 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Certified Semantic Commitment for Byzantine-Resilient LLM-Agent Collaboration
Jun 05, 2026Byzantine collaboration among large-language-model agents requires a finality-control primitive: given delivered stochastic, structured natural-language proposals, the protocol must decide whether the round supports a commit, what kind of commit, or a typed safe abort. Naive aggregation hides this choice behind a single verdict; classical Byzantine fault tolerance hides it behind byte-identity that LLM proposals do not satisfy. We introduce Hierarchical Certified Semantic Commitment (H-CSC), a BFT-inspired protocol that converts embedding-derived finality signals over verdict-conditioned proposal groups into one of three typed outcomes: a semantic_commit (a 2f+1 within-verdict semantic core backs the verdict, emitting a parameter-bound digest over the quantised aggregate), a verdict_commit (strong verdict margin but dispersed semantic rationale, emitting a verdict-level certificate without claiming a semantic aggregate), or an explicit abort with a typed reason. The contribution is typed finality, not raw commit accuracy. On a controlled semantic-poisoning diagnostic (BCS_v1, 120 episodes), H-CSC commits with low angular deviation on BFT-feasible buckets (0.31 to 2.04 degrees) and aborts 100% of beyond-BFT rounds (n<3f+1) as intended. On a real LLM-agent claim-verification benchmark (MVR-50, 50 tasks) under paired static and rushing Byzantine attacks, H-CSC commits 0.90/0.92 with honest-reference-invalid rates of 0.02/0.00, statistically matching a strong certificate-emitting verdict-only baseline. Unlike that baseline, H-CSC also emits an embedding-backed semantic_commit digest on 74%/72% of rounds, supplying typed provenance. A strict-semantic ablation commits only 0.54/0.48, showing the verdict-level fallback is necessary for coverage (+0.36/+0.44) at the same <=0.04 safety floor; a 100-task cross-model check across four LLMs preserves invalid_hmaj within 0.00 to 0.03.
Rethinking Wireless Communications through Formal Mathematical AI Reasoning
Apr 28, 2026Mathematical analysis has long underpinned wireless communication theory, yet the growing complexity of next-generation systems demands increasingly sophisticated reasoning from domain experts. Recent advances in AI mathematical reasoning, from formal theorem proving to large language model (LLM)-based derivation, offer a promising but largely unexplored path forward. Here we argue that wireless communications is a uniquely structured domain for formal AI reasoning, and propose a three-layer framework of verification, derivation, and discovery to rethink how wireless mathematical knowledge is established.
On Dual-Fed Pinching Antenna Systems with In-Waveguide Attenuation
Mar 05, 2026Pinching antenna systems (PAS) have recently emerged as a promising architecture for flexible and reconfigurable wireless communications. However, their performance is fundamentally constrained by in-waveguide attenuation, which is non-negligible in practical dielectric waveguides and can severely degrade the achievable data rate, particularly for long waveguides. To overcome this limitation, we propose a dual-fed PAS (DF-PAS), in which each waveguide is equipped with two feed points located at the two ends, enabling dynamic feed-point selection based on user locations. This design effectively shortens the in-waveguide propagation distance and mitigates attenuation-induced power loss without modifying the waveguide structure or the PA actuation mechanism. We investigate the DF-PAS in both single- and multi-waveguide scenarios. For the single-waveguide case, we derive closed-form high-SNR approximations of the ergodic rate and obtain closed-form solutions for the optimal PA position and feed-point selection under time-division multiple access (TDMA). We then extend DF-PAS to a multi-waveguide scenario, where we first derive closed-form high-SNR approximations of the ergodic rate and then formulate a joint optimization problem over feed-point selection, PA placement, and beamforming under general orthogonal multiple access (OMA). To solve this problem efficiently, we develop a two-phase optimization framework that integrates greedy feed-point switching, gradient-based PA placement, and WMMSE-based beamforming. Simulation results demonstrate that the proposed DF-PAS consistently outperforms conventional single-fed PAS (SF-PAS) across various network configurations, validating its effectiveness as a practical and scalable solution for mitigating in-waveguide attenuation in PAS-enabled wireless networks.
