 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIDeR: Semantic Identity Decoupling for Unrestricted Face Privacy
Feb 04, 2026With the deep integration of facial recognition into online banking, identity verification, and other networked services, achieving effective decoupling of identity information from visual representations during image storage and transmission has become a critical challenge for privacy protection. To address this issue, we propose SIDeR, a Semantic decoupling-driven framework for unrestricted face privacy protection. SIDeR decomposes a facial image into a machine-recognizable identity feature vector and a visually perceptible semantic appearance component. By leveraging semantic-guided recomposition in the latent space of a diffusion model, it generates visually anonymous adversarial faces while maintaining machine-level identity consistency. The framework incorporates momentum-driven unrestricted perturbation optimization and a semantic-visual balancing factor to synthesize multiple visually diverse, highly natural adversarial samples. Furthermore, for authorized access, the protected image can be restored to its original form when the correct password is provided. Extensive experiments on the CelebA-HQ and FFHQ datasets demonstrate that SIDeR achieves a 99% attack success rate in black-box scenarios and outperforms baseline methods by 41.28% in PSNR-based restoration quality.
Enhancing Conversational Agents via Task-Oriented Adversarial Memory Adaptation
Jan 29, 2026Conversational agents struggle to handle long conversations due to context window limitations. Therefore, memory systems are developed to leverage essential historical information. Existing memory systems typically follow a pipeline of offline memory construction and update, and online retrieval. Despite the flexible online phase, the offline phase remains fixed and task-independent. In this phase, memory construction operates under a predefined workflow and fails to emphasize task relevant information. Meanwhile, memory updates are guided by generic metrics rather than task specific supervision. This leads to a misalignment between offline memory preparation and task requirements, which undermines downstream task performance. To this end, we propose an Adversarial Memory Adaptation mechanism (AMA) that aligns memory construction and update with task objectives by simulating task execution. Specifically, first, a challenger agent generates question answer pairs based on the original dialogues. The constructed memory is then used to answer these questions, simulating downstream inference. Subsequently, an evaluator agent assesses the responses and performs error analysis. Finally, an adapter agent analyzes the error cases and performs dual level updates on both the construction strategy and the content. Through this process, the memory system receives task aware supervision signals in advance during the offline phase, enhancing its adaptability to downstream tasks. AMA can be integrated into various existing memory systems, and extensive experiments on long dialogue benchmark LoCoMo demonstrate its effectiveness.
Trajectory Design for UAV-Assisted Logistics Collection in Low-Altitude Economy
Nov 10, 2025Low-altitude economy (LAE) is rapidly emerging as a key driver of innovation, encompassing economic activities taking place in airspace below 500 meters. Unmanned aerial vehicles (UAVs) provide valuable tools for logistics collection within LAE systems, offering the ability to navigate through complex environments, avoid obstacles, and improve operational efficiency. However, logistics collection tasks involve UAVs flying through complex three-dimensional (3D) environments while avoiding obstacles, where traditional UAV trajectory design methods,typically developed under free-space conditions without explicitly accounting for obstacles, are not applicable. This paper presents, we propose a novel algorithm that combines the Lin-Kernighan-Helsgaun (LKH) and Deep Deterministic Policy Gradient (DDPG) methods to minimize the total collection time. Specifically, the LKH algorithm determines the optimal order of item collection, while the DDPG algorithm designs the flight trajectory between collection points. Simulations demonstrate that the proposed LKH-DDPG algorithm significantly reduces collection time by approximately 49 percent compared to baseline approaches, thereby highlighting its effectiveness in optimizing UAV trajectories and enhancing operational efficiency for logistics collection tasks in the LAE paradigm.
Learning Performance Optimization for Edge AI System with Time and Energy Constraints
Nov 10, 2025Edge AI, which brings artificial intelligence to the edge of the network for real-time processing and decision-making, has emerged as a transformative technology across various applications. However, the deployment of Edge AI systems faces significant challenges due to high energy consumption and extended operation time. In this paper, we consider an Edge AI system which integrates the data acquisition, computation and communication processes, and focus on improving learning performance of this system. We model the time and energy consumption of different processes and perform a rigorous convergence analysis to quantify the impact of key system parameters, such as the amount of collected data and the number of training rounds, on the learning performance. Based on this analysis, we formulate a system-wide optimization problem that seeks to maximize learning performance under given time and energy constraints. We explore both homogeneous and heterogeneous device scenarios, developing low-complexity algorithms based on one-dimensional search and alternating optimization to jointly optimize data collection time and training rounds. Simulation results validate the accuracy of our convergence analysis and demonstrate the effectiveness of the proposed algorithms, providing valuable insights into designing energy-efficient Edge AI systems under real-world conditions.
