 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixing and Shifting: Exploiting Global and Local Dependencies in Vision MLPs
Feb 14, 2022Token-mixing multi-layer perceptron (MLP) models have shown competitive performance in computer vision tasks with a simple architecture and relatively small computational cost. Their success in maintaining computation efficiency is mainly attributed to avoiding the use of self-attention that is often computationally heavy, yet this is at the expense of not being able to mix tokens both globally and locally. In this paper, to exploit both global and local dependencies without self-attention, we present Mix-Shift-MLP (MS-MLP) which makes the size of the local receptive field used for mixing increase with respect to the amount of spatial shifting. In addition to conventional mixing and shifting techniques, MS-MLP mixes both neighboring and distant tokens from fine- to coarse-grained levels and then gathers them via a shifting operation. This directly contributes to the interactions between global and local tokens. Being simple to implement, MS-MLP achieves competitive performance in multiple vision benchmarks. For example, an MS-MLP with 85 million parameters achieves 83.8% top-1 classification accuracy on ImageNet-1K. Moreover, by combining MS-MLP with state-of-the-art Vision Transformers such as the Swin Transformer, we show MS-MLP achieves further improvements on three different model scales, e.g., by 0.5% on ImageNet-1K classification with Swin-B. The code is available at: https://github.com/JegZheng/MS-MLP.
Reasoning Like Program Executors
Jan 27, 2022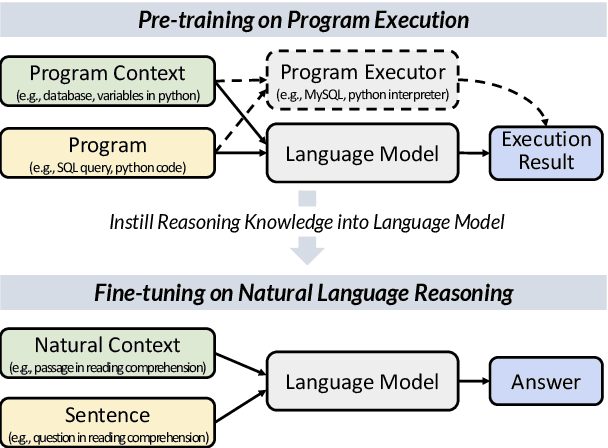

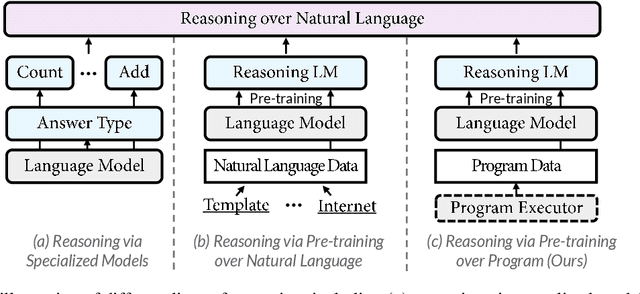
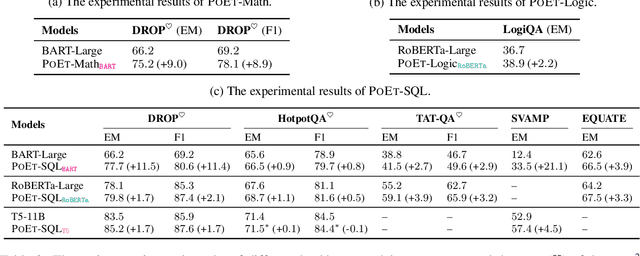
Reasoning over natural language is a long-standing goal for the research community. However, studies have shown that existing language models are inadequate in reasoning. To address the issue, we present POET, a new pre-training paradigm. Through pre-training language models with programs and their execution results, POET empowers language models to harvest the reasoning knowledge possessed in program executors via a data-driven approach. POET is conceptually simple and can be instantiated by different kinds of programs. In this paper, we show three empirically powerful instances, i.e., POET-Math, POET-Logic, and POET-SQL. Experimental results on six benchmarks demonstrate that POET can significantly boost model performance on natural language reasoning, such as numerical reasoning, logical reasoning, and multi-hop reasoning. Taking the DROP benchmark as a representative example, POET improves the F1 metric of BART from 69.2% to 80.6%. Furthermore, POET shines in giant language models, pushing the F1 metric of T5-11B to 87.6% and achieving a new state-of-the-art performance on DROP. POET opens a new gate on reasoning-enhancement pre-training and we hope our analysis would shed light on the future research of reasoning like program executors.
