 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Effective Proxy Reward Model Construction with On-Policy and Active Learning
Jul 02, 2024



Reinforcement learning with human feedback (RLHF), as a widely adopted approach in current large language model pipelines, is \textit{bottlenecked by the size of human preference data}. While traditional methods rely on offline preference dataset constructions, recent approaches have shifted towards online settings, where a learner uses a small amount of labeled seed data and a large pool of unlabeled prompts to iteratively construct new preference data through self-generated responses and high-quality reward/preference feedback. However, most current online algorithms still focus on preference labeling during policy model updating with given feedback oracles, which incurs significant expert query costs. \textit{We are the first to explore cost-effective proxy reward oracles construction strategies for further labeling preferences or rewards with extremely limited labeled data and expert query budgets}. Our approach introduces two key innovations: (1) on-policy query to avoid OOD and imbalance issues in seed data, and (2) active learning to select the most informative data for preference queries. Using these methods, we train a evaluation model with minimal expert-labeled data, which then effectively labels nine times more preference pairs for further RLHF training. For instance, our model using Direct Preference Optimization (DPO) gains around over 1% average improvement on AlpacaEval2, MMLU-5shot and MMLU-0shot, with only 1.7K query cost. Our methodology is orthogonal to other direct expert query-based strategies and therefore might be integrated with them to further reduce query costs.
Active, anytime-valid risk controlling prediction sets
Jun 15, 2024

Rigorously establishing the safety of black-box machine learning models concerning critical risk measures is important for providing guarantees about model behavior. Recently, Bates et. al. (JACM '24) introduced the notion of a risk controlling prediction set (RCPS) for producing prediction sets that are statistically guaranteed low risk from machine learning models. Our method extends this notion to the sequential setting, where we provide guarantees even when the data is collected adaptively, and ensures that the risk guarantee is anytime-valid, i.e., simultaneously holds at all time steps. Further, we propose a framework for constructing RCPSes for active labeling, i.e., allowing one to use a labeling policy that chooses whether to query the true label for each received data point and ensures that the expected proportion of data points whose labels are queried are below a predetermined label budget. We also describe how to use predictors (i.e., the machine learning model for which we provide risk control guarantees) to further improve the utility of our RCPSes by estimating the expected risk conditioned on the covariates. We characterize the optimal choices of label policy and predictor under a fixed label budget and show a regret result that relates the estimation error of the optimal labeling policy and predictor to the wealth process that underlies our RCPSes. Lastly, we present practical ways of formulating label policies and empirically show that our label policies use fewer labels to reach higher utility than naive baseline labeling strategies (e.g., labeling all points, randomly labeling points) on both simulations and real data.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models
Oct 23, 2023



Quantization is an indispensable technique for serving Large Language Models (LLMs) and has recently found its way into LoRA fine-tuning. In this work we focus on the scenario where quantization and LoRA fine-tuning are applied together on a pre-trained model. In such cases it is common to observe a consistent gap in the performance on downstream tasks between full fine-tuning and quantization plus LoRA fine-tuning approach. In response, we propose LoftQ (LoRA-Fine-Tuning-aware Quantization), a novel quantization framework that simultaneously quantizes an LLM and finds a proper low-rank initialization for LoRA fine-tuning. Such an initialization alleviates the discrepancy between the quantized and full-precision model and significantly improves the generalization in downstream tasks. We evaluate our method on natural language understanding, question answering, summarization, and natural language generation tasks. Experiments show that our method is highly effective and outperforms existing quantization methods, especially in the challenging 2-bit and 2/4-bit mixed precision regimes. We will release our code.
Meet in the Middle: A New Pre-training Paradigm
Mar 13, 2023



Most language models (LMs) are trained and applied in an autoregressive left-to-right fashion, assuming that the next token only depends on the preceding ones. However, this assumption ignores the potential benefits of using the full sequence information during training, and the possibility of having context from both sides during inference. In this paper, we propose a new pre-training paradigm with techniques that jointly improve the training data efficiency and the capabilities of the LMs in the infilling task. The first is a training objective that aligns the predictions of a left-to-right LM with those of a right-to-left LM, trained on the same data but in reverse order. The second is a bidirectional inference procedure that enables both LMs to meet in the middle. We show the effectiveness of our pre-training paradigm with extensive experiments on both programming and natural language models, outperforming strong baselines.