Pinching Antennas in Blockage-Aware Environments: Modeling, Design, and Optimization
Jan 03, 2026Pinching-antenna (PA) systems have recently emerged as a promising member of the flexible-antenna family due to their ability to dynamically establish line-of-sight (LoS) links. While most existing studies assume ideal environments without obstacles, practical indoor deployments are often obstacle-rich, where LoS blockage significantly degrades performance. This paper investigates pinching-antenna systems in blockage-aware environments by developing a deterministic model for cylinder-shaped obstacles that precisely characterizes LoS conditions without relying on stochastic approximations. Based on this model, a special case is first studied where each PA serves a single user and can only be deployed at discrete positions along the waveguide. In this case, the waveguide-user assignment is obtained via the Hungarian algorithm, and PA positions are refined using a surrogate-assisted block-coordinate search. Then, a general case is considered where each PA serves all users and can be continuously placed along the waveguide. In this case, beamforming and PA positions are jointly optimized by a weighted minimum mean square error integrated deep deterministic policy gradient (WMMSE-DDPG) approach to address non-smooth LoS transitions. Simulation results demonstrate that the proposed algorithms significantly improve system throughput and LoS connectivity compared with benchmark methods. Moreover, the results reveal that pinching-antenna systems can effectively leverage obstacles to suppress co-channel interference, converting potential blockages into performance gains.
Learning-Enabled Elastic Network Topology for Distributed ISAC Service Provisioning
Dec 23, 2025



Conventional mobile networks, including both localized cell-centric and cooperative cell-free networks (CCN/CFN), are built upon rigid network topologies. However, neither architecture is adequate to flexibly support distributed integrated sensing and communication (ISAC) services, due to the increasing difficulty of aligning spatiotemporally distributed heterogeneous service demands with available radio resources. In this paper, we propose an elastic network topology (ENT) for distributed ISAC service provisioning, where multiple co-existing localized CCNs can be dynamically aggregated into CFNs with expanded boundaries for federated network operation. This topology elastically orchestrates localized CCN and federated CFN boundaries to balance signaling overhead and distributed resource utilization, thereby enabling efficient ISAC service provisioning. A two-phase operation protocol is then developed. In Phase I, each CCN autonomously classifies ISAC services as either local or federated and partitions its resources into dedicated and shared segments. In Phase II, each CCN employs its dedicated resources for local ISAC services, while the aggregated CFN consolidates shared resources from its constituent CCNs to cooperatively deliver federated services. Furthermore, we design a utility-to-signaling ratio (USR) to quantify the tradeoff between sensing/communication utility and signaling overhead. Consequently, a USR maximization problem is formulated by jointly optimizing the network topology (i.e., service classification and CCN aggregation) and the allocation of dedicated and shared resources. However, this problem is challenging due to its distributed optimization nature and the absence of complete channel state information. To address this problem efficiently, we propose a multi-agent deep reinforcement learning (MADRL) framework with centralized training and decentralized execution.
Game-Theoretic Safe Multi-Agent Motion Planning with Reachability Analysis for Dynamic and Uncertain Environments (Extended Version)
Nov 15, 2025Ensuring safe, robust, and scalable motion planning for multi-agent systems in dynamic and uncertain environments is a persistent challenge, driven by complex inter-agent interactions, stochastic disturbances, and model uncertainties. To overcome these challenges, particularly the computational complexity of coupled decision-making and the need for proactive safety guarantees, we propose a Reachability-Enhanced Dynamic Potential Game (RE-DPG) framework, which integrates game-theoretic coordination into reachability analysis. This approach formulates multi-agent coordination as a dynamic potential game, where the Nash equilibrium (NE) defines optimal control strategies across agents. To enable scalability and decentralized execution, we develop a Neighborhood-Dominated iterative Best Response (ND-iBR) scheme, built upon an iterated $\varepsilon$-BR (i$\varepsilon$-BR) process that guarantees finite-step convergence to an $\varepsilon$-NE. This allows agents to compute strategies based on local interactions while ensuring theoretical convergence guarantees. Furthermore, to ensure safety under uncertainty, we integrate a Multi-Agent Forward Reachable Set (MA-FRS) mechanism into the cost function, explicitly modeling uncertainty propagation and enforcing collision avoidance constraints. Through both simulations and real-world experiments in 2D and 3D environments, we validate the effectiveness of RE-DPG across diverse operational scenarios.
