 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGNN-encoder: Learning a Dual-encoder Architecture via Graph Neural Networks for Passage Retrieval
Apr 18, 2022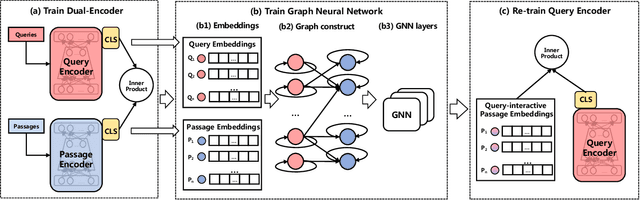

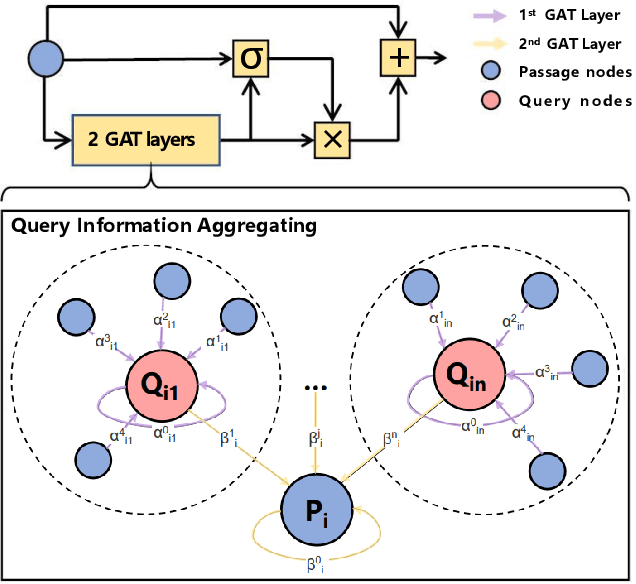
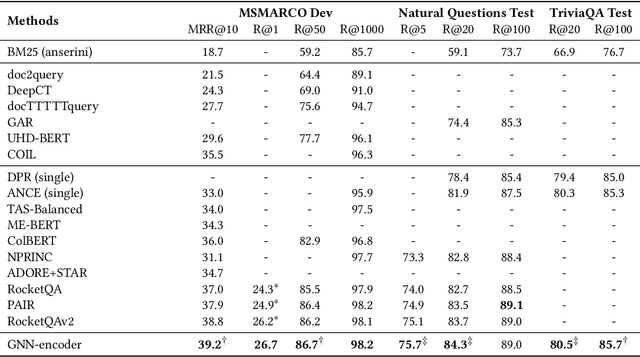
Recently, retrieval models based on dense representations are dominant in passage retrieval tasks, due to their outstanding ability in terms of capturing semantics of input text compared to the traditional sparse vector space models. A common practice of dense retrieval models is to exploit a dual-encoder architecture to represent a query and a passage independently. Though efficient, such a structure loses interaction between the query-passage pair, resulting in inferior accuracy. To enhance the performance of dense retrieval models without loss of efficiency, we propose a GNN-encoder model in which query (passage) information is fused into passage (query) representations via graph neural networks that are constructed by queries and their top retrieved passages. By this means, we maintain a dual-encoder structure, and retain some interaction information between query-passage pairs in their representations, which enables us to achieve both efficiency and efficacy in passage retrieval. Evaluation results indicate that our method significantly outperforms the existing models on MSMARCO, Natural Questions and TriviaQA datasets, and achieves the new state-of-the-art on these datasets.
