 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWei Liu
Word-level Lexical Normalisation using Context-Dependent Embeddings
Nov 13, 2019
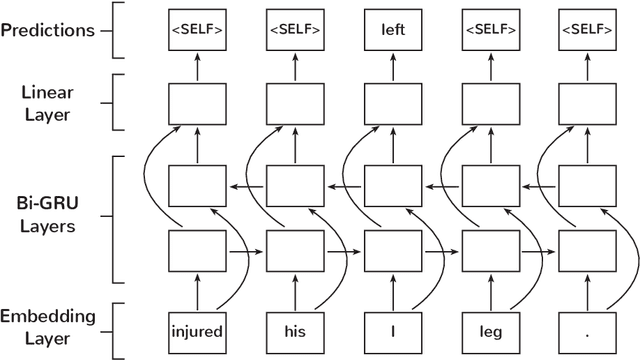
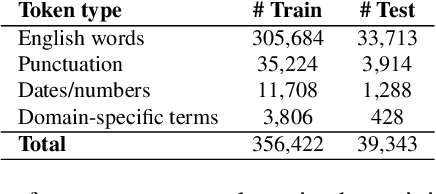

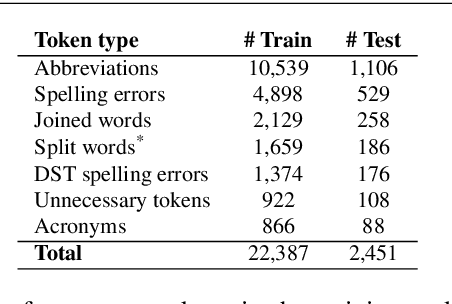
Lexical normalisation (LN) is the process of correcting each word in a dataset to its canonical form so that it may be more easily and more accurately analysed. Most lexical normalisation systems operate at the character-level, while word-level models are seldom used. Recent language models offer solutions to the drawbacks of word-level LN models, yet, to the best of our knowledge, no research has investigated their effectiveness on LN. In this paper we introduce a word-level GRU-based LN model and investigate the effectiveness of recent embedding techniques on word-level LN. Our results show that our GRU-based word-level model produces greater results than character-level models, and outperforms existing deep-learning based LN techniques on Twitter data. We also find that randomly-initialised embeddings are capable of outperforming pre-trained embedding models in certain scenarios. Finally, we release a substantial lexical normalisation dataset to the community.
Semantic Conditioned Dynamic Modulation for Temporal Sentence Grounding in Videos
Oct 31, 2019
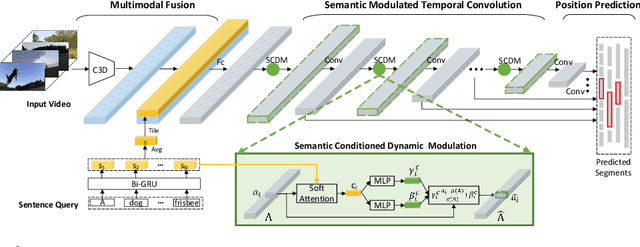
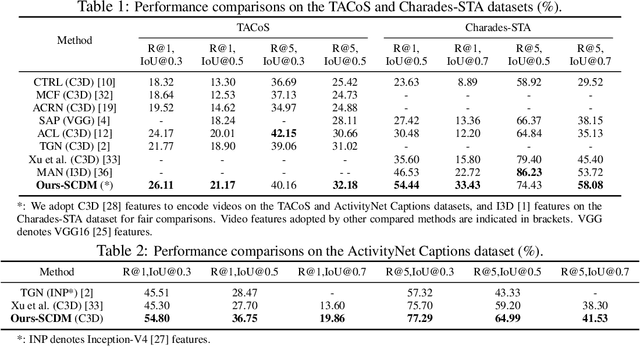
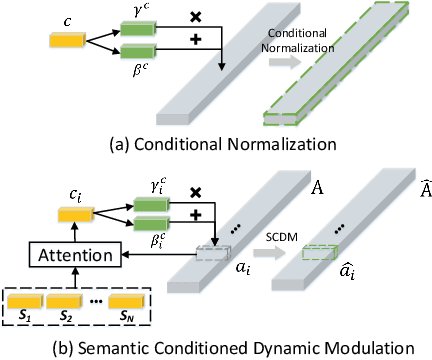
Temporal sentence grounding in videos aims to detect and localize one target video segment, which semantically corresponds to a given sentence. Existing methods mainly tackle this task via matching and aligning semantics between a sentence and candidate video segments, while neglect the fact that the sentence information plays an important role in temporally correlating and composing the described contents in videos. In this paper, we propose a novel semantic conditioned dynamic modulation (SCDM) mechanism, which relies on the sentence semantics to modulate the temporal convolution operations for better correlating and composing the sentence related video contents over time. More importantly, the proposed SCDM performs dynamically with respect to the diverse video contents so as to establish a more precise