Trust Semantics Distillation for Collaborator Selection via Memory-Augmented Agentic AI
Sep 09, 2025Accurate trustworthiness evaluation of potential collaborating devices is essential for the effective execution of complex computing tasks. This evaluation process involves collecting diverse trust-related data from potential collaborators, including historical performance and available resources, for collaborator selection. However, when each task owner independently assesses all collaborators' trustworthiness, frequent data exchange, complex reasoning, and dynamic situation changes can result in significant overhead and deteriorated trust evaluation. To overcome these challenges, we propose a task-specific trust semantics distillation (2TSD) model based on a large AI model (LAM)-driven teacher-student agent architecture. The teacher agent is deployed on a server with powerful computational capabilities and an augmented memory module dedicated to multidimensional trust-related data collection, task-specific trust semantics extraction, and task-collaborator matching analysis. Upon receiving task-specific requests from device-side student agents, the teacher agent transfers the trust semantics of potential collaborators to the student agents, enabling rapid and accurate collaborator selection. Experimental results demonstrate that the proposed 2TSD model can reduce collaborator evaluation time, decrease device resource consumption, and improve the accuracy of collaborator selection.
Agentic Graph Neural Networks for Wireless Communications and Networking Towards Edge General Intelligence: A Survey
Aug 12, 2025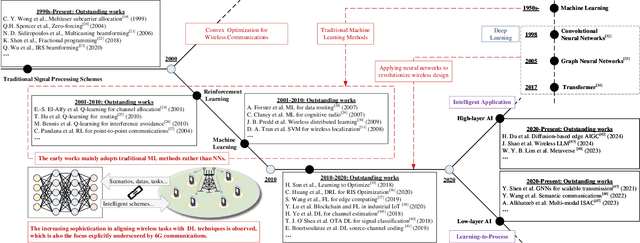
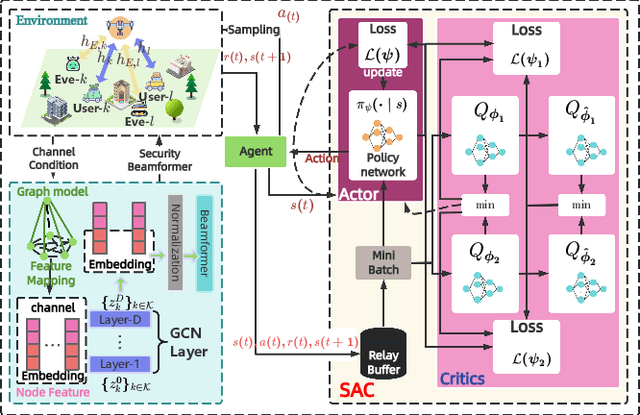
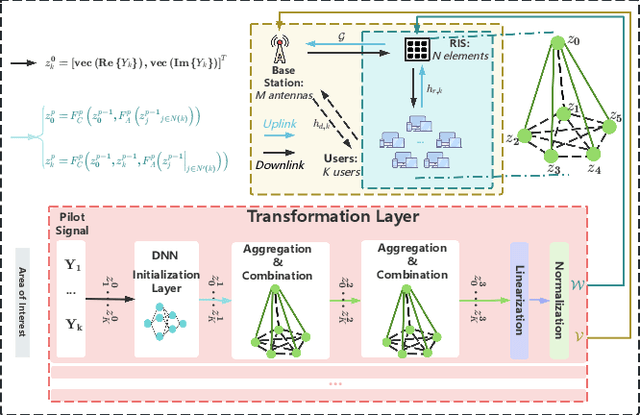
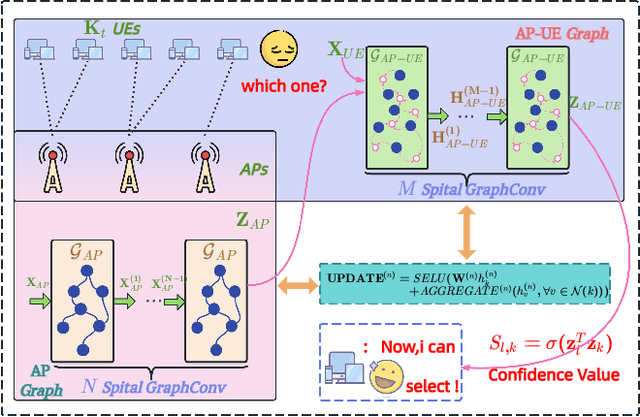
The rapid advancement of communication technologies has driven the evolution of communication networks towards both high-dimensional resource utilization and multifunctional integration. This evolving complexity poses significant challenges in designing communication networks to satisfy the growing quality-of-service and time sensitivity of mobile applications in dynamic environments. Graph neural networks (GNNs) have emerged as fundamental deep learning (DL) models for complex communication networks. GNNs not only augment the extraction of features over network topologies but also enhance scalability and facilitate distributed computation. However, most existing GNNs follow a traditional passive learning framework, which may fail to meet the needs of increasingly diverse wireless systems. This survey proposes the employment of agentic artificial intelligence (AI) to organize and integrate GNNs, enabling scenario- and task-aware implementation towards edge general intelligence. To comprehend the full capability of GNNs, we holistically review recent applications of GNNs in wireless communications and networking. Specifically, we focus on the alignment between graph representations and network topologies, and between neural