 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeizhu Chen
Deep Reinforcement Learning from Hierarchical Weak Preference Feedback
Sep 06, 2023
Reward design is a fundamental, yet challenging aspect of practical reinforcement learning (RL). For simple tasks, researchers typically handcraft the reward function, e.g., using a linear combination of several reward factors. However, such reward engineering is subject to approximation bias, incurs large tuning cost, and often cannot provide the granularity required for complex tasks. To avoid these difficulties, researchers have turned to reinforcement learning from human feedback (RLHF), which learns a reward function from human preferences between pairs of trajectory sequences. By leveraging preference-based reward modeling, RLHF learns complex rewards that are well aligned with human preferences, allowing RL to tackle increasingly difficult problems. Unfortunately, the applicability of RLHF is limited due to the high cost and difficulty of obtaining human preference data. In light of this cost, we investigate learning reward functions for complex tasks with less human effort; simply by ranking the importance of the reward factors. More specifically, we propose a new RL framework -- HERON, which compares trajectories using a hierarchical decision tree induced by the given ranking. These comparisons are used to train a preference-based reward model, which is then used for policy learning. We find that our framework can not only train high performing agents on a variety of difficult tasks, but also provide additional benefits such as improved sample efficiency and robustness. Our code is available at https://github.com/abukharin3/HERON.
LoSparse: Structured Compression of Large Language Models based on Low-Rank and Sparse Approximation
Jun 26, 2023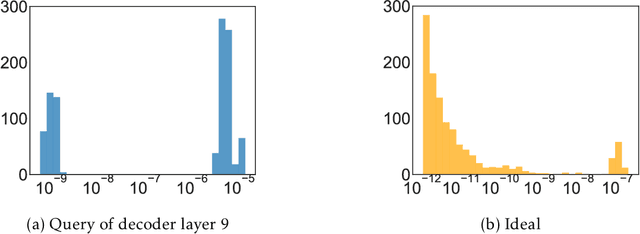
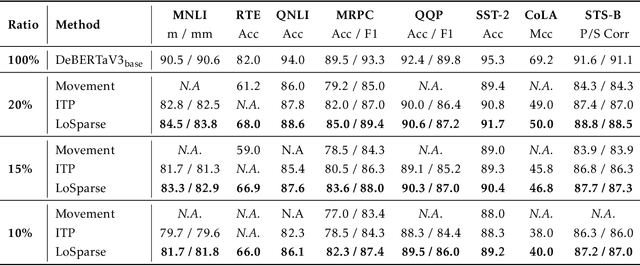
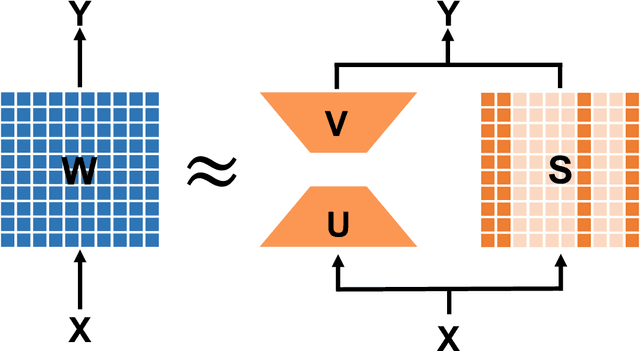
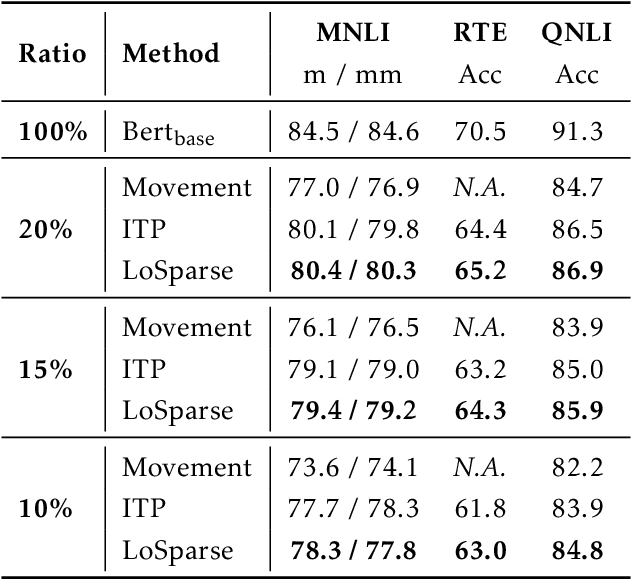
Transformer models have achieved remarkable results in various natural language tasks, but they are often prohibitively large, requiring massive memories and computational resources. To reduce the size and complexity of these models, we propose LoSparse (Low-Rank and Sparse approximation), a novel model compression technique that approximates a weight matrix by the sum of a low-rank matrix and a