Anytime-valid off-policy inference for contextual bandits
Oct 19, 2022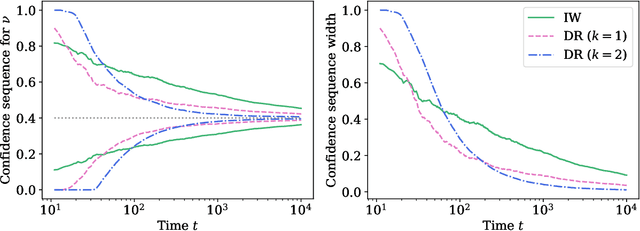

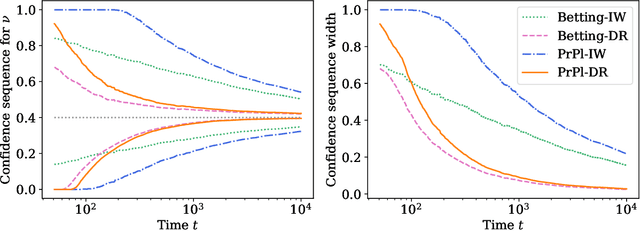

Contextual bandits are a modern staple tool for active sequential experimentation in the tech industry. They involve online learning algorithms that adaptively (over time) learn policies to map observed contexts $X_t$ to actions $A_t$ in an attempt to maximize stochastic rewards $R_t$. This adaptivity raises interesting but hard statistical inference questions, especially counterfactual ones: for example, it is often of interest to estimate the properties of a hypothetical policy that is different from the logging policy that was used to collect the data -- a problem known as "off-policy evaluation" (OPE). Using modern martingale techniques, we present a comprehensive framework for OPE inference that relax many unnecessary assumptions made in past work, significantly improving on them theoretically and empirically. Our methods remain valid in very general settings, and can be employed while the original experiment is still running (that is, not necessarily post-hoc), when the logging policy may be itself changing (due to learning), and even if the context distributions are drifting over time. More concretely, we derive confidence sequences for various functionals of interest in OPE. These include doubly robust ones for time-varying off-policy mean reward values, but also confidence bands for the entire CDF of the off-policy reward distribution. All of our methods (a) are valid at arbitrary stopping times (b) only make nonparametric assumptions, and (c) do not require known bounds on the maximal importance weights, and (d) adapt to the empirical variance of the reward and weight distributions. In summary, our methods enable anytime-valid off-policy inference using adaptively collected contextual bandit data.
Contextual Bandit Applications in Customer Support Bot
Dec 06, 2021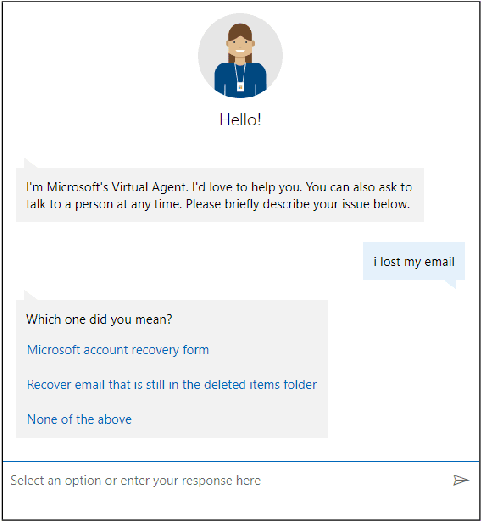
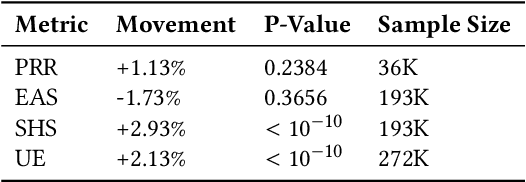
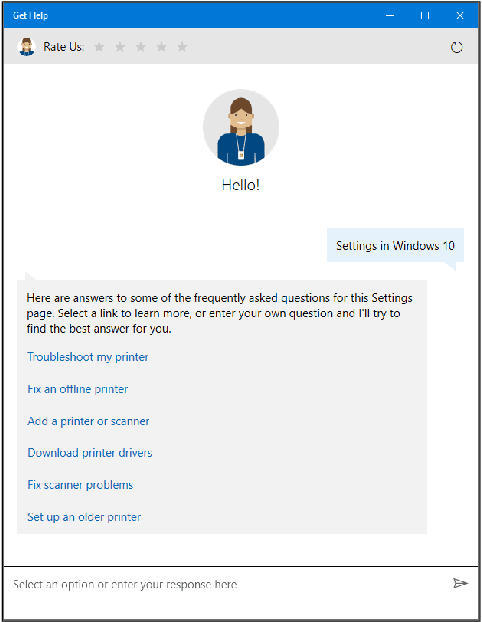