matching relationship between sentence and video, thereby improving the temporal grounding accuracy. Extensive experiments on three public datasets demonstrate that our proposed model outperforms the state-of-the-arts with clear margins, illustrating the ability of SCDM to better associate and localize relevant video contents for temporal sentence grounding. Our code for this paper is available at https://github.com/yytzsy/SCDM .
Multi-View Features and Hybrid Reward Strategies for Vatex Video Captioning Challenge 2019
Oct 31, 2019
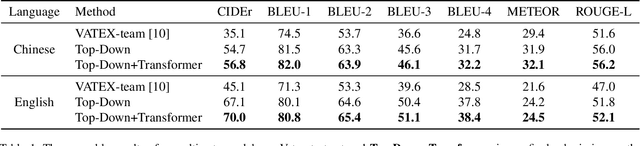
This document describes our solution for the VATEX Captioning Challenge 2019, which requires generating descriptions for the videos in both English and Chinese languages. We identified three crucial factors that improve the performance, namely: multi-view features, hybrid reward, and diverse ensemble. Our method achieves the 2nd and the 3rd places on the Chinese and English video captioning tracks, respectively.
Category Anchor-Guided Unsupervised Domain Adaptation for Semantic Segmentation
Oct 29, 2019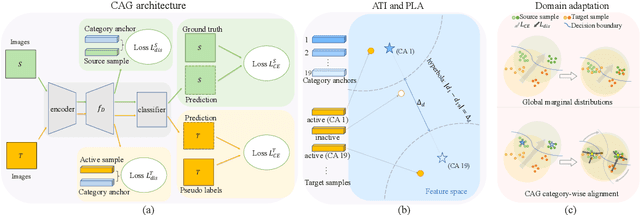
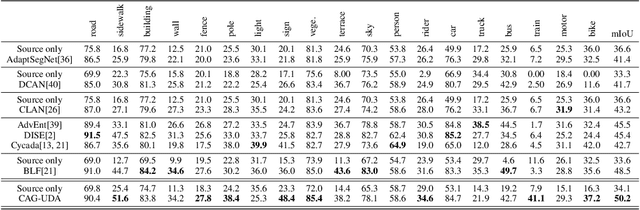

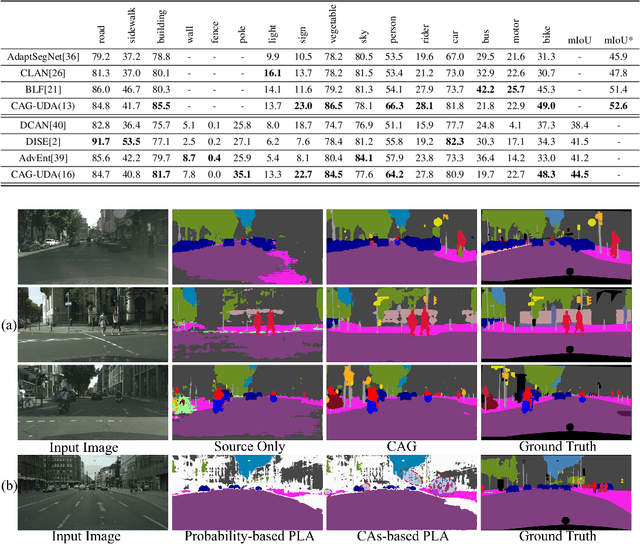
Unsupervised domain adaptation (UDA) aims to enhance the generalization capability of a certain model from a source domain to a target domain. UDA is of particular significance since no extra effort is devoted to annotating target domain samples. However, the different data distributions in the two domains, or \emph{domain shift/discrepancy}, inevitably compromise the UDA performance. Although there has been a progress in matching the marginal distributions between two domains, the classifier favors the source domain features and makes incorrect predictions on the target domain due to category-agnostic feature alignment. In this paper, we propose a novel category anchor-guided (CAG) UDA model for semantic segmentation, which explicitly enforces category-aware feature alignment to learn shared discriminative features and classifiers simultaneously. First, the category-wise centroids of the source domain features are used as guided anchors to identify the active features in the target domain and also assign them pseudo-labels. Then, we leverage an