Hierarchical Federated Foundation Models over Wireless Networks for Multi-Modal Multi-Task Intelligence: Integration of Edge Learning with D2D/P2P-Enabled Fog Learning Architectures
Sep 03, 2025


The rise of foundation models (FMs) has reshaped the landscape of machine learning. As these models continued to grow, leveraging geo-distributed data from wireless devices has become increasingly critical, giving rise to federated foundation models (FFMs). More recently, FMs have evolved into multi-modal multi-task (M3T) FMs (e.g., GPT-4) capable of processing diverse modalities across multiple tasks, which motivates a new underexplored paradigm: M3T FFMs. In this paper, we unveil an unexplored variation of M3T FFMs by proposing hierarchical federated foundation models (HF-FMs), which in turn expose two overlooked heterogeneity dimensions to fog/edge networks that have a direct impact on these emerging models: (i) heterogeneity in collected modalities and (ii) heterogeneity in executed tasks across fog/edge nodes. HF-FMs strategically align the modular structure of M3T FMs, comprising modality encoders, prompts, mixture-of-experts (MoEs), adapters, and task heads, with the hierarchical nature of fog/edge infrastructures. Moreover, HF-FMs enable the optional usage of device-to-device (D2D) communications, enabling horizontal module relaying and localized cooperative training among nodes when feasible. Through delving into the architectural design of HF-FMs, we highlight their unique capabilities along with a series of tailored future research directions. Finally, to demonstrate their potential, we prototype HF-FMs in a wireless network setting and release the open-source code for the development of HF-FMs with the goal of fostering exploration in this untapped field (GitHub: https://github.com/payamsiabd/M3T-FFM).
Agentic Graph Neural Networks for Wireless Communications and Networking Towards Edge General Intelligence: A Survey
Aug 12, 2025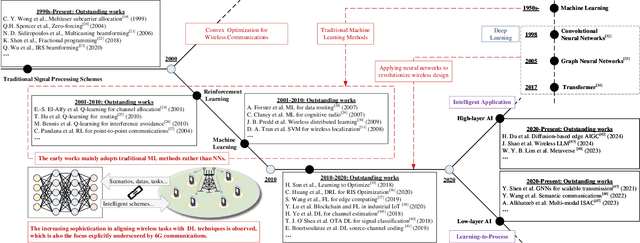
The rapid advancement of communication technologies has driven the evolution of communication networks towards both high-dimensional resource utilization and multifunctional integration. This evolving complexity poses significant challenges in designing communication networks to satisfy the growing quality-of-service and time sensitivity of mobile applications in dynamic environments. Graph neural networks (GNNs) have emerged as fundamental deep learning (DL) models for complex communication networks. GNNs not only augment the extraction of features over network topologies but also enhance scalability and facilitate distributed computation. However, most existing GNNs follow a traditional passive learning framework, which may fail to meet the needs of increasingly diverse wireless systems. This survey proposes the employment of agentic artificial intelligence (AI) to organize and integrate GNNs, enabling scenario- and task-aware implementation towards edge general intelligence. To comprehend the full capability of GNNs, we holistically review recent applications of GNNs in wireless communications and networking. Specifically, we focus on the alignment between graph representations and network topologies, and between neural architectures and wireless tasks. We first provide an overview of GNNs based on prominent neural architectures, followed by the concept of agentic GNNs. Then, we summarize and compare GNN applications for conventional systems and emerging technologies, including physical, MAC, and network layer designs, integrated sensing and communication (ISAC), reconfigurable intelligent surface (RIS) and cell-free network architecture. We further propose a large language model (LLM) framework as an intelligent question-answering agent, leveraging this survey as a local knowledge base to enable GNN-related responses tailored to wireless communication research.
