenarios where rationality and safety are paramount, is an ongoing challenge. This paper delves in to Explainable RL (XRL), a subfield of Explainable AI (XAI) aimed at unravelling the complexities of RL models. Our focus rests on state-explaining techniques, a crucial subset within XRL methods, as they reveal the underlying factors influencing an agent's actions at any given time. Despite their significant role, the lack of a unified evaluation framework hinders assessment of their accuracy and effectiveness. To address this, we introduce XRL-Bench, a unified standardized benchmark tailored for the evaluation and comparison of XRL methods, encompassing three main modules: standard RL environments, explainers based on state importance, and standard evaluators. XRL-Bench supports both tabular and image data for state explanation. We also propose TabularSHAP, an innovative and competitive XRL method. We demonstrate the practical utility of TabularSHAP in real-world online gaming services and offer an open-source benchmark platform for the straightforward implementation and evaluation of XRL methods. Our contributions facilitate the continued progression of XRL technology.
Towards Solving Fuzzy Tasks with Human Feedback: A Retrospective of the MineRL BASALT 2022 Competition
Mar 23, 2023



To facilitate research in the direction of fine-tuning foundation models from human feedback, we held the MineRL BASALT Competition on Fine-Tuning from Human Feedback at NeurIPS 2022. The BASALT challenge asks teams to compete to develop algorithms to solve tasks with hard-to-specify reward functions in Minecraft. Through this competition, we aimed to promote the development of algorithms that use human feedback as channels to learn the desired behavior. We describe the competition and provide an overview of the top solutions. We conclude by discussing the impact of the competition and future directions for improvement.
Cooperative Multi-Agent Transfer Learning with Level-Adaptive Credit Assignment
Jun 03, 2021
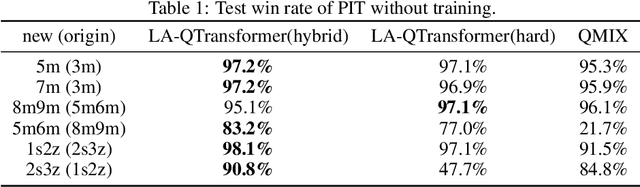
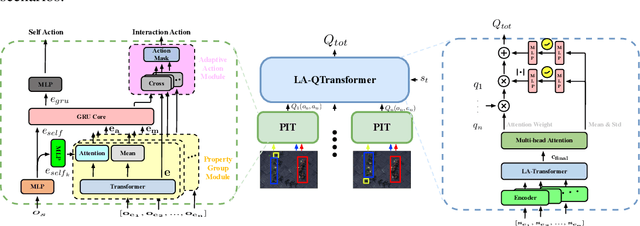
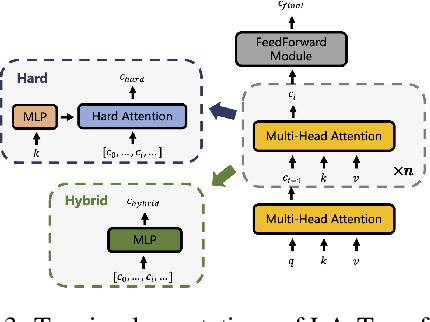
Extending transfer learning to cooperative multi-agent reinforcement learning (MARL) has recently received much attention. In contrast to the single-agent setting, the coordination indispensable in cooperative MARL constrains each agent's policy. However, existing transfer methods focus exclusively on agent policy and ignores coordination knowledge. We propose a new architecture that realizes robust coordination knowledge transfer through appropriate decomposition of the overall coordination into several coordination patterns. We use a novel mixing network named level-adaptive QTransformer (LA-QTransformer) to realize agent coordination that considers credit assignment, with appropriate coordination patterns for different agents realized by a novel level-adaptive Transformer (LA-Transformer) dedicated to the transfer of coordination knowledge. In addition, we use a novel agent network named Population Invariant agent with Transformer (PIT) to realize the coordination transfer in more varieties of scenarios. Extensive experiments in StarCraft II micro-management show that LA-QTransformer together with PIT achieves superior performance compared with state-of-the-art baselines.