architectures and wireless tasks. We first provide an overview of GNNs based on prominent neural architectures, followed by the concept of agentic GNNs. Then, we summarize and compare GNN applications for conventional systems and emerging technologies, including physical, MAC, and network layer designs, integrated sensing and communication (ISAC), reconfigurable intelligent surface (RIS) and cell-free network architecture. We further propose a large language model (LLM) framework as an intelligent question-answering agent, leveraging this survey as a local knowledge base to enable GNN-related responses tailored to wireless communication research.
Advancing the Control of Low-Altitude Wireless Networks: Architecture, Design Principles, and Future Directions
Aug 11, 2025



This article introduces a control-oriented low-altitude wireless network (LAWN) that integrates near-ground communications and remote estimation of the internal system state. This integration supports reliable networked control in dynamic aerial-ground environments. First, we introduce the network's modular architecture and key performance metrics. Then, we discuss core design trade-offs across the control, communication, and estimation layers. A case study illustrates closed-loop coordination under wireless constraints. Finally, we outline future directions for scalable, resilient LAWN deployments in real-time and resource-constrained scenarios.
Energy-Efficient Design for Downlink Pinching-Antenna Systems with QoS Guarantee
May 20, 2025



Pinching antennas have recently garnered significant attention due to their ability to dynamically reconfigure wireless propagation environments. Despite notable advancements in this area, the exploration of energy efficiency (EE) maximization in pinching-antenna systems remains relatively underdeveloped. In this paper, we address the EE maximization problem in a downlink time-division multiple access (TDMA)-based multi-user system employing one waveguide and multiple pinching antennas, where each user is subject to a minimum rate constraint to ensure quality-of-service. The formulated optimization problem jointly considers transmit power and time allocations as well as the positioning of pinching antennas, resulting in a non-convex problem. To tackle this challenge, we first obtain the optimal positions of the pinching antennas. Based on this, we establish a feasibility condition for the system. Subsequently, the joint power and time allocation problem is decomposed into two subproblems, which are solved iteratively until convergence. Specifically, the power allocation subproblem is addressed through an iterative approach, where a semi-analytical solution is obtained in each iteration. Likewise, a semi-analytical solution is derived for the time allocation subproblem. Numerical simulations demonstrate that the proposed pinching-antenna-based strategy significantly outperforms both conventional fixed-antenna systems and other benchmark pinching-antenna schemes in terms of EE.