sparse matrix. Our method combines the advantages of both low-rank approximations and pruning, while avoiding their limitations. Low-rank approximation compresses the coherent and expressive parts in neurons, while pruning removes the incoherent and non-expressive parts in neurons. Pruning enhances the diversity of low-rank approximations, and low-rank approximation prevents pruning from losing too many expressive neurons. We evaluate our method on natural language understanding, question answering, and natural language generation tasks. We show that it significantly outperforms existing compression methods.
Enhancing Retrieval-Augmented Large Language Models with Iterative Retrieval-Generation Synergy
May 24, 2023
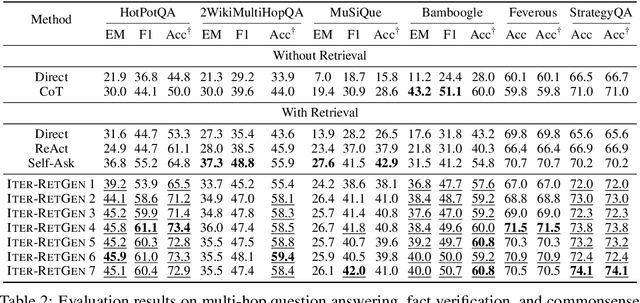


Large language models are powerful text processors and reasoners, but are still subject to limitations including outdated knowledge and hallucinations, which necessitates connecting them to the world. Retrieval-augmented large language models have raised extensive attention for grounding model generation on external knowledge. However, retrievers struggle to capture relevance, especially for queries with complex information needs. Recent work has proposed to improve relevance modeling by having large language models actively involved in retrieval, i.e., to improve retrieval with generation. In this paper, we show that strong performance can be achieved by a method we call Iter-RetGen, which synergizes retrieval and generation in an iterative manner. A model output shows what might be needed to finish a task, and thus provides an informative context for retrieving more relevant knowledge which in turn helps generate a better output in the next iteration. Compared with recent work which interleaves retrieval with generation when producing an output, Iter-RetGen processes all retrieved knowledge as a whole and largely preserves the flexibility in generation without structural constraints. We evaluate Iter-RetGen on multi-hop question answering, fact verification, and commonsense reasoning, and show that it can flexibly leverage parametric knowledge and non-parametric knowledge, and is superior to or competitive with state-of-the-art retrieval-augmented baselines while causing fewer overheads of retrieval and generation. We can further improve performance via generation-augmented retrieval adaptation.