Multi-Agent Reinforcement Learning with Graph Clustering
Sep 28, 2020
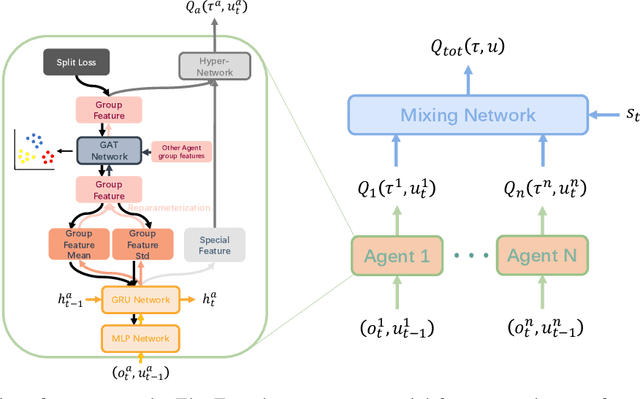
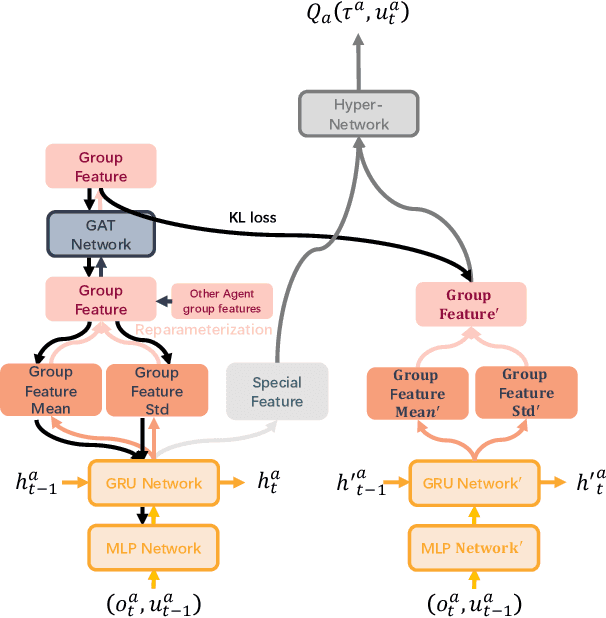
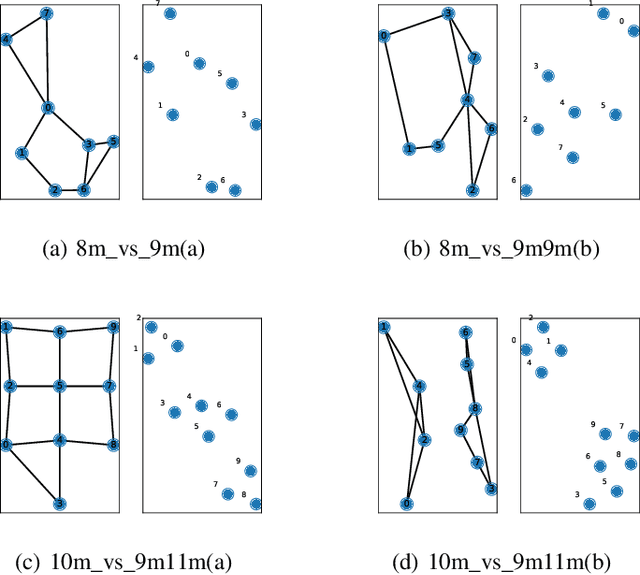
In this paper, the group concept is introduced into multi-agent reinforcement learning. Agents, in this method, are divided into several groups, each of which completes a specific subtask, cooperating to accomplish the main task. In order to exchange information between agents, present methods mainly use the communication vector; this can lead to communication redundancy. To solve this problem, a MARL based method is proposed on graph clustering. It allows agents to learn group features adaptively and replaces the communication operation. In this approach, agent features are divided into two types, including in-group and individual features. The generality and differences between agents are represented by them, respectively. Based on the graph attention network(GAT), the graph clustering method is introduced to optimize agent group feature. These features are then applied to generate individual Q value. The split loss is presented to distinguish agent features in order to overcome the consistent problem brought by GAT. The proposed method is easy to be converted into the CTDE framework by using the Kullback-Leibler divergence method. Empirical results are evaluated on a challenging set of StarCraft II micromanagement tasks. The result reveals that the proposed method achieves significant performance improvements in the SMAC domain, and can maintain a great performance with the increase in the number of agents.