CodeRetriever: Unimodal and Bimodal Contrastive Learning
Jan 26, 2022
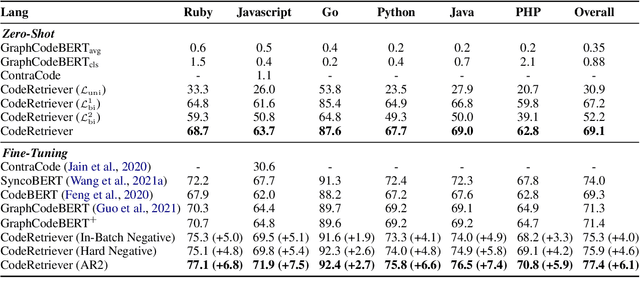
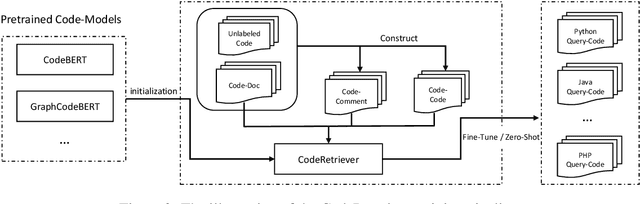
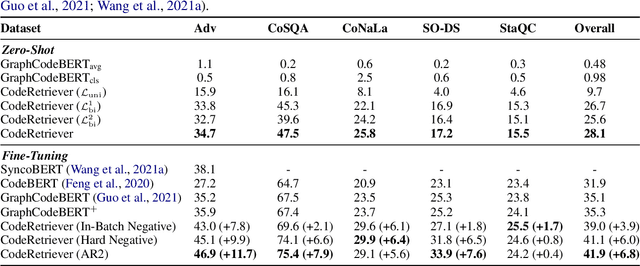
In this paper, we propose the CodeRetriever model, which combines the unimodal and bimodal contrastive learning to train function-level code semantic representations, specifically for the code search task. For unimodal contrastive learning, we design a semantic-guided method to build positive code pairs based on the documentation and function name. For bimodal contrastive learning, we leverage the documentation and in-line comments of code to build text-code pairs. Both contrastive objectives can fully leverage the large-scale code corpus for pre-training. Experimental results on several public benchmarks, (i.e., CodeSearch, CoSQA, etc.) demonstrate the effectiveness of CodeRetriever in the zero-shot setting. By fine-tuning with domain/language specified downstream data, CodeRetriever achieves the new state-of-the-art performance with significant improvement over existing code pre-trained models. We will make the code, model checkpoint, and constructed datasets publicly available.