Virtual support agents have grown in popularity as a way for businesses to provide better and more accessible customer service. Some challenges in this domain include ambiguous user queries as well as changing support topics and user behavior (non-stationarity). We do, however, have access to partial feedback provided by the user (clicks, surveys, and other events) which can be leveraged to improve the user experience. Adaptable learning techniques, like contextual bandits, are a natural fit for this problem setting. In this paper, we discuss real-world implementations of contextual bandits (CB) for the Microsoft virtual agent. It includes intent disambiguation based on neural-linear bandits (NLB) and contextual recommendations based on a collection of multi-armed bandits (MAB). Our solutions have been deployed to production and have improved key business metrics of the Microsoft virtual agent, as confirmed by A/B experiments. Results include a relative increase of over 12% in problem resolution rate and relative decrease of over 4% in escalations to a human operator. While our current use cases focus on intent disambiguation and contextual recommendation for support bots, we believe our methods can be extended to other domains.
* in KDD 2021
Off-policy Confidence Sequences
Feb 18, 2021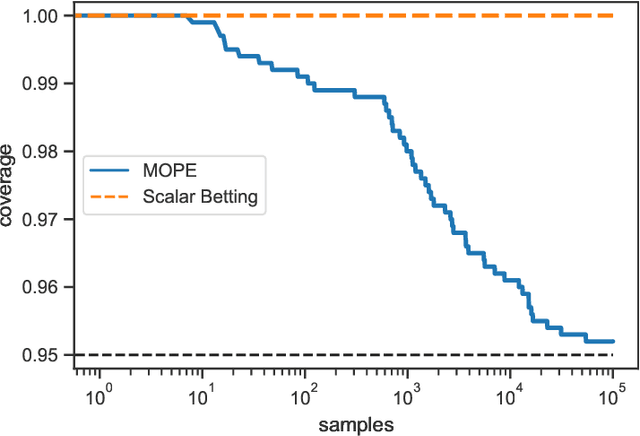

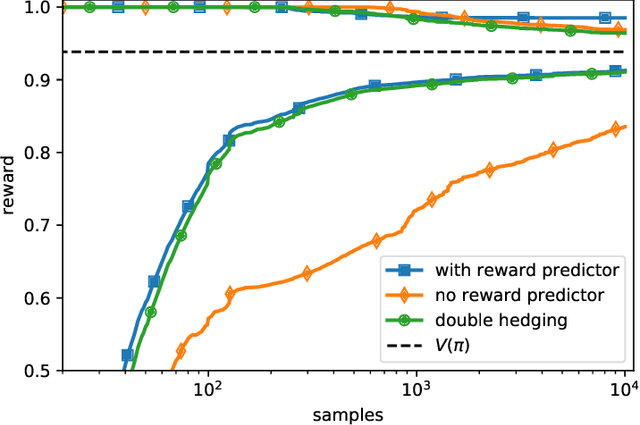
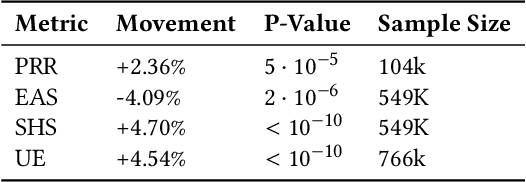
We develop confidence bounds that hold uniformly over time for off-policy evaluation in the contextual bandit setting. These confidence sequences are based on recent ideas from martingale analysis and are non-asymptotic, non-parametric, and valid at arbitrary stopping times. We provide algorithms for computing these confidence sequences that strike a good balance between computational and statistical efficiency. We empirically demonstrate the tightness of our approach in terms of failure probability and width and apply it to the "gated deployment" problem of safely upgrading a production contextual bandit system.
