 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser-Driven Voice Generation and Editing through Latent Space Navigation
Aug 30, 2024



This paper presents a user-driven approach for synthesizing highly specific target voices based on user feedback, which is particularly beneficial for speech-impaired individuals who wish to recreate their lost voices but lack prior recordings. Specifically, we leverage the neural analysis and synthesis framework to construct a low-dimensional, yet sufficiently expressive latent speaker embedding space. Within this latent space, we implement a search algorithm that guides users to their desired voice through completing a sequence of straightforward comparison tasks. Both synthetic simulations and real-world user studies demonstrate that the proposed approach can effectively approximate target voices. Moreover, by analyzing the mel-spectrogram generator's Jacobians, we identify a set of meaningful voice editing directions within the latent space. These directions enable users to further fine-tune specific attributes of the generated voice, including the pitch level, pitch range, volume, vocal tension, nasality, and tone color. Audio samples are available at https://myspeechprojects.github.io/voicedesign/.
Creating Personalized Synthetic Voices from Articulation Impaired Speech Using Augmented Reconstruction Loss
Jan 08, 2024


This research is about the creation of personalized synthetic voices for head and neck cancer survivors. It is focused particularly on tongue cancer patients whose speech might exhibit severe articulation impairment. Our goal is to restore normal articulation in the synthesized speech, while maximally preserving the target speaker's individuality in terms of both the voice timbre and speaking style. This is formulated as a task of learning from noisy labels. We propose to augment the commonly used speech reconstruction loss with two additional terms. The first term constitutes a regularization loss that mitigates the impact of distorted articulation in the training speech. The second term is a consistency loss that encourages correct articulation in the generated speech. These additional loss terms are obtained from frame-level articulation scores of original and generated speech, which are derived using a separately trained phone classifier. Experimental results on a real case of tongue cancer patient confirm that the synthetic voice achieves comparable articulation quality to unimpaired natural speech, while effectively maintaining the target speaker's individuality. Audio samples are available at https://myspeechproject.github.io/ArticulationRepair/.
Creating Personalized Synthetic Voices from Post-Glossectomy Speech with Guided Diffusion Models
May 27, 2023



This paper is about developing personalized speech synthesis systems with recordings of mildly impaired speech. In particular, we consider consonant and vowel alterations resulted from partial glossectomy, the surgical removal of part of the tongue. The aim is to restore articulation in the synthesized speech and maximally preserve the target speaker's individuality. We propose to tackle the problem with guided diffusion models. Specifically, a diffusion-based speech synthesis model is trained on original recordings, to capture and preserve the target speaker's original articulation style. When using the model for inference, a separately trained phone classifier will guide the synthesis process towards proper articulation. Objective and subjective evaluation results show that the proposed method substantially improves articulation in the synthesized speech over original recordings, and preserves more of the target speaker's individuality than a voice conversion baseline.
Diffusion-Based Mel-Spectrogram Enhancement for Personalized Speech Synthesis with Found Data
May 18, 2023Creating synthetic voices with found data is challenging, as real-world recordings often contain various types of audio degradation. One way to address this problem is to pre-enhance the speech with an enhancement model and then use the enhanced data for text-to-speech (TTS) model training. Ideally, the enhancement model should be able to tackle multiple types of audio degradation simultaneously. This paper investigates the use of conditional diffusion models for generalized speech enhancement. The enhancement is performed on the log Mel-spectrogram domain to align with the TTS training objective. Text information is introduced as an additional condition to improve the model robustness. Experiments on real-world recordings demonstrate that the synthetic voice built on data enhanced by the proposed model produces higher-quality synthetic speech, compared to those trained on data enhanced by strong baselines. Audio samples are available at \url{https://dmse4tts.github.io/}.
Convolution-Based Channel-Frequency Attention for Text-Independent Speaker Verification
Oct 31, 2022