Contextual Bandit Applications in Customer Support Bot
Dec 06, 2021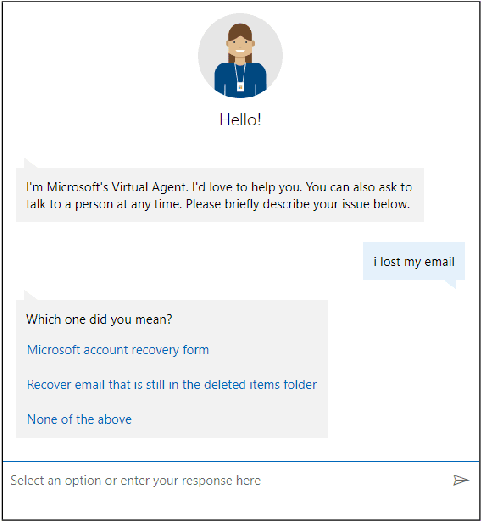
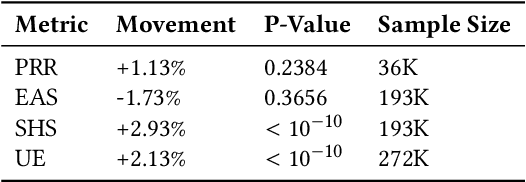
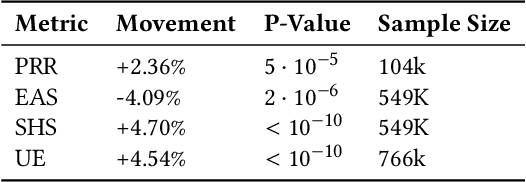
Virtual support agents have grown in popularity as a way for businesses to provide better and more accessible customer service. Some challenges in this domain include ambiguous user queries as well as changing support topics and user behavior (non-stationarity). We do, however, have access to partial feedback provided by the user (clicks, surveys, and other events) which can be leveraged to improve the user experience. Adaptable learning techniques, like contextual bandits, are a natural fit for this problem setting. In this paper, we discuss real-world implementations of contextual bandits (CB) for the Microsoft virtual agent. It includes intent disambiguation based on neural-linear bandits (NLB) and contextual recommendations based on a collection of multi-armed bandits (MAB). Our solutions have been deployed to production and have improved key business metrics of the Microsoft virtual agent, as confirmed by A/B experiments. Results include a relative increase of over 12% in problem resolution rate and relative decrease of over 4% in escalations to a human operator. While our current use cases focus on intent disambiguation and contextual recommendation for support bots, we believe our methods can be extended to other domains.
* in KDD 2021
DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing
Nov 18, 2021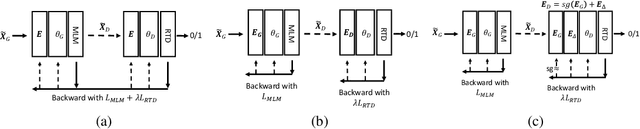
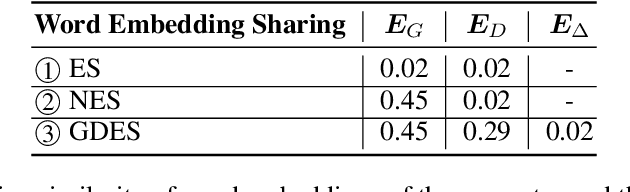
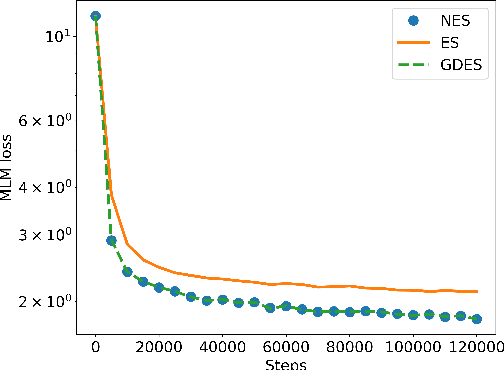
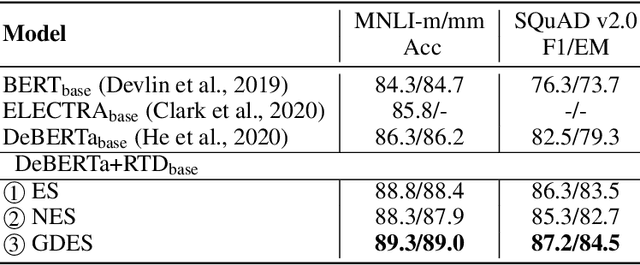
This paper presents a new pre-trained language model, DeBERTaV3, which improves the original DeBERTa model by replacing mask language modeling (MLM) with replaced token detection (RTD), a more sample-efficient pre-training task. Our analysis shows that vanilla embedding sharing in ELECTRA hurts training efficiency and model performance. This is because the training losses of the discriminator and the generator pull token embeddings in different directions, creating the "tug-of-war" dynamics. We thus propose a new gradient-disentangled embedding sharing method that avoids the tug-of-war dynamics, improving both training efficiency and the quality of the pre-trained model. We have pre-trained DeBERTaV3 using the same settings as DeBERTa to demonstrate its exceptional performance on a wide range of downstream natural language understanding (NLU) tasks. Taking the GLUE benchmark with eight tasks as an example, the DeBERTaV3 Large model achieves a 91.37% average score, which is 1.37% over DeBERTa and 1.91% over ELECTRA, setting a new state-of-the-art (SOTA) among the models with a similar structure. Furthermore, we have pre-trained a multi-lingual model mDeBERTa and observed a larger improvement over strong baselines compared to English models. For example, the mDeBERTa Base achieves a 79.8% zero-shot cross-lingual accuracy on XNLI and a 3.6% improvement over XLM-R Base, creating a new SOTA on this benchmark. We have made our pre-trained models and inference code publicly available at https://github.com/microsoft/DeBERTa.