A Novel Indicator for Quantifying and Minimizing Information Utility Loss of Robot Teams
Jun 17, 2025The timely exchange of information among robots within a team is vital, but it can be constrained by limited wireless capacity. The inability to deliver information promptly can result in estimation errors that impact collaborative efforts among robots. In this paper, we propose a new metric termed Loss of Information Utility (LoIU) to quantify the freshness and utility of information critical for cooperation. The metric enables robots to prioritize information transmissions within bandwidth constraints. We also propose the estimation of LoIU using belief distributions and accordingly optimize both transmission schedule and resource allocation strategy for device-to-device transmissions to minimize the time-average LoIU within a robot team. A semi-decentralized Multi-Agent Deep Deterministic Policy Gradient framework is developed, where each robot functions as an actor responsible for scheduling transmissions among its collaborators while a central critic periodically evaluates and refines the actors in response to mobility and interference. Simulations validate the effectiveness of our approach, demonstrating an enhancement of information freshness and utility by 98%, compared to alternative methods.
Convergence-Privacy-Fairness Trade-Off in Personalized Federated Learning
Jun 17, 2025Personalized federated learning (PFL), e.g., the renowned Ditto, strikes a balance between personalization and generalization by conducting federated learning (FL) to guide personalized learning (PL). While FL is unaffected by personalized model training, in Ditto, PL depends on the outcome of the FL. However, the clients' concern about their privacy and consequent perturbation of their local models can affect the convergence and (performance) fairness of PL. This paper presents PFL, called DP-Ditto, which is a non-trivial extension of Ditto under the protection of differential privacy (DP), and analyzes the trade-off among its privacy guarantee, model convergence, and performance distribution fairness. We also analyze the convergence upper bound of the personalized models under DP-Ditto and derive the optimal number of global aggregations given a privacy budget. Further, we analyze the performance fairness of the personalized models, and reveal the feasibility of optimizing DP-Ditto jointly for convergence and fairness. Experiments validate our analysis and demonstrate that DP-Ditto can surpass the DP-perturbed versions of the state-of-the-art PFL models, such as FedAMP, pFedMe, APPLE, and FedALA, by over 32.71% in fairness and 9.66% in accuracy.
Free Privacy Protection for Wireless Federated Learning: Enjoy It or Suffer from It?
Jun 15, 2025Inherent communication noises have the potential to preserve privacy for wireless federated learning (WFL) but have been overlooked in digital communication systems predominantly using floating-point number standards, e.g., IEEE 754, for data storage and transmission. This is due to the potentially catastrophic consequences of bit errors in floating-point numbers, e.g., on the sign or exponent bits. This paper presents a novel channel-native bit-flipping differential privacy (DP) mechanism tailored for WFL, where transmit bits are randomly flipped and communication noises are leveraged, to collectively preserve the privacy of WFL in digital communication systems. The key idea is to interpret the bit perturbation at the transmitter and bit errors caused by communication noises as a bit-flipping DP process. This is achieved by designing a new floating-point-to-fixed-point conversion method that only transmits the bits in the fraction part of model parameters, hence eliminating the need for transmitting the sign and exponent bits and preventing the catastrophic consequence of bit errors. We analyze a new metric to measure the bit-level distance of the model parameters and prove that the proposed mechanism satisfies (\lambda,\epsilon)-R\'enyi DP and does not violate the WFL convergence. Experiments validate privacy and convergence analysis of the proposed mechanism and demonstrate its superiority to the state-of-the-art Gaussian mechanisms that are channel-agnostic and add Gaussian noise for privacy protection.
Unsourced Adversarial CAPTCHA: A Bi-Phase Adversarial CAPTCHA Framework
Jun 12, 2025



With the rapid advancements in deep learning, traditional CAPTCHA schemes are increasingly vulnerable to automated attacks powered by deep neural networks (DNNs). Existing adversarial attack methods often rely on original image characteristics, resulting in distortions that hinder human interpretation and limit applicability in scenarios lacking initial input images. To address these challenges, we propose the Unsourced Adversarial CAPTCHA (UAC), a novel framework generating high-fidelity adversarial examples guided by attacker-specified text prompts. Leveraging a Large Language Model (LLM), UAC enhances CAPTCHA diversity and supports both targeted and untargeted attacks. For targeted attacks, the EDICT method optimizes dual latent variables in a diffusion model for superior image quality. In untargeted attacks, especially for black-box scenarios, we introduce bi-path unsourced adversarial CAPTCHA (BP-UAC), a two-step optimization strategy employing multimodal gradients and bi-path optimization for efficient misclassification. Experiments show BP-UAC achieves high attack success rates across diverse systems, generating natural CAPTCHAs indistinguishable to humans and DNNs.