GRILL: Grounded Vision-language Pre-training via Aligning Text and Image Regions
May 24, 2023
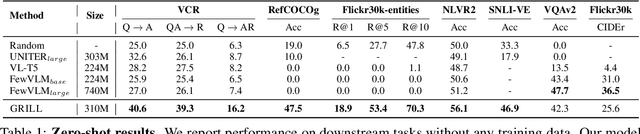
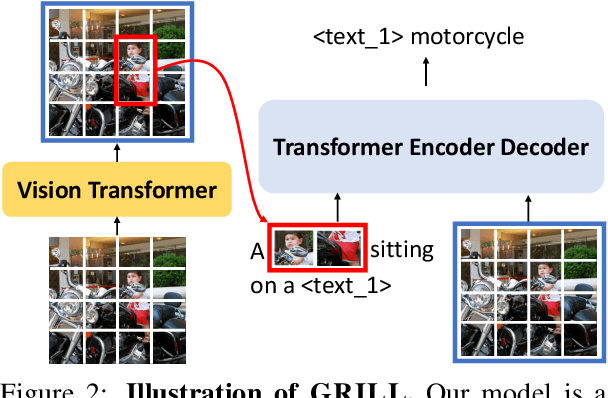

Generalization to unseen tasks is an important ability for few-shot learners to achieve better zero-/few-shot performance on diverse tasks. However, such generalization to vision-language tasks including grounding and generation tasks has been under-explored; existing few-shot VL models struggle to handle tasks that involve object grounding and multiple images such as visual commonsense reasoning or NLVR2. In this paper, we introduce GRILL, GRounded vIsion Language aLigning, a novel VL model that can be generalized to diverse tasks including visual question answering, captioning, and grounding tasks with no or very few training instances. Specifically, GRILL learns object grounding and localization by exploiting object-text alignments, which enables it to transfer to grounding tasks in a zero-/few-shot fashion. We evaluate our model on various zero-/few-shot VL tasks and show that it consistently surpasses the state-of-the-art few-shot methods.
Skill-Based Few-Shot Selection for In-Context Learning
May 23, 2023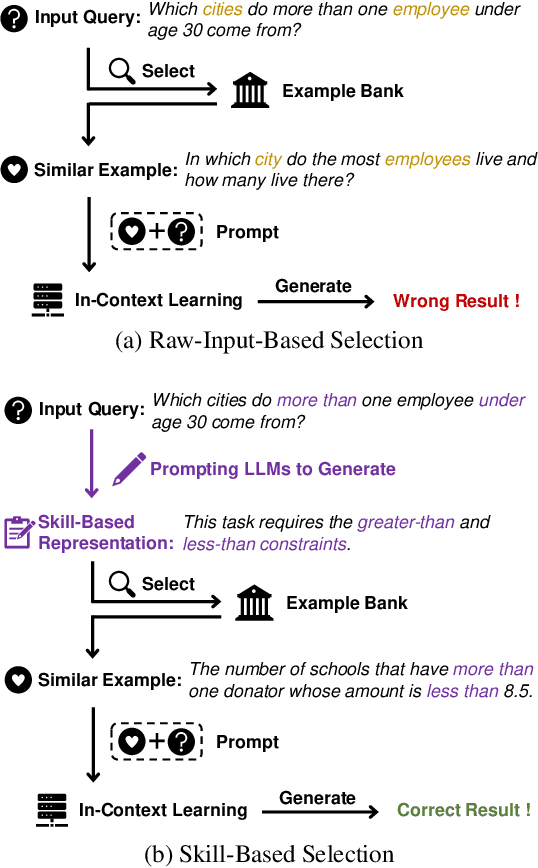

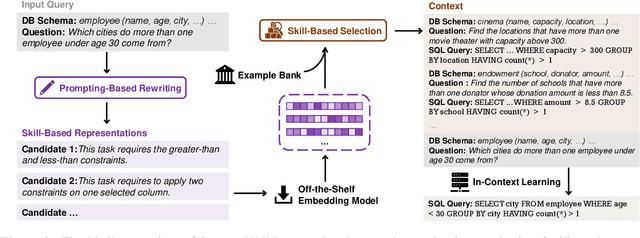
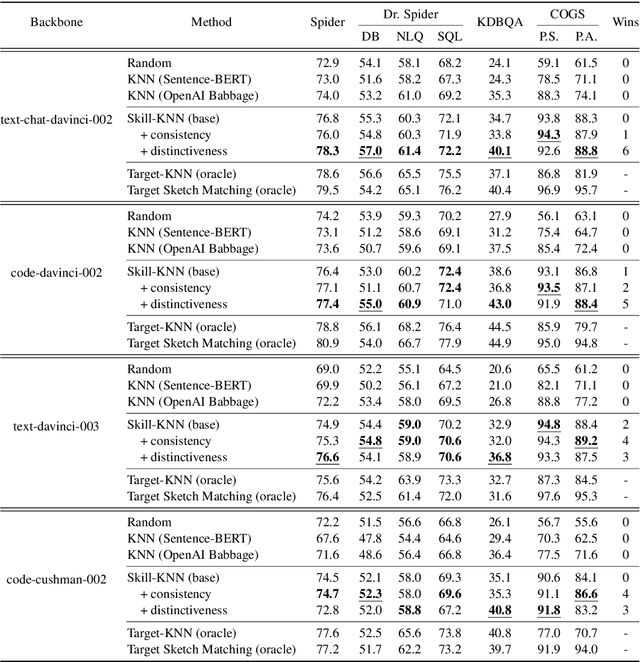
In-Context learning is the paradigm that adapts large language models to downstream tasks by providing a few examples. Few-shot selection -- selecting appropriate examples for each test instance separately -- is important for in-context learning. In this paper, we propose Skill-KNN, a skill-based few-shot selection method for in-context learning. The key advantages of Skill-KNN include: (1) it addresses the problem that existing methods based on pre-trained embeddings can be easily biased by surface natural language features that are not important for the target task; (2) it does not require training or