DSEE: Dually Sparsity-embedded Efficient Tuning of Pre-trained Language Models
Oct 30, 2021
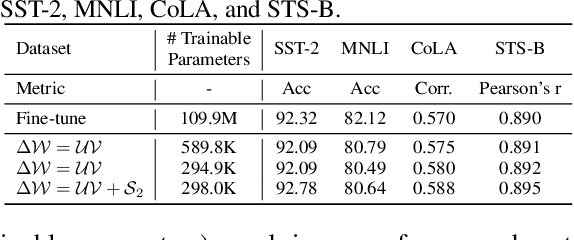
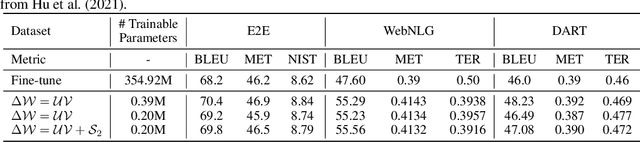
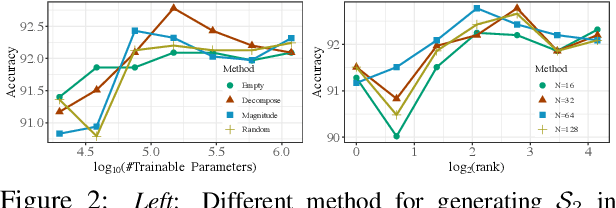
Gigantic pre-trained models have become central to natural language processing (NLP), serving as the starting point for fine-tuning towards a range of downstream tasks. However, two pain points persist for this paradigm: (a) as the pre-trained models grow bigger (e.g., 175B parameters for GPT-3), even the fine-tuning process can be time-consuming and computationally expensive; (b) the fine-tuned model has the same size as its starting point by default, which is neither sensible due to its more specialized functionality, nor practical since many fine-tuned models will be deployed in resource-constrained environments. To address these pain points, we propose a framework for resource- and parameter-efficient fine-tuning by leveraging the sparsity prior in both weight updates and the final model weights. Our proposed framework, dubbed Dually Sparsity-Embedded Efficient Tuning (DSEE), aims to achieve two key objectives: (i) parameter efficient fine-tuning - by enforcing sparsity-aware weight updates on top of the pre-trained weights; and (ii) resource-efficient inference - by encouraging a sparse weight structure towards the final fine-tuned model. We leverage sparsity in these two directions by exploiting both unstructured and structured sparse patterns in pre-trained language models via magnitude-based pruning and $\ell_1$ sparse regularization. Extensive experiments and in-depth investigations, with diverse network backbones (i.e., BERT, GPT-2, and DeBERTa) on dozens of datasets, consistently demonstrate highly impressive parameter-/training-/inference-efficiency, while maintaining competitive downstream transfer performance. For instance, our DSEE-BERT obtains about $35\%$ inference FLOPs savings with <1% trainable parameters and comparable performance to conventional fine-tuning. Codes are available in https://github.com/VITA-Group/DSEE.