anchor-based pixel-level distance loss and a discriminative loss to drive the intra-category features closer and the inter-category features further apart, respectively. Finally, we devise a stagewise training mechanism to reduce the error accumulation and adapt the proposed model progressively. Experiments on both the GTA5$\rightarrow $Cityscapes and SYNTHIA$\rightarrow $Cityscapes scenarios demonstrate the superiority of our CAG-UDA model over the state-of-the-art methods. The code is available at \url{https://github.com/RogerZhangzz/CAG\_UDA}.
Diversifying Topic-Coherent Response Generation for Natural Multi-turn Conversations
Oct 24, 2019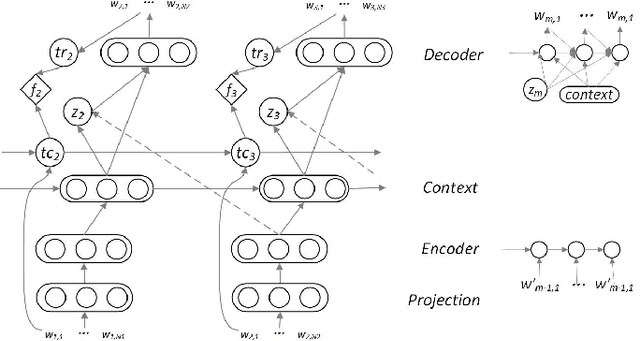
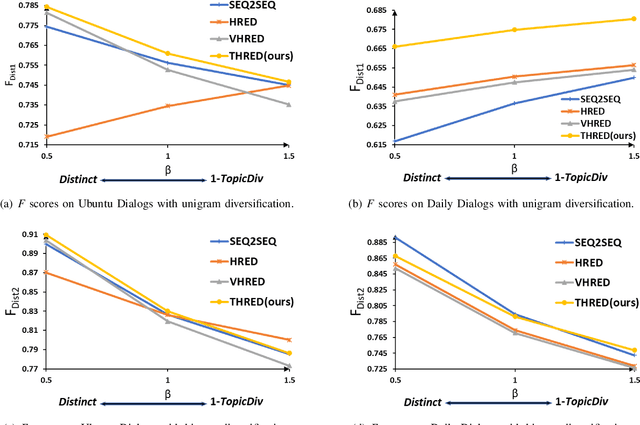

Although response generation (RG) diversification for single-turn dialogs has been well developed, it is less investigated for natural multi-turn conversations. Besides, past work focused on diversifying responses without considering topic coherence to the context, producing uninformative replies. In this paper, we propose the Topic-coherent Hierarchical Recurrent Encoder-Decoder model (THRED) to diversify the generated responses without deviating the contextual topics for multi-turn conversations. In overall, we build a sequence-to-sequence net (Seq2Seq) to model multi-turn conversations. And then we resort to the latent Variable Hierarchical Recurrent Encoder-Decoder model (VHRED) to learn global contextual distribution of dialogs. Besides, we construct a dense topic matrix which implies word-level correlations of the conversation corpora. The topic matrix is used to learn local topic distribution of the contextual utterances. By incorporating both the global contextual distribution and the local topic distribution, THRED produces both diversified and topic-coherent replies. In addition, we propose an explicit metric (\emph{TopicDiv}) to measure the topic divergence between the post and generated response, and we also propose an overall metric combining the diversification metric (\emph{Distinct}) and \emph{TopicDiv}. We evaluate our model comparing with three baselines (Seq2Seq, HRED and VHRED) on two real-world corpora, respectively, and demonstrate its outstanding performance in both diversification and topic coherence.