Target-Relevant Knowledge Preservation for Multi-Source Domain Adaptive Object Detection
Apr 17, 2022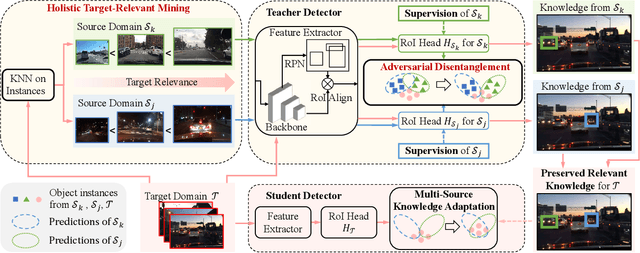
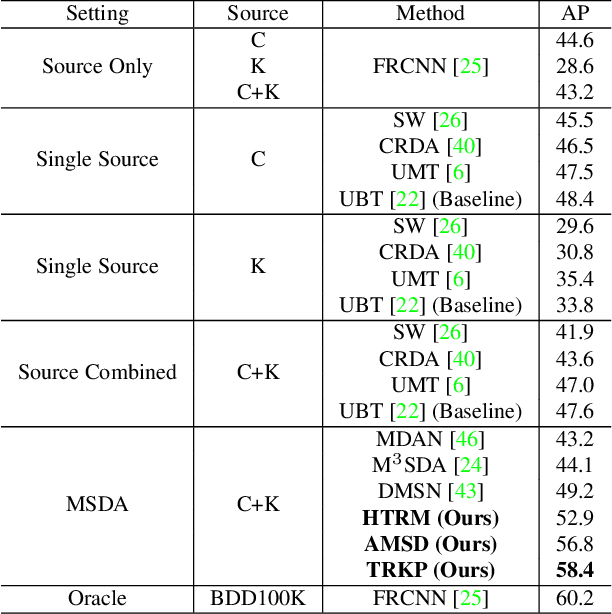
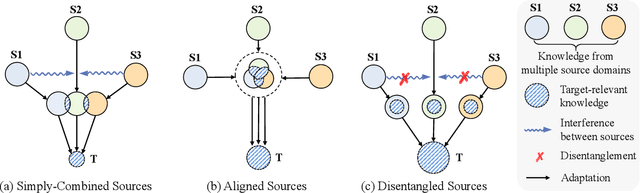
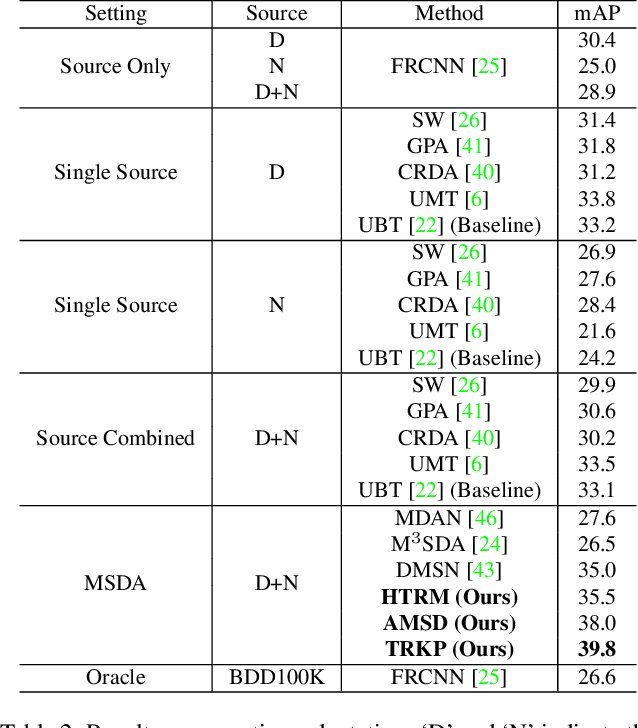
Domain adaptive object detection (DAOD) is a promising way to alleviate performance drop of detectors in new scenes. Albeit great effort made in single source domain adaptation, a more generalized task with multiple source domains remains not being well explored, due to knowledge degradation during their combination. To address this issue, we propose a novel approach, namely target-relevant knowledge preservation (TRKP), to unsupervised multi-source DAOD. Specifically, TRKP adopts the teacher-student framework, where the multi-head teacher network is built to extract knowledge from labeled source domains and guide the student network to learn detectors in unlabeled target domain. The teacher network is further equipped with an adversarial multi-source disentanglement (AMSD) module to preserve source domain-specific knowledge and simultaneously perform cross-domain alignment. Besides, a holistic target-relevant mining (HTRM) scheme is developed to re-weight the source images according to the source-target relevance. By this means, the teacher network is enforced to capture target-relevant knowledge, thus benefiting decreasing domain shift when mentoring object detection in the target domain. Extensive experiments are conducted on various widely used benchmarks with new state-of-the-art scores reported, highlighting the effectiveness.