Adversarial Retriever-Ranker for dense text retrieval
Oct 29, 2021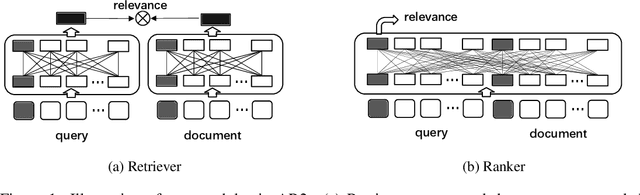

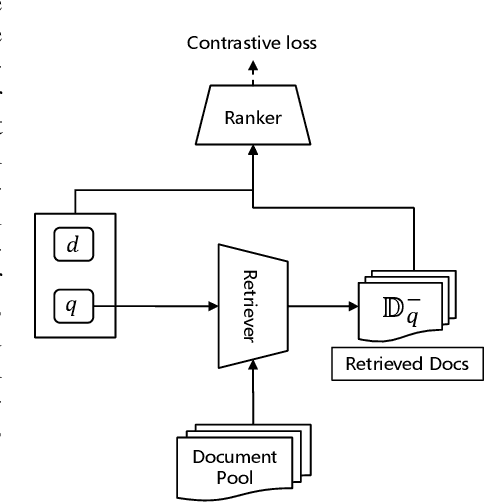
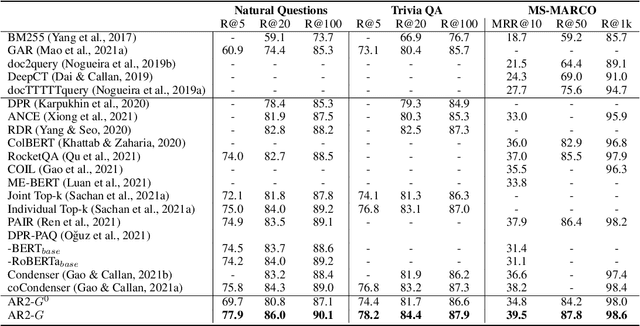
Current dense text retrieval models face two typical challenges. First, it adopts a siamese dual-encoder architecture to encode query and document independently for fast indexing and searching, whereas neglecting the finer-grained term-wise interactions. This results in a sub-optimal recall performance. Second, it highly relies on a negative sampling technique to build up the negative documents in its contrastive loss. To address these challenges, we present Adversarial Retriever-Ranker (AR2), which consists of a dual-encoder retriever plus a cross-encoder ranker. The two models are jointly optimized according to a minimax adversarial objective: the retriever learns to retrieve negative documents to cheat the ranker, while the ranker learns to rank a collection of candidates including both the ground-truth and the retrieved ones, as well as providing progressive direct feedback to the dual-encoder retriever. Through this adversarial game, the retriever gradually produces harder negative documents to train a better ranker, whereas the cross-encoder ranker provides progressive feedback to improve retriever. We evaluate AR2 on three benchmarks. Experimental results show that AR2 consistently and significantly outperforms existing dense retriever methods and achieves new state-of-the-art results on all of them. This includes the improvements on Natural Questions R@5 to 77.9%(+2.1%), TriviaQA R@5 to 78.2%(+1.4), and MS-MARCO MRR@10 to 39.5%(+1.3%). We will make our code, models, and data publicly available.