Deep convolutional neural networks (CNNs) have been applied to extracting speaker embeddings with significant success in speaker verification. Incorporating the attention mechanism has shown to be effective in improving the model performance. This paper presents an efficient two-dimensional convolution-based attention module, namely C2D-Att. The interaction between the convolution channel and frequency is involved in the attention calculation by lightweight convolution layers. This requires only a small number of parameters. Fine-grained attention weights are produced to represent channel and frequency-specific information. The weights are imposed on the input features to improve the representation ability for speaker modeling. The C2D-Att is integrated into a modified version of ResNet for speaker embedding extraction. Experiments are conducted on VoxCeleb datasets. The results show that C2DAtt is effective in generating discriminative attention maps and outperforms other attention methods. The proposed model shows robust performance with different scales of model size and achieves state-of-the-art results.
Transport-Oriented Feature Aggregation for Speaker Embedding Learning
Jun 26, 2022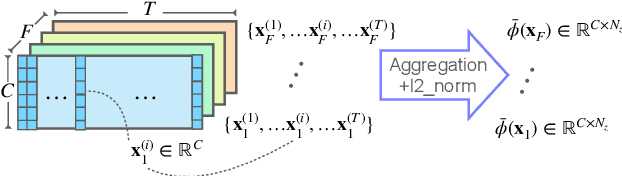