Learning to Express in Knowledge-Grounded Conversation
Apr 12, 2022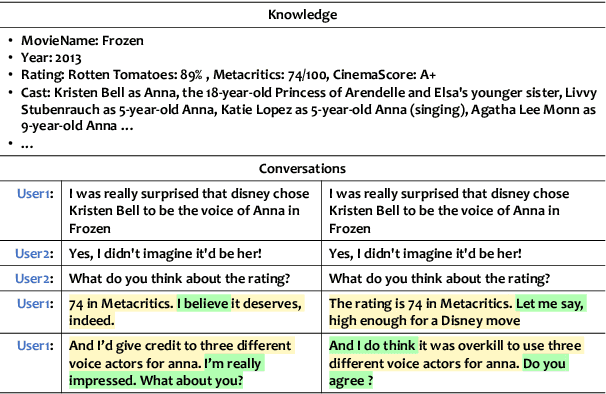
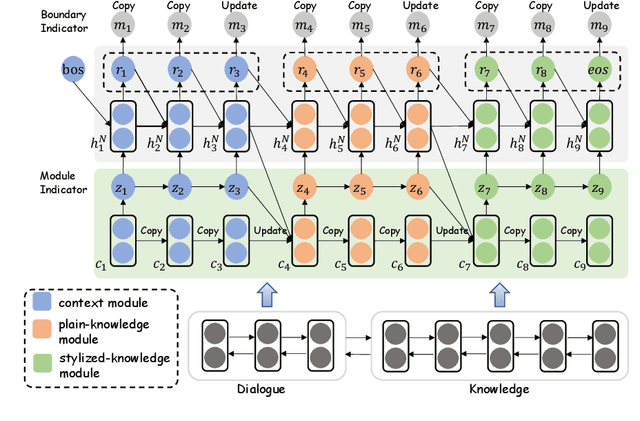
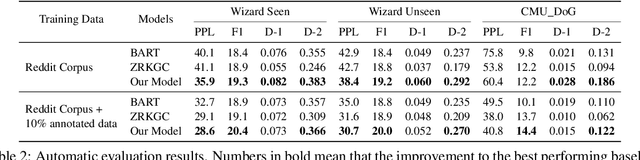
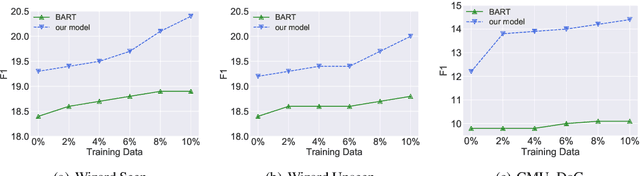
Grounding dialogue generation by extra knowledge has shown great potentials towards building a system capable of replying with knowledgeable and engaging responses. Existing studies focus on how to synthesize a response with proper knowledge, yet neglect that the same knowledge could be expressed differently by speakers even under the same context. In this work, we mainly consider two aspects of knowledge expression, namely the structure of the response and style of the content in each part. We therefore introduce two sequential latent variables to represent the structure and the content style respectively. We propose a segmentation-based generation model and optimize the model by a variational approach to discover the underlying pattern of knowledge expression in a response. Evaluation results on two benchmarks indicate that our model can learn the structure style defined by a few examples and generate responses in desired content style.
Data-Driven, Soft Alignment of Functional Data Using Shapes and Landmarks
Apr 10, 2022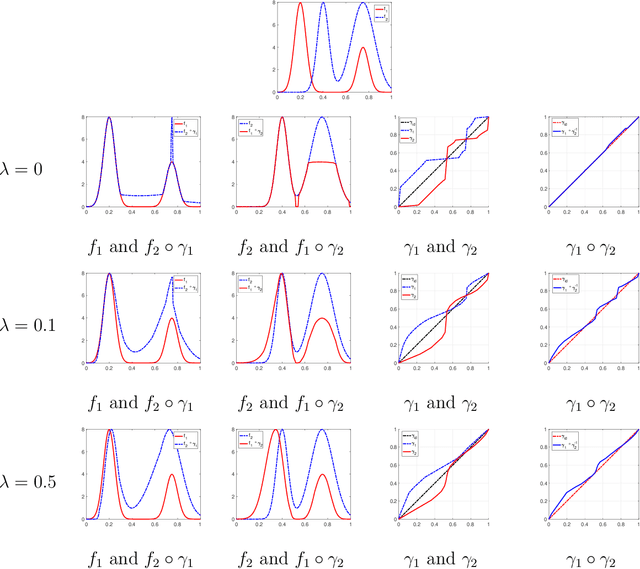
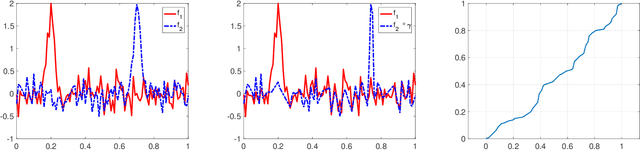
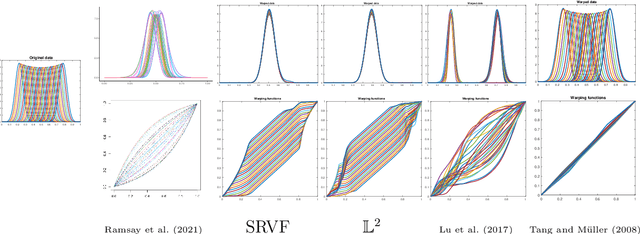
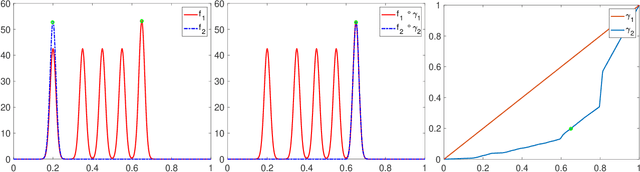
Alignment or registration of functions is a fundamental problem in statistical analysis of functions and shapes. While there are several approaches available, a more recent approach based on Fisher-Rao metric and square-root velocity functions (SRVFs) has been shown to have good performance. However, this SRVF method has two limitations: (1) it is susceptible to over alignment, i.e., alignment of noise as well as the signal, and (2) in case there is additional information in form of landmarks, the original formulation does not prescribe a way to incorporate that information. In this paper we propose an extension that allows for incorporation of landmark information to seek a compromise between matching curves and landmarks. This results in a soft landmark alignment that pushes landmarks closer, without requiring their exact overlays to finds a compromise between contributions from functions and landmarks. The proposed method is demonstrated to be superior in certain practical scenarios.