A Good Prompt Is Worth Millions of Parameters? Low-resource Prompt-based Learning for Vision-Language Models
Oct 16, 2021
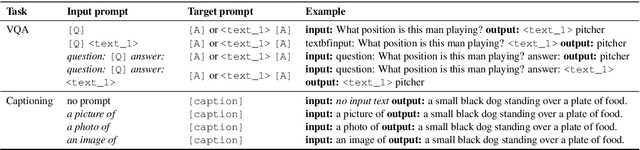
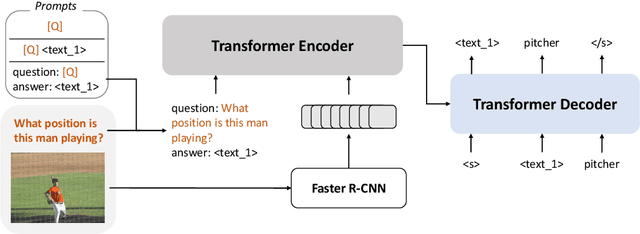
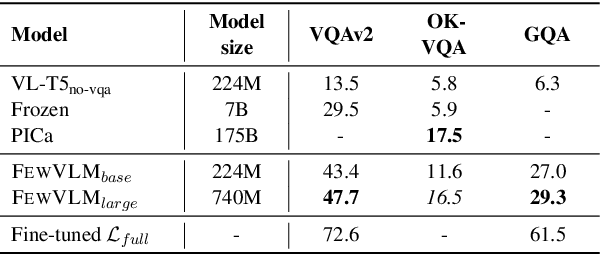
Large pretrained vision-language (VL) models can learn a new task with a handful of examples or generalize to a new task without fine-tuning. However, these gigantic VL models are hard to deploy for real-world applications due to their impractically huge model size and slow inference speed. In this work, we propose FewVLM, a few-shot prompt-based learner on vision-language tasks. We pretrain a sequence-to-sequence Transformer model with both prefix language modeling (PrefixLM) and masked language modeling (MaskedLM), and introduce simple prompts to improve zero-shot and few-shot performance on VQA and image captioning. Experimental results on five VQA and captioning datasets show that \method\xspace outperforms Frozen which is 31 times larger than ours by 18.2% point on zero-shot VQAv2 and achieves comparable results to a 246$\times$ larger model, PICa. We observe that (1) prompts significantly affect zero-shot performance but marginally affect few-shot performance, (2) MaskedLM helps few-shot VQA tasks while PrefixLM boosts captioning performance, and (3) performance significantly increases when training set size is small.
XLM-K: Improving Cross-Lingual Language Model Pre-Training with Multilingual Knowledge
Sep 26, 2021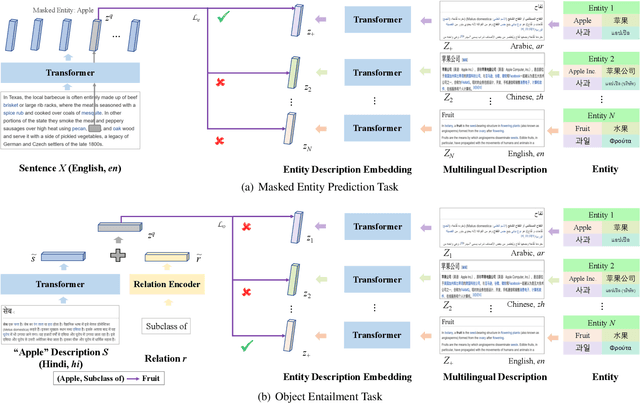
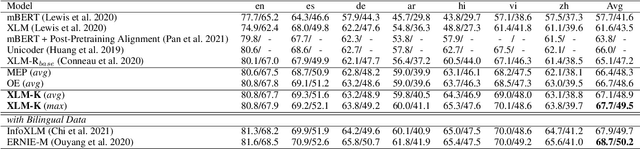
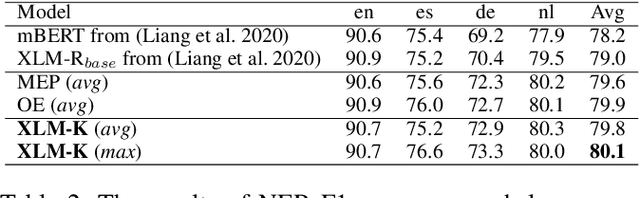

Cross-lingual pre-training has achieved great successes using monolingual and bilingual plain text corpora. However, existing pre-trained models neglect multilingual knowledge, which is language agnostic but comprises abundant cross-lingual structure alignment. In this paper, we propose XLM-K, a cross-lingual language model incorporating multilingual knowledge in pre-training. XLM-K augments existing multilingual pre-training with two knowledge tasks, namely Masked Entity Prediction Task and Object Entailment Task. We evaluate XLM-K on MLQA, NER and XNLI. Experimental results clearly demonstrate significant improvements over existing multilingual language models. The results on MLQA and NER exhibit the superiority of XLM-K in knowledge related tasks. The success in XNLI shows a better cross-lingual transferability obtained in XLM-K. What is more, we provide a detailed probing analysis to confirm the desired knowledge captured in our pre-training regimen.
