 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEM: A Native Graph-based Index for Multi-Vector Retrieval
Mar 20, 2026In multi-vector retrieval, both queries and data are represented as sets of high-dimensional vectors, enabling finer-grained semantic matching and improving retrieval quality over single-vector approaches. However, its practical adoption is held back by the lack of effective indexing algorithms. Existing work, attempting to reuse standard single-vector indexes, often fails to preserve multi-vector semantics or remains slow. In this work, we present GEM, a native indexing framework for multi-vector representations. The core idea is to construct a proximity graph directly over vector sets, preserving their fine-grained semantics while enabling efficient navigation. First, GEM designs a set-level clustering scheme. It associates each vector set with only its most informative clusters, effectively reducing redundancy without hurting semantic coverage. Then, it builds local proximity graphs within clusters and bridges them into a globally navigable structure. To handle the non-metric nature of multi-vector similarity, GEM decouples the graph construction metric from the final relevance score and injects semantic shortcuts to guide efficient navigation toward relevant regions. At query time, GEM launches beam search from multiple entry points and prunes paths early using cluster cues. To further enhance efficiency, a quantized distance estimation technique is used for both indexing and search. Across in-domain, out-of-domain, and multi-modal benchmarks, GEM achieves up to 16x speedup over state-of-the-art methods while matching or improving accuracy.
RAPO: An Adaptive Ranking Paradigm for Bilingual Lexicon Induction
Oct 18, 2022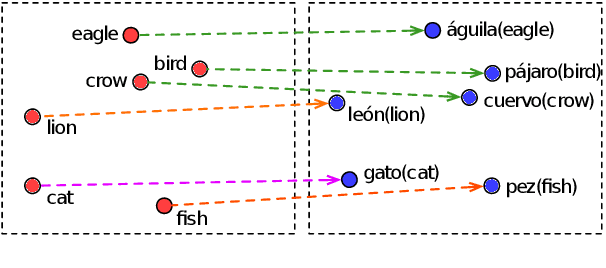
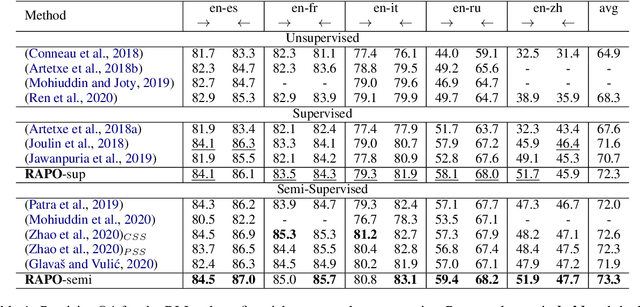
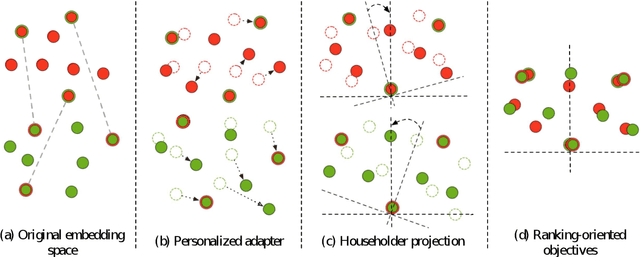
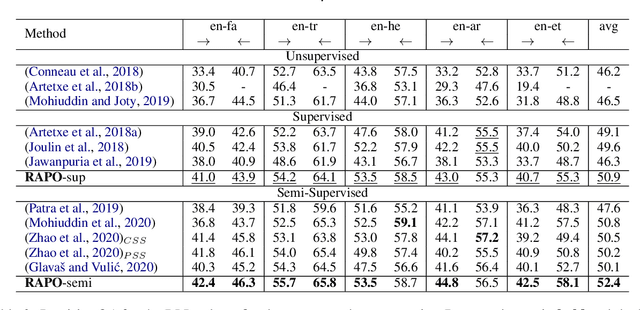
Bilingual lexicon induction induces the word translations by aligning independently trained word embeddings in two languages. Existing approaches generally focus on minimizing the distances between words in the aligned pairs, while suffering from low discriminative capability to distinguish the relative orders between positive and negative candidates. In addition, the mapping function is globally shared by all words, whose performance might be hindered by the deviations in the distributions of different languages. In this work, we propose a novel ranking-oriented induction model RAPO to learn personalized mapping function for each word. RAPO is capable of enjoying the merits from the unique characteristics of a single word and the cross-language isomorphism simultaneously. Extensive experimental results on public datasets including both rich-resource and low-resource languages demonstrate the superiority of our proposal. Our code is publicly available in \url{https://github.com/Jlfj345wf/RAPO}.