TANet: Thread-Aware Pretraining for Abstractive Conversational Summarization
Apr 09, 2022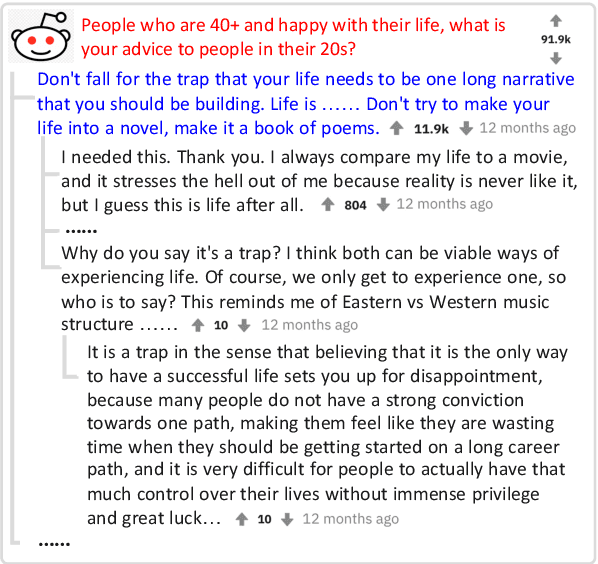
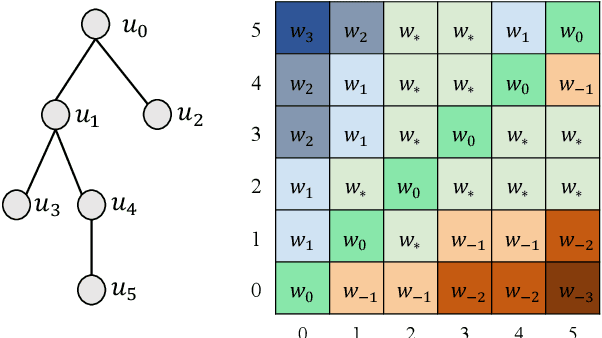
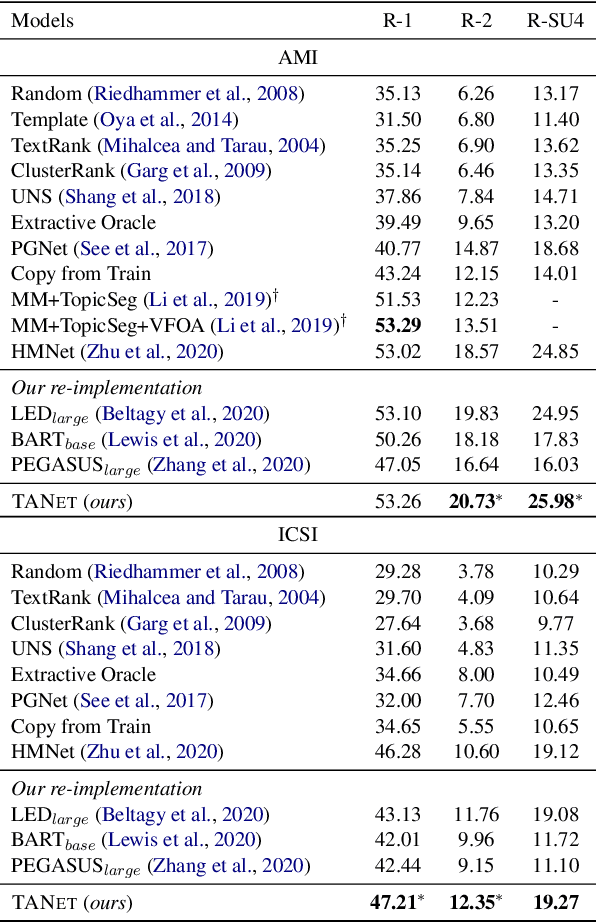
Although pre-trained language models (PLMs) have achieved great success and become a milestone in NLP, abstractive conversational summarization remains a challenging but less studied task. The difficulty lies in two aspects. One is the lack of large-scale conversational summary data. Another is that applying the existing pre-trained models to this task is tricky because of the structural dependence within the conversation and its informal expression, etc. In this work, we first build a large-scale (11M) pretraining dataset called RCS, based on the multi-person discussions in the Reddit community. We then present TANet, a thread-aware Transformer-based network. Unlike the existing pre-trained models that treat a conversation as a sequence of sentences, we argue that the inherent contextual dependency among the utterances plays an essential role in understanding the entire conversation and thus propose two new techniques to incorporate the structural information into our model. The first is thread-aware attention which is computed by taking into account the contextual dependency within utterances. Second, we apply thread prediction loss to predict the relations between utterances. We evaluate our model on four datasets of real conversations, covering types of meeting transcripts, customer-service records, and forum threads. Experimental results demonstrate that TANET achieves a new state-of-the-art in terms of both automatic evaluation and human judgment.