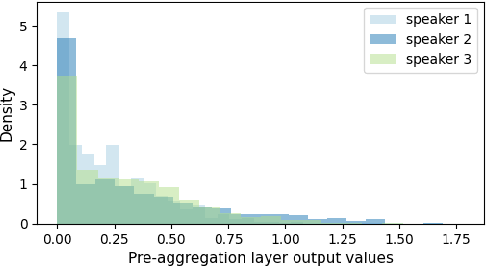
Pooling is needed to aggregate frame-level features into utterance-level representations for speaker modeling. Given the success of statistics-based pooling methods, we hypothesize that speaker characteristics are well represented in the statistical distribution over the pre-aggregation layer's output, and propose to use transport-oriented feature aggregation for deriving speaker embeddings. The aggregated representation encodes the geometric structure of the underlying feature distribution, which is expected to contain valuable speaker-specific information that may not be represented by the commonly used statistical measures like mean and variance. The original transport-oriented feature aggregation is also extended to a weighted-frame version to incorporate the attention mechanism. Experiments on speaker verification with the Voxceleb dataset show improvement over statistics pooling and its attentive variant.
Learnable Frequency Filters for Speech Feature Extraction in Speaker Verification
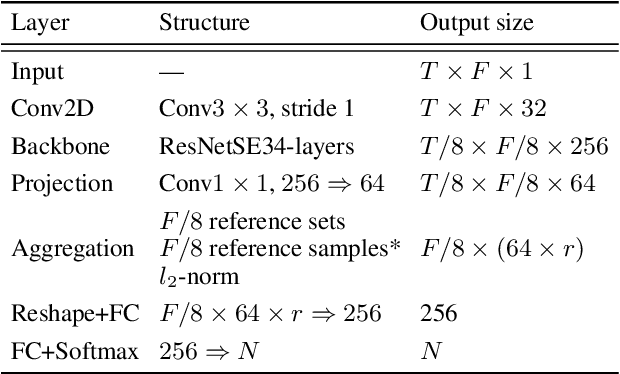
Jun 15, 2022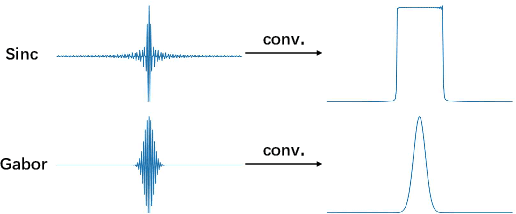
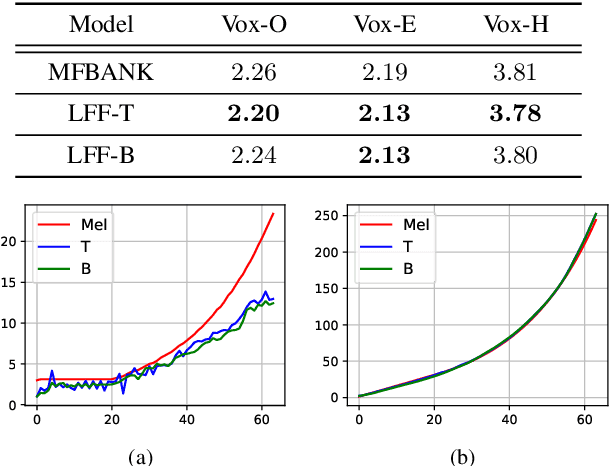
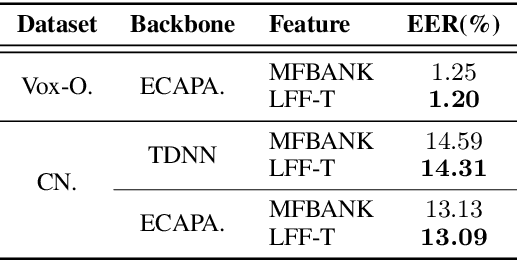
Mel-scale spectrum features are used in various recognition and classification tasks on speech signals. There is no reason to expect that these features are optimal for all different tasks, including speaker verification (SV). This paper describes a learnable front-end feature extraction model. The model comprises a group of filters to transform the Fourier spectrum. Model parameters that define these filters are trained end-to-end and optimized specifically for the task of speaker verification. Compared to the standard Mel-scale filter-bank, the filters' bandwidths and center frequencies are adjustable. Experimental results show that applying the learnable acoustic front-end improves speaker verification performance over conventional Mel-scale spectrum features. Analysis on the learned filter parameters suggests that narrow-band information benefits the SV system performance. The proposed model achieves a good balance between performance and computation cost. In resource-constrained computation settings, the model significantly outperforms CNN-based learnable front-ends. The generalization ability of the proposed model is also demonstrated on different embedding extraction models and datasets.
Improving End-to-End Speech-to-Intent Classification with Reptile
Aug 05, 2020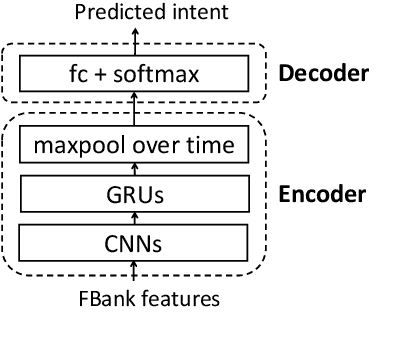
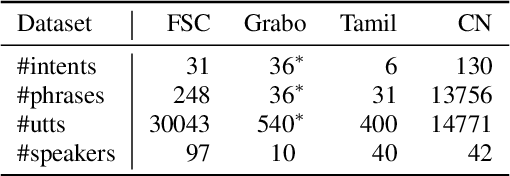
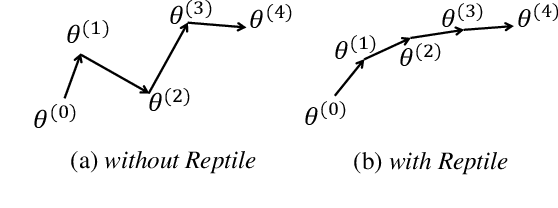
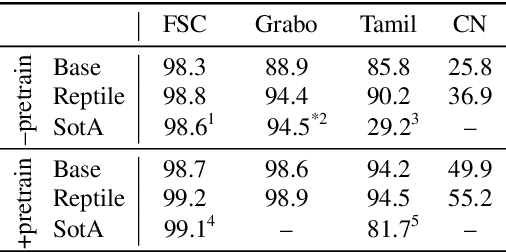
End-to-end spoken language understanding (SLU) systems have many advantages over conventional pipeline systems, but collecting in-domain speech data to train an end-to-end system is costly and time consuming. One question arises from this: how to train an end-to-end SLU with limited amounts of data? Many researchers have explored approaches that make use of other related data resources, typically by pre-training parts of the model on high-resource speech recognition. In this paper, we suggest improving the generalization performance of SLU models with a non-standard learning algorithm, Reptile. Though Reptile was originally proposed for model-agnostic meta learning, we argue that it can also be used to directly learn a target task and result in better generalization than conventional gradient descent. In this work, we employ Reptile to the task of end-to-end spoken intent classification. Experiments on four datasets of different languages and domains show improvement of intent prediction accuracy, both when Reptile is used alone and used in addition to pre-training.