TANet: Thread-Aware Pretraining for Abstractive Conversational Summarization
Apr 09, 2022
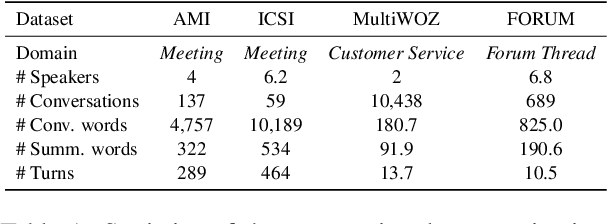
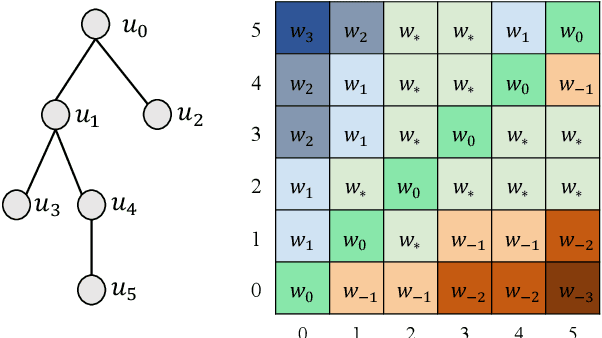
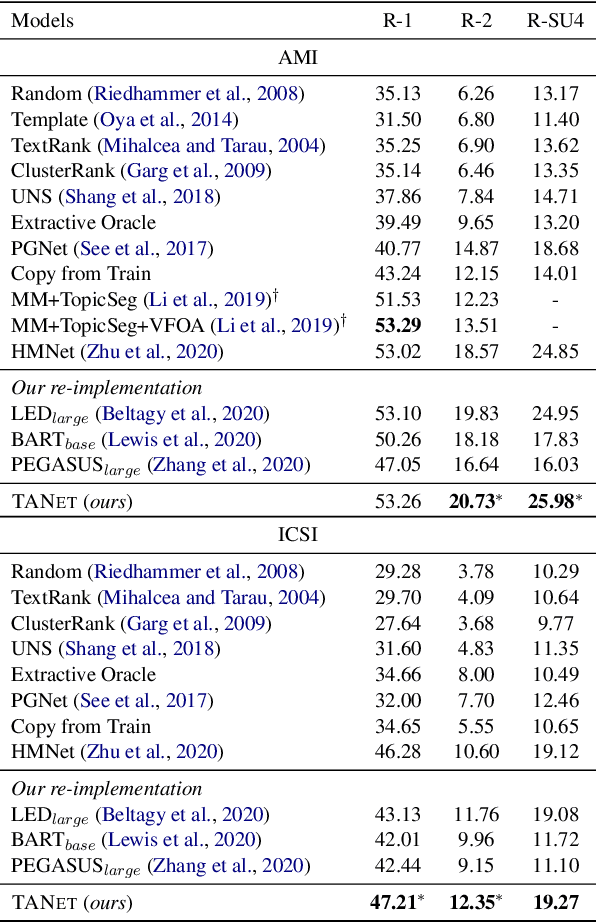
Although pre-trained language models (PLMs) have achieved great success and become a milestone in NLP, abstractive conversational summarization remains a challenging but less studied task. The difficulty lies in two aspects. One is the lack of large-scale conversational summary data. Another is that applying the existing pre-trained models to this task is tricky because of the structural dependence within the conversation and its informal expression, etc. In this work, we first build a large-scale (11M) pretraining dataset called RCS, based on the multi-person discussions in the Reddit community. We then present TANet, a thread-aware Transformer-based network. Unlike the existing pre-trained models that treat a conversation as a sequence of sentences, we argue that the inherent contextual dependency among the utterances plays an essential role in understanding the entire conversation and thus propose two new techniques to incorporate the structural information into our model. The first is thread-aware attention which is computed by taking into account the contextual dependency within utterances. Second, we apply thread prediction loss to predict the relations between utterances. We evaluate our model on four datasets of real conversations, covering types of meeting transcripts, customer-service records, and forum threads. Experimental results demonstrate that TANET achieves a new state-of-the-art in terms of both automatic evaluation and human judgment.