Domain-Oriented Prefix-Tuning: Towards Efficient and Generalizable Fine-tuning for Zero-Shot Dialogue Summarization
Apr 09, 2022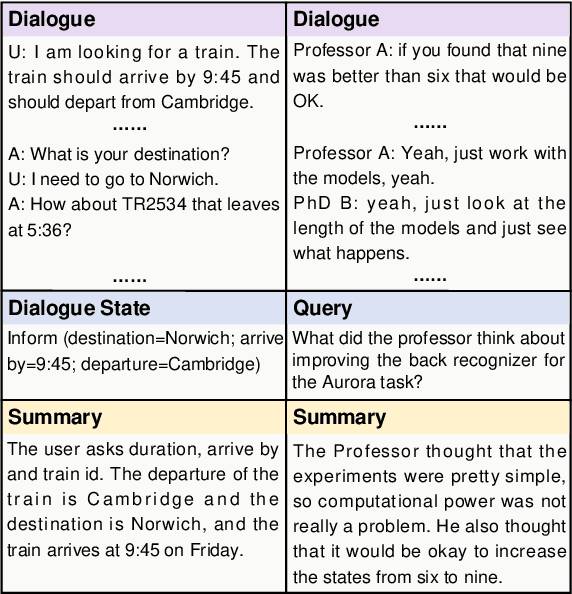
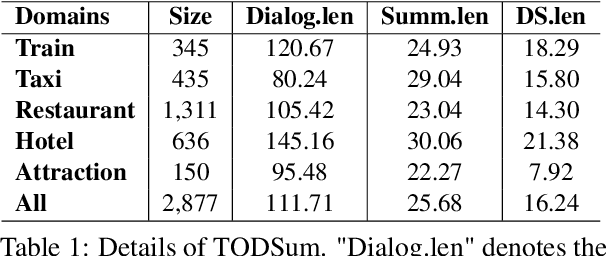
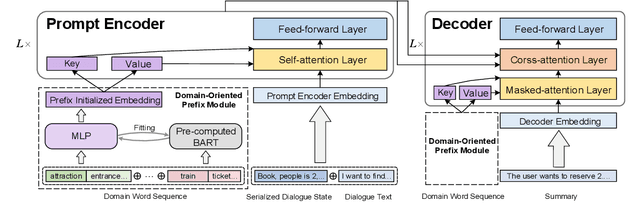
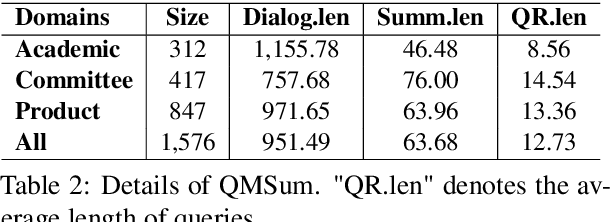
The most advanced abstractive dialogue summarizers lack generalization ability on new domains and the existing researches for domain adaptation in summarization generally rely on large-scale pre-trainings. To explore the lightweight fine-tuning methods for domain adaptation of dialogue summarization, in this paper, we propose an efficient and generalizable Domain-Oriented Prefix-tuning model, which utilizes a domain word initialized prefix module to alleviate domain entanglement and adopts discrete prompts to guide the model to focus on key contents of dialogues and enhance model generalization. We conduct zero-shot experiments and build domain adaptation benchmarks on two multi-domain dialogue summarization datasets, TODSum and QMSum. Adequate experiments and qualitative analysis prove the effectiveness of our methods.