fine-tuning of any models, making it suitable for frequently expanding or changing example banks. The key insight is to optimize the inputs fed into the embedding model, rather than tuning the model itself. Technically, Skill-KNN generates the skill-based representations for each test case and candidate example by utilizing a pre-processing few-shot prompting, thus eliminating unimportant surface features. Experimental results across four cross-domain semantic parsing tasks and four backbone models show that Skill-KNN significantly outperforms existing methods.
CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing
May 19, 2023

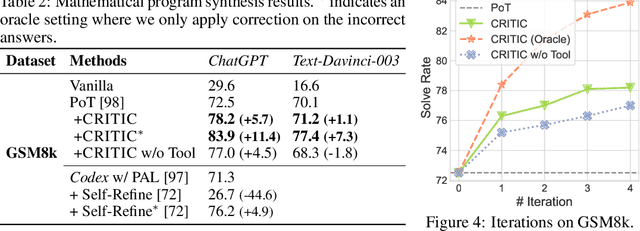
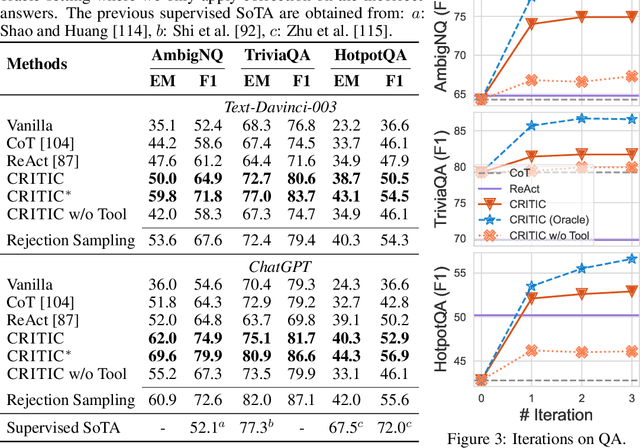
Recent developments in large language models (LLMs) have been impressive. However, these models sometimes show inconsistencies and problematic behavior, such as hallucinating facts, generating flawed code, or creating offensive and toxic content. Unlike these models, humans typically utilize external tools to cross-check and refine their initial content, like using a search engine for fact-checking, or a code interpreter for debugging. Inspired by this observation, we introduce a framework called CRITIC that allows LLMs, which are essentially "black boxes" to validate and progressively amend their own outputs in a manner similar to human interaction with tools. More specifically, starting with an initial output, CRITIC interacts with appropriate tools to evaluate certain aspects of the text, and then revises the output based on the feedback obtained during this validation process. Comprehensive evaluations involving free-form question answering, mathematical program synthesis, and toxicity reduction demonstrate that CRITIC consistently enhances the performance of LLMs. Meanwhile, our research highlights the crucial importance of external feedback in promoting the ongoing self-improvement of LLMs.