ARCH: Efficient Adversarial Regularized Training with Caching
Sep 15, 2021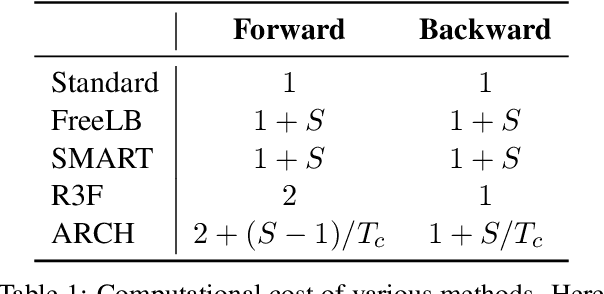
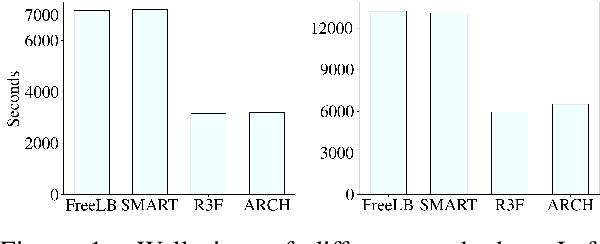
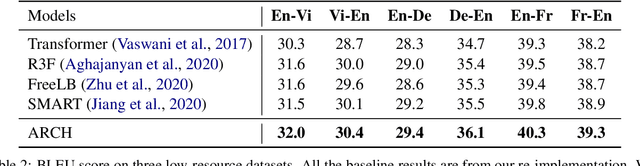
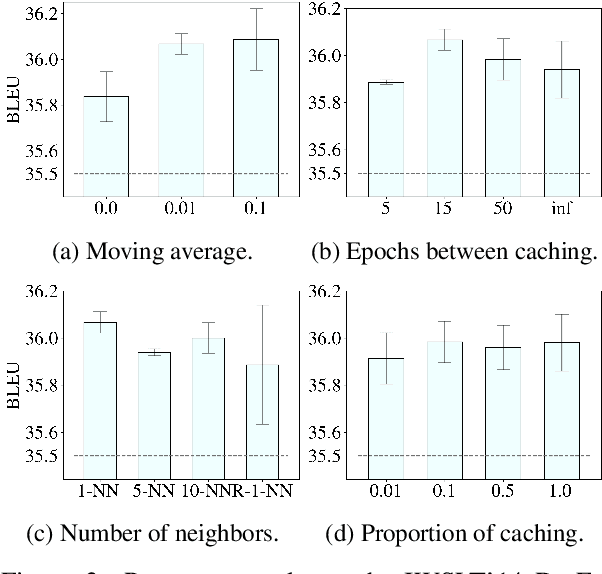
Adversarial regularization can improve model generalization in many natural language processing tasks. However, conventional approaches are computationally expensive since they need to generate a perturbation for each sample in each epoch. We propose a new adversarial regularization method ARCH (adversarial regularization with caching), where perturbations are generated and cached once every several epochs. As caching all the perturbations imposes memory usage concerns, we adopt a K-nearest neighbors-based strategy to tackle this issue. The strategy only requires caching a small amount of perturbations, without introducing additional training time. We evaluate our proposed method on a set of neural machine translation and natural language understanding tasks. We observe that ARCH significantly eases the computational burden (saves up to 70\% of computational time in comparison with conventional approaches). More surprisingly, by reducing the variance of stochastic gradients, ARCH produces a notably better (in most of the tasks) or comparable model generalization. Our code is publicly available.