Empirical Likelihood for Contextual Bandits
Jun 21, 2019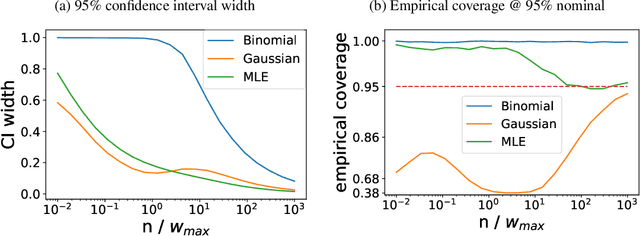
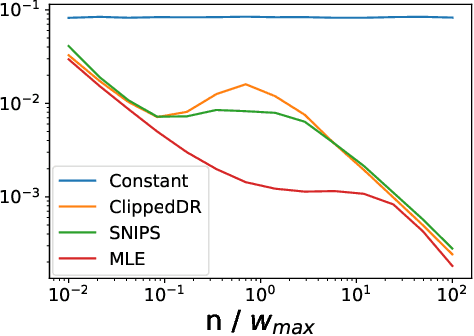
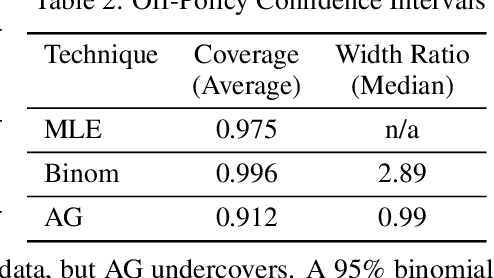
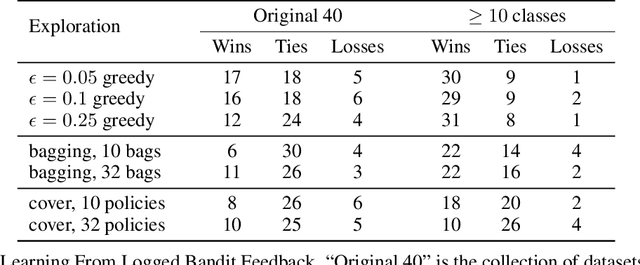
We apply empirical likelihood techniques to contextual bandit policy value estimation, confidence intervals, and learning. We propose a tighter estimator for off-policy evaluation with improved statistical performance over previous proposals. Coupled with this estimator is a confidence interval which also improves over previous proposals. We then harness these to improve learning from contextual bandit data. Each of these is empirically evaluated to show good performance against strong baselines in finite sample regimes.
Lessons from Real-World Reinforcement Learning in a Customer Support Bot