AR-Diffusion: Auto-Regressive Diffusion Model for Text Generation
May 19, 2023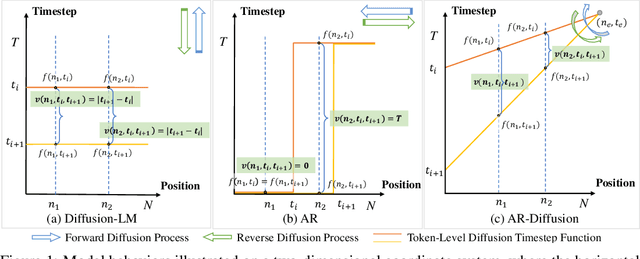
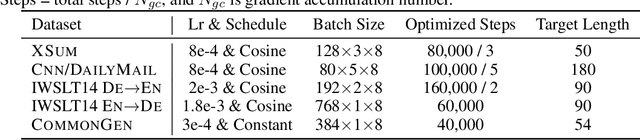
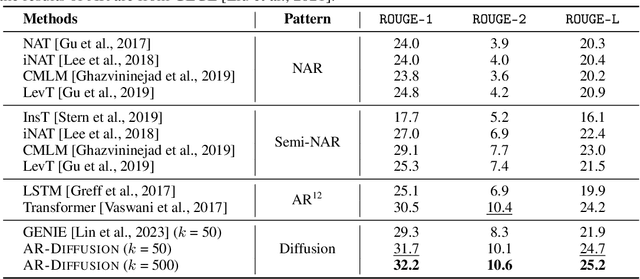
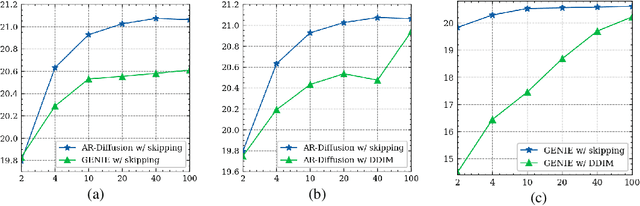
Diffusion models have gained significant attention in the realm of image generation due to their exceptional performance. Their success has been recently expanded to text generation via generating all tokens within a sequence concurrently. However, natural language exhibits a far more pronounced sequential dependency in comparison to images, and the majority of existing language models are trained with a left-to-right auto-regressive approach. To account for the inherent sequential characteristic of natural language, we introduce Auto-Regressive Diffusion (AR-Diffusion). AR-Diffusion ensures that the generation of tokens on the right depends on the generated ones on the left, a mechanism achieved through employing a dynamic number of denoising steps that vary based on token position. This results in tokens on the left undergoing fewer denoising steps than those on the right, thereby enabling them to generate earlier and subsequently influence the generation of tokens on the right. In a series of experiments on various text generation tasks, including text summarization, machine translation, and common sense generation, AR-Diffusion clearly demonstrated its superiority over existing diffusion language models and that it can be $100\times\sim600\times$ faster when achieving comparable results. Our code is available at https://github.com/microsoft/ProphetNet/tree/master/AR-diffusion.