Context-Gated Convolution
Oct 22, 2019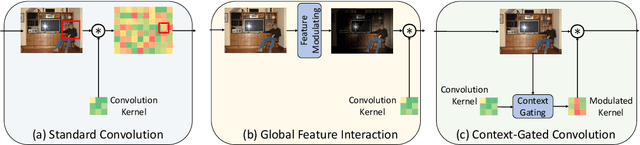
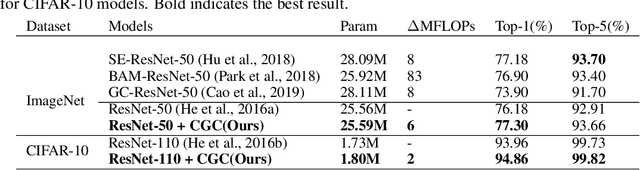
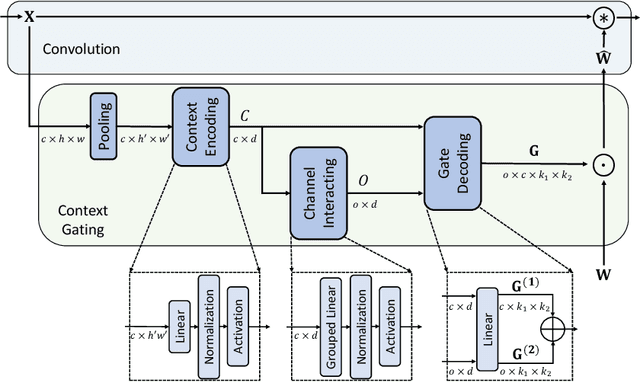
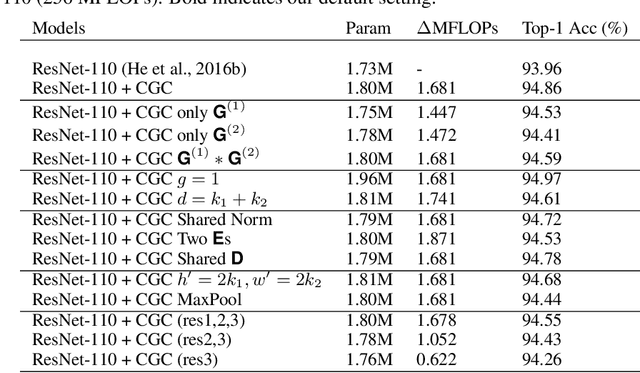
As the basic building block of Convolutional Neural Networks (CNNs), the convolutional layer is designed to extract local patterns and lacks the ability to model global context in its nature. Many efforts have been recently devoted to complementing CNNs with the global modeling ability, especially by a family of works on global feature interaction. In these works, the global context information is incorporated into local features before they are fed into convolutional layers. However, research on neuroscience reveals that, besides influences changing the inputs to our neurons, the neurons' ability of modifying their functions dynamically according to context is essential for perceptual tasks, which has been overlooked in most of CNNs. Motivated by this, we propose one novel Context-Gated Convolution (CGC) to explicitly modify the weights of convolutional layers adaptively under the guidance of global context. As such, being aware of the global context, the modulated convolution kernel of our proposed CGC can better extract representative local patterns and compose discriminative features. Moreover, our proposed CGC is lightweight, amenable to modern CNN architectures, and consistently improves the performance of CNNs according to extensive experiments on image classification, action recognition, and machine translation.