Unsupervised Learning of Accurate Siamese Tracking
Apr 04, 2022
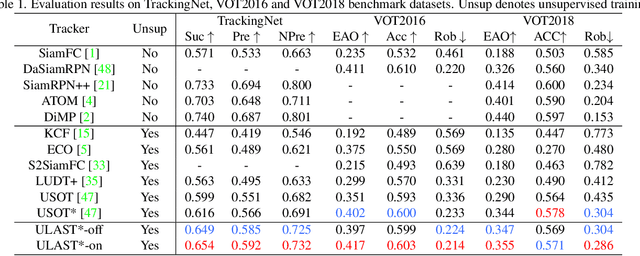
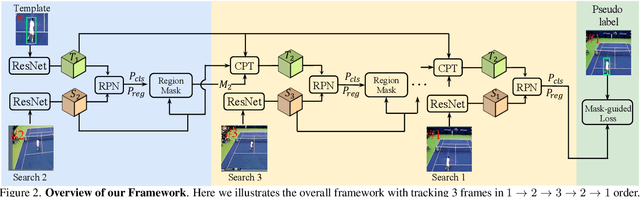
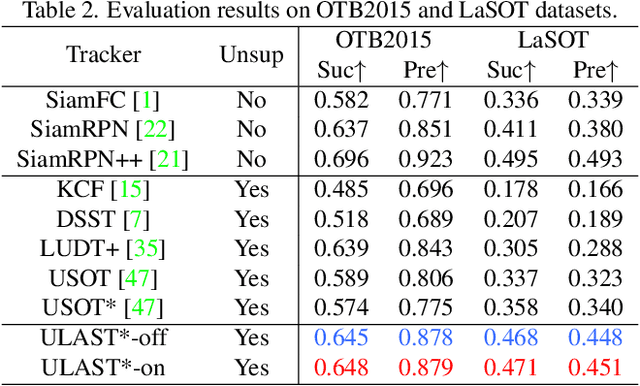
Unsupervised learning has been popular in various computer vision tasks, including visual object tracking. However, prior unsupervised tracking approaches rely heavily on spatial supervision from template-search pairs and are still unable to track objects with strong variation over a long time span. As unlimited self-supervision signals can be obtained by tracking a video along a cycle in time, we investigate evolving a Siamese tracker by tracking videos forward-backward. We present a novel unsupervised tracking framework, in which we can learn temporal correspondence both on the classification branch and regression branch. Specifically, to propagate reliable template feature in the forward propagation process so that the tracker can be trained in the cycle, we first propose a consistency propagation transformation. We then identify an ill-posed penalty problem in conventional cycle training in backward propagation process. Thus, a differentiable region mask is proposed to select features as well as to implicitly penalize tracking errors on intermediate frames. Moreover, since noisy labels may degrade training, we propose a mask-guided loss reweighting strategy to assign dynamic weights based on the quality of pseudo labels. In extensive experiments, our tracker outperforms preceding unsupervised methods by a substantial margin, performing on par with supervised methods on large-scale datasets such as TrackingNet and LaSOT. Code is available at https://github.com/FlorinShum/ULAST.
Incorporating Dynamic Semantics into Pre-Trained Language Model for Aspect-based Sentiment Analysis
Mar 30, 2022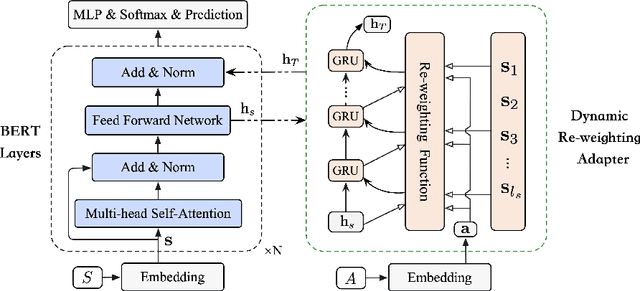
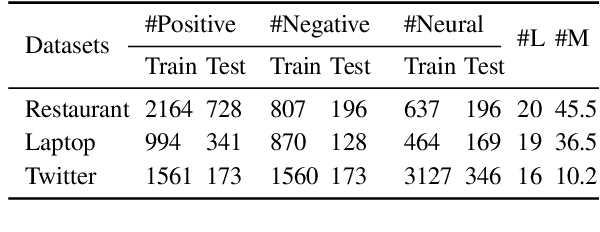
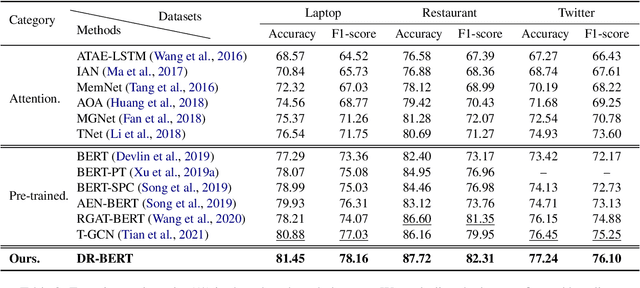
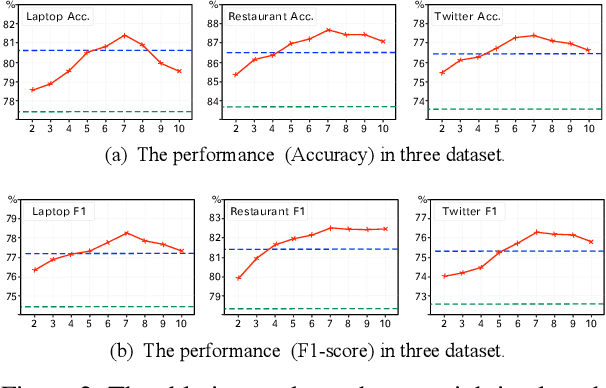
