 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntailE: Introducing Textual Entailment in Commonsense Knowledge Graph Completion
Feb 15, 2024



Commonsense knowledge graph completion is a new challenge for commonsense knowledge graph construction and application. In contrast to factual knowledge graphs such as Freebase and YAGO, commonsense knowledge graphs (CSKGs; e.g., ConceptNet) utilize free-form text to represent named entities, short phrases, and events as their nodes. Such a loose structure results in large and sparse CSKGs, which makes the semantic understanding of these nodes more critical for learning rich commonsense knowledge graph embedding. While current methods leverage semantic similarities to increase the graph density, the semantic plausibility of the nodes and their relations are under-explored. Previous works adopt conceptual abstraction to improve the consistency of modeling (event) plausibility, but they are not scalable enough and still suffer from data sparsity. In this paper, we propose to adopt textual entailment to find implicit entailment relations between CSKG nodes, to effectively densify the subgraph connecting nodes within the same conceptual class, which indicates a similar level of plausibility. Each node in CSKG finds its top entailed nodes using a finetuned transformer over natural language inference (NLI) tasks, which sufficiently capture textual entailment signals. The entailment relation between these nodes are further utilized to: 1) build new connections between source triplets and entailed nodes to densify the sparse CSKGs; 2) enrich the generalization ability of node representations by comparing the node embeddings with a contrastive loss. Experiments on two standard CSKGs demonstrate that our proposed framework EntailE can improve the performance of CSKG completion tasks under both transductive and inductive settings.
Towards Robust Model-Based Reinforcement Learning Against Adversarial Corruption
Feb 15, 2024This study tackles the challenges of adversarial corruption in model-based reinforcement learning (RL), where the transition dynamics can be corrupted by an adversary. Existing studies on corruption-robust RL mostly focus on the setting of model-free RL, where robust least-square regression is often employed for value function estimation. However, these techniques cannot be directly applied to model-based RL. In this paper, we focus on model-based RL and take the maximum likelihood estimation (MLE) approach to learn transition model. Our work encompasses both online and offline settings. In the online setting, we introduce an algorithm called corruption-robust optimistic MLE (CR-OMLE), which leverages total-variation (TV)-based information ratios as uncertainty weights for MLE. We prove that CR-OMLE achieves a regret of $\tilde{\mathcal{O}}(\sqrt{T} + C)$, where $C$ denotes the cumulative corruption level after $T$ episodes. We also prove a lower bound to show that the additive dependence on $C$ is optimal. We extend our weighting technique to the offline setting, and propose an algorithm named corruption-robust pessimistic MLE (CR-PMLE). Under a uniform coverage condition, CR-PMLE exhibits suboptimality worsened by $\mathcal{O}(C/n)$, nearly matching the lower bound. To the best of our knowledge, this is the first work on corruption-robust model-based RL algorithms with provable guarantees.
A Theoretical Analysis of Nash Learning from Human Feedback under General KL-Regularized Preference
Feb 11, 2024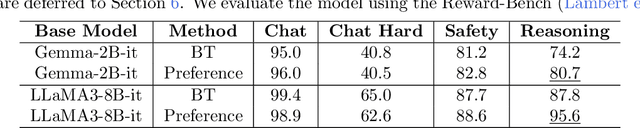
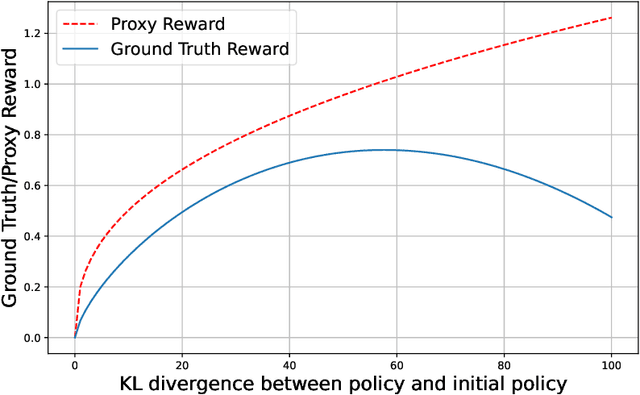

Reinforcement Learning from Human Feedback (RLHF) learns from the preference signal provided by a probabilistic preference model, which takes a prompt and two responses as input, and produces a score indicating the preference of one response against another. So far, the most popular RLHF paradigm is reward-based, which starts with an initial step of reward modeling, and the constructed reward is then used to provide a reward signal for the subsequent reward optimization stage. However, the existence of a reward function is a strong assumption and the reward-based RLHF is limited in expressivity and cannot capture the real-world complicated human preference. In this work, we provide theoretical insights for a recently proposed learning paradigm, Nash learning from human feedback (NLHF), which considered a general preference model and formulated the alignment process as a game between two competitive LLMs. The learning objective is to find a policy that consistently generates responses preferred over any competing policy while staying close to the initial model. The objective is defined as the Nash equilibrium (NE) of the KL-regularized preference model. We aim to make the first attempt to study the theoretical learnability of the KL-regularized NLHF by considering both offline and online settings. For the offline learning from a pre-collected dataset, we propose algorithms that are efficient under suitable coverage conditions of the dataset. For batch online learning from iterative interactions with a preference oracle, our proposed algorithm enjoys a finite sample guarantee under the structural condition of the underlying preference model. Our results connect the new NLHF paradigm with traditional RL theory, and validate the potential of reward-model-free learning under general preference.
The Instinctive Bias: Spurious Images lead to Hallucination in MLLMs
Feb 06, 2024



Large language models (LLMs) have recently experienced remarkable progress, where the advent of multi-modal large language models (MLLMs) has endowed LLMs with visual capabilities, leading to impressive performances in various multi-modal tasks. However, those powerful MLLMs such as GPT-4V still fail spectacularly when presented with certain image and text inputs. In this paper, we identify a typical class of inputs that baffles MLLMs, which consist of images that are highly relevant but inconsistent with answers, causing MLLMs to suffer from hallucination. To quantify the effect, we propose CorrelationQA, the first benchmark that assesses the hallucination level given spurious images. This benchmark contains 7,308 text-image pairs across 13 categories. Based on the proposed CorrelationQA, we conduct a thorough analysis on 9 mainstream MLLMs, illustrating that they universally suffer from this instinctive bias to varying degrees. We hope that our curated benchmark and evaluation results aid in better assessments of the MLLMs' robustness in the presence of misleading images. The resource is available in https://github.com/MasaiahHan/CorrelationQA.
EarthGPT: A Universal Multi-modal Large Language Model for Multi-sensor Image Comprehension in Remote Sensing Domain
Feb 05, 2024



Multi-modal large language models (MLLMs) have demonstrated remarkable success in vision and visual-language tasks within the natural image domain. Owing to the significant diversities between the natural and remote sensing (RS) images, the development of MLLMs in the RS domain is still in the infant stage. To fill the gap, a pioneer MLLM named EarthGPT integrating various multi-sensor RS interpretation tasks uniformly is proposed in