Code Execution with Pre-trained Language Models
May 08, 2023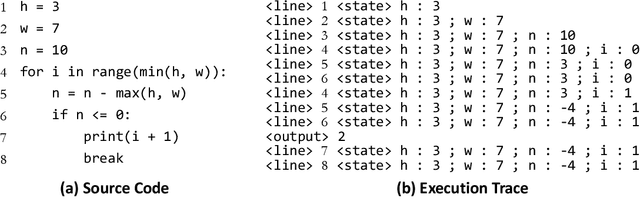
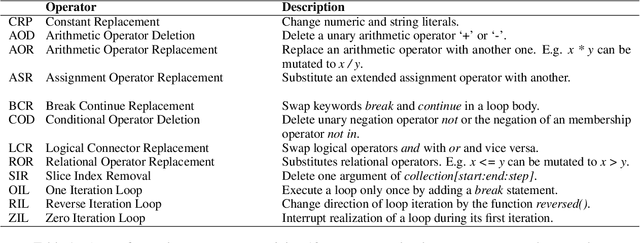

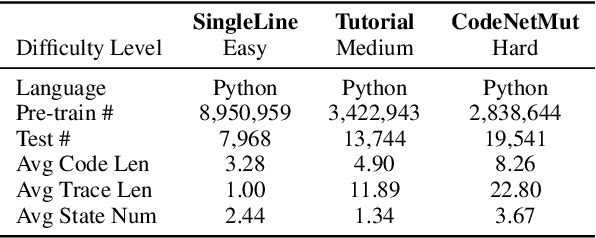
Code execution is a fundamental aspect of programming language semantics that reflects the exact behavior of the code. However, most pre-trained models for code intelligence ignore the execution trace and only rely on source code and syntactic structures. In this paper, we investigate how well pre-trained models can understand and perform code execution. We develop a mutation-based data augmentation technique to create a large-scale and realistic Python dataset and task for code execution, which challenges existing models such as Codex. We then present CodeExecutor, a Transformer model that leverages code execution pre-training and curriculum learning to enhance its semantic comprehension. We evaluate CodeExecutor on code execution and show its promising performance and limitations. We also demonstrate its potential benefits for code intelligence tasks such as zero-shot code-to-code search and text-to-code generation. Our analysis provides insights into the learning and generalization abilities of pre-trained models for code execution.
In-Context Learning Unlocked for Diffusion Models
May 01, 2023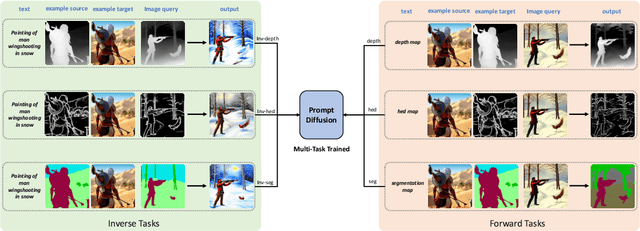
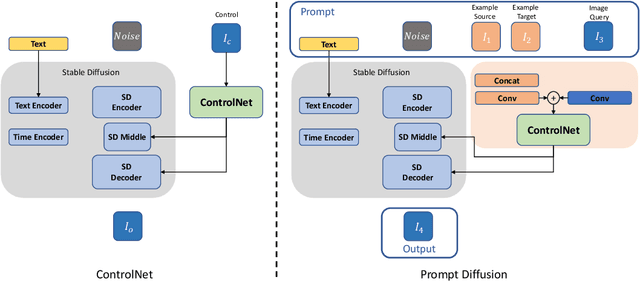


We present Prompt Diffusion, a framework for enabling in-context learning in diffusion-based generative models. Given a pair of task-specific example images, such as depth from/to image and scribble from/to image, and a text guidance, our model automatically understands the underlying task and performs the same task on a new query image following the text guidance. To achieve this, we propose a vision-language prompt that can model a wide range of vision-language tasks and a diffusion model that takes it as input. The diffusion model is trained jointly over six different tasks using these prompts. The resulting Prompt Diffusion model is the first diffusion-based vision-language foundation model capable of in-context learning. It demonstrates high-quality in-context generation on the trained tasks and generalizes effectively to new, unseen vision tasks with their respective prompts. Our model also shows compelling text-guided image editing results. Our framework, with code publicly available at https://github.com/Zhendong-Wang/Prompt-Diffusion, aims to facilitate research into in-context learning for computer vision.