Aspect-based sentiment analysis (ABSA) predicts sentiment polarity towards a specific aspect in the given sentence. While pre-trained language models such as BERT have achieved great success, incorporating dynamic semantic changes into ABSA remains challenging. To this end, in this paper, we propose to address this problem by Dynamic Re-weighting BERT (DR-BERT), a novel method designed to learn dynamic aspect-oriented semantics for ABSA. Specifically, we first take the Stack-BERT layers as a primary encoder to grasp the overall semantic of the sentence and then fine-tune it by incorporating a lightweight Dynamic Re-weighting Adapter (DRA). Note that the DRA can pay close attention to a small region of the sentences at each step and re-weigh the vitally important words for better aspect-aware sentiment understanding. Finally, experimental results on three benchmark datasets demonstrate the effectiveness and the rationality of our proposed model and provide good interpretable insights for future semantic modeling.
Learning What You Need from What You Did: Product Taxonomy Expansion with User Behaviors Supervision
Mar 28, 2022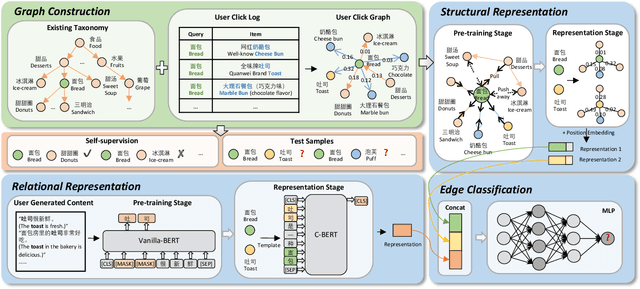
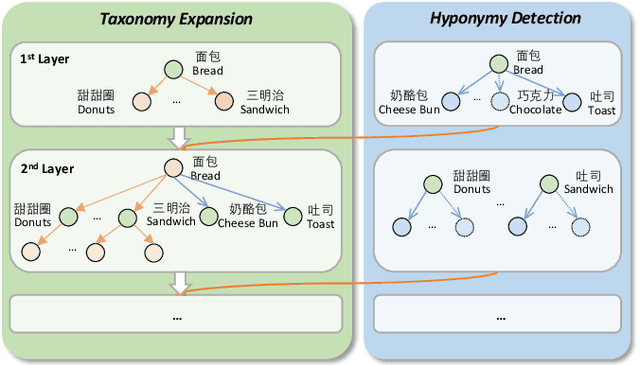
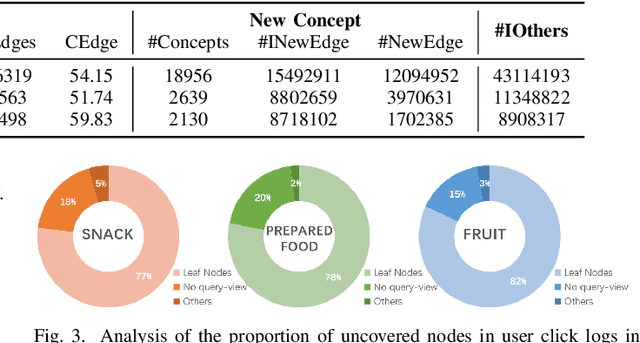
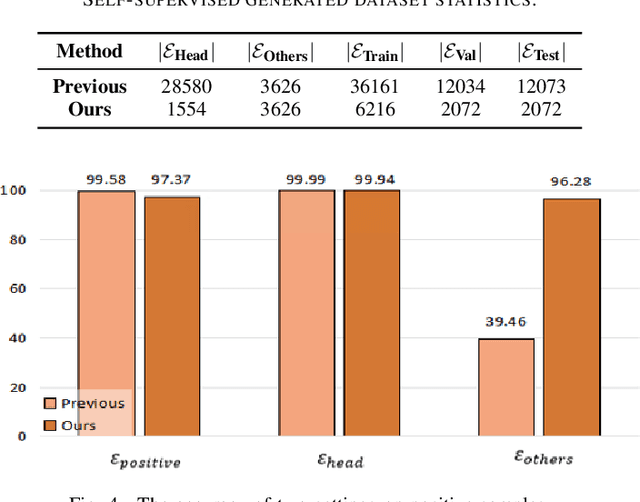
Taxonomies have been widely used in various domains to underpin numerous applications. Specially, product taxonomies serve an essential role in the e-commerce domain for the recommendation, browsing, and query understanding. However, taxonomies need to constantly capture the newly emerged terms or concepts in e-commerce platforms to keep up-to-date, which is expensive and labor-intensive if it relies on manual maintenance and updates. Therefore, we target the taxonomy expansion task to attach new concepts to existing taxonomies automatically. In this paper, we present a self-supervised and user behavior-oriented product taxonomy expansion framework to append new concepts into existing taxonomies. Our framework extracts hyponymy relations that conform to users' intentions and cognition. Specifically, i) to fully exploit user behavioral information, we extract candidate hyponymy relations that match user interests from query-click concepts; ii) to enhance the semantic information of new concepts and better detect hyponymy relations, we model concepts and relations through both