Deep Multiphase Level Set for Scene Parsing
Oct 13, 2019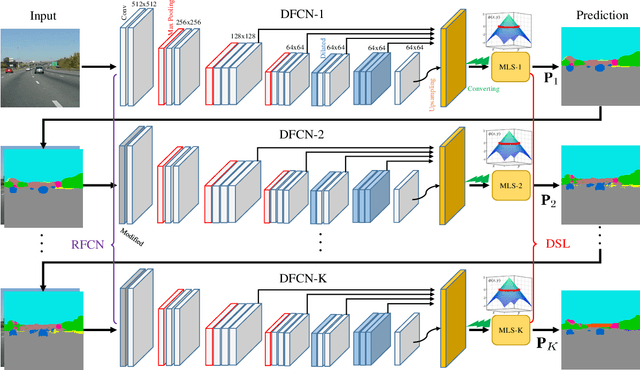
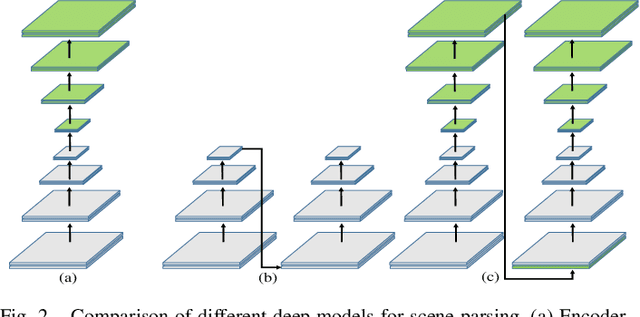
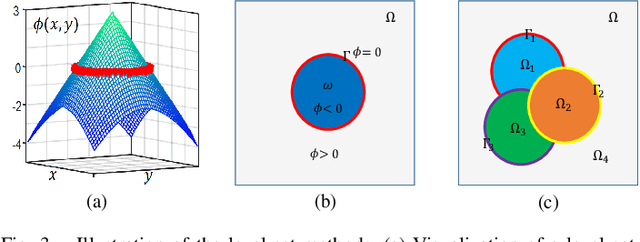
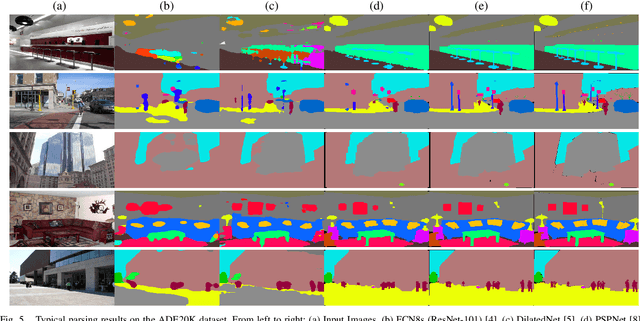
Recently, Fully Convolutional Network (FCN) seems to be the go-to architecture for image segmentation, including semantic scene parsing. However, it is difficult for a generic FCN to discriminate pixels around the object boundaries, thus FCN based methods may output parsing results with inaccurate boundaries. Meanwhile, level set based active contours are superior to the boundary estimation due to the sub-pixel accuracy that they achieve. However, they are quite sensitive to initial settings. To address these limitations, in this paper we propose a novel Deep Multiphase Level Set (DMLS) method for semantic scene parsing, which efficiently incorporates multiphase level sets into deep neural networks. The proposed method consists of three modules, i.e., recurrent FCNs, adaptive multiphase level set, and deeply supervised learning. More specifically, recurrent FCNs learn multi-level representations of input images with different contexts. Adaptive multiphase level set drives the discriminative contour for each semantic class, which makes use of the advantages of both global and local information. In each time-step of the recurrent FCNs, deeply supervised learning is incorporated for model training. Extensive experiments on three public benchmarks have shown that our proposed method achieves new state-of-the-art performances.