May 06, 2019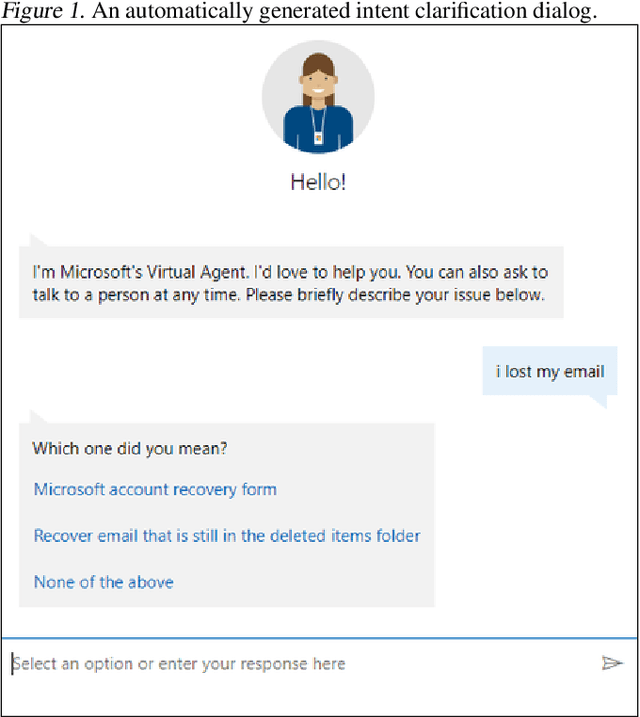
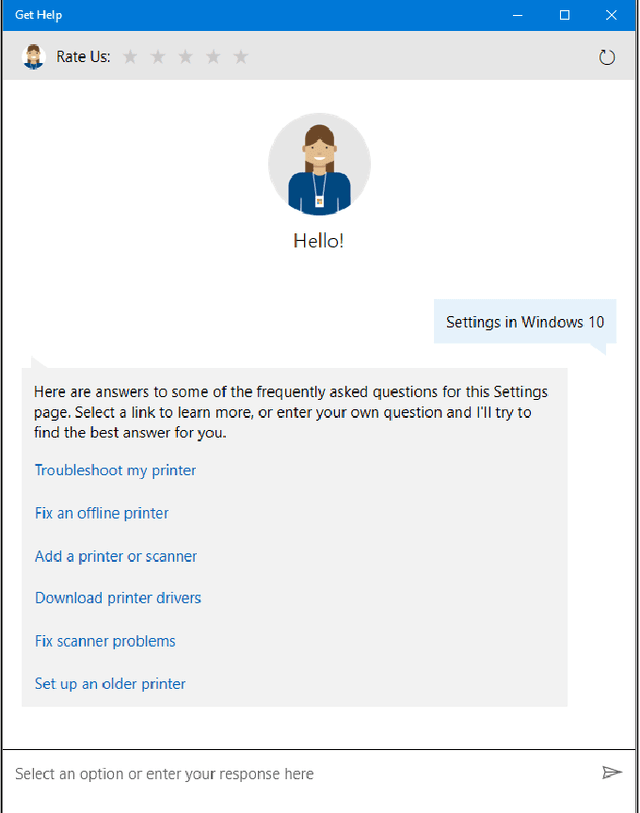
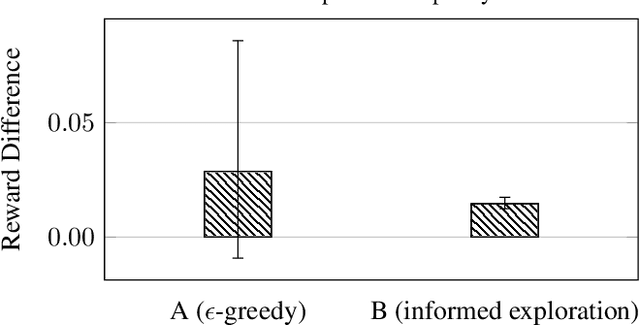
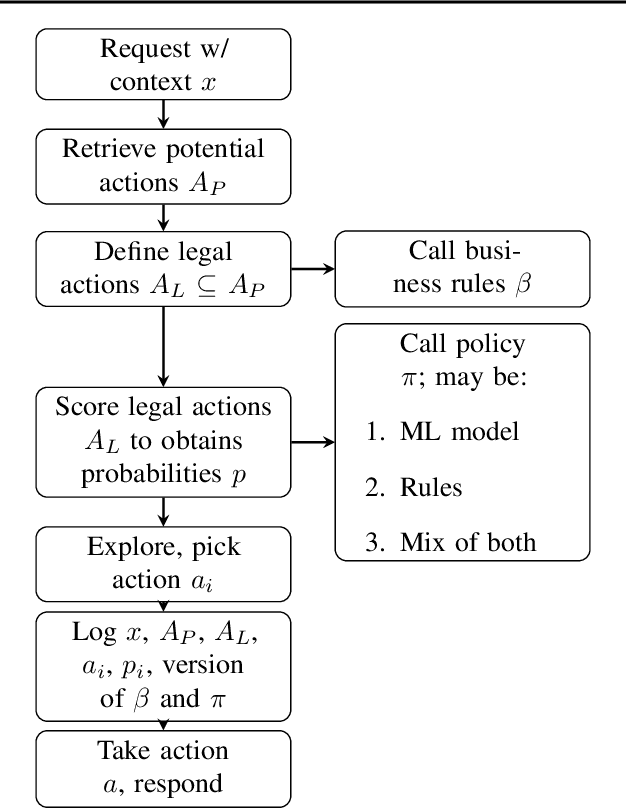
In this work, we describe practical lessons we have learned from successfully using reinforcement learning (RL) to improve key business metrics of the Microsoft Virtual Agent for customer support. While our current RL use cases focus on components that rely on techniques from natural language processing, ranking, and recommendation systems, we believe many of our findings are generally applicable. Through this article, we highlight certain issues that RL practitioners may encounter in similar types of applications as well as offer practical solutions to these challenges.