user-generated content and structural information in existing taxonomies and user click logs, by leveraging Pre-trained Language Models and Graph Neural Network combined with Contrastive Learning; iii) to reduce the cost of dataset construction and overcome data skews, we construct a high-quality and balanced training dataset from existing taxonomy with no supervision. Extensive experiments on real-world product taxonomies in Meituan Platform, a leading Chinese vertical e-commerce platform to order take-out with more than 70 million daily active users, demonstrate the superiority of our proposed framework over state-of-the-art methods. Notably, our method enlarges the size of real-world product taxonomies from 39,263 to 94,698 relations with 88% precision.
ActFormer: A GAN Transformer Framework towards General Action-Conditioned 3D Human Motion Generation
Mar 15, 2022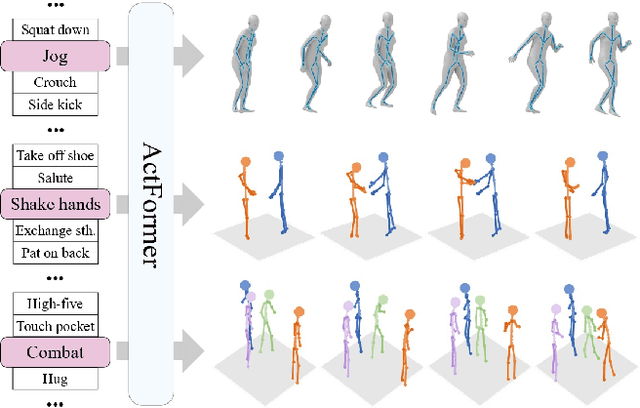

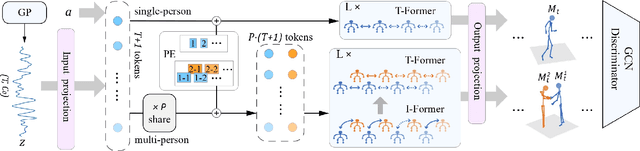

We present a GAN Transformer framework for general action-conditioned 3D human motion generation, including not only single-person actions but also multi-person interactive actions. Our approach consists of a powerful Action-conditioned motion transFormer (ActFormer) under a GAN training scheme, equipped with a Gaussian Process latent prior. Such a design combines the strong spatio-temporal representation capacity of Transformer, superiority in generative modeling of GAN, and inherent temporal correlations from latent prior. Furthermore, ActFormer can be naturally extended to multi-person motions by alternately modeling temporal correlations and human interactions with Transformer encoders. We validate our approach by comparison with other methods on larger-scale benchmarks, including NTU RGB+D 120 and BABEL. We also introduce a new synthetic dataset of complex multi-person combat behaviors to facilitate research on multi-person motion generation. Our method demonstrates adaptability to various human motion representations and achieves leading performance over SOTA methods on both single-person and multi-person motion generation tasks, indicating a hopeful step towards a universal human motion generator.