Accelerating Federated Learning via Momentum Gradient Descent
Oct 09, 2019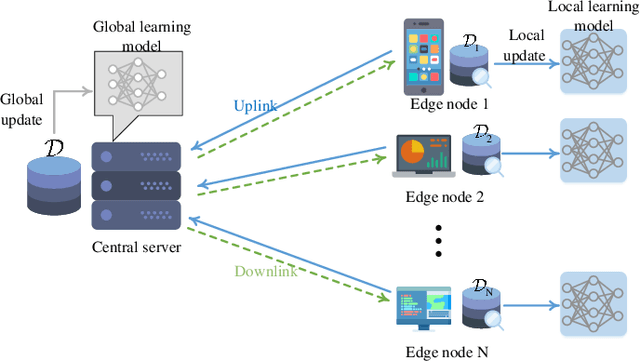
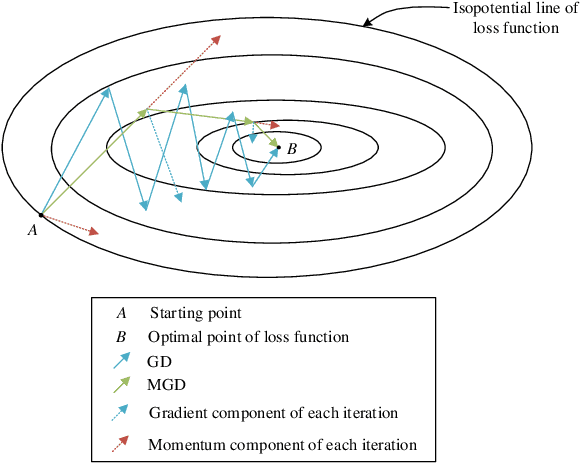
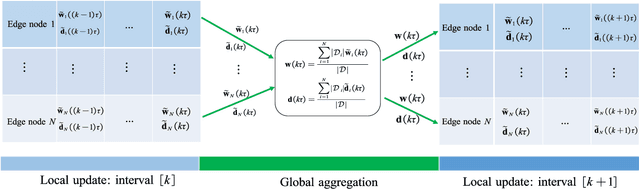
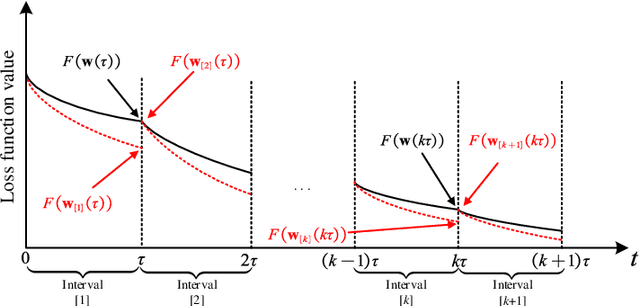
Federated learning (FL) provides a communication-efficient approach to solve machine learning problems concerning distributed data, without sending raw data to a central server. However, existing works on FL only utilize first-order gradient descent (GD) and do not consider the preceding iterations to gradient update which can potentially accelerate convergence. In this paper, we consider momentum term which relates to the last iteration. The proposed momentum federated learning (MFL) uses momentum gradient descent (MGD) in the local update step of FL system. We establish global convergence properties of MFL and derive an upper bound on MFL convergence rate. Comparing the upper bounds on MFL and FL convergence rate, we provide conditions in which MFL accelerates the convergence. For different machine learning models, the convergence performance of MFL is evaluated based on experiments with MNIST dataset. Simulation results comfirm that MFL is globally convergent and further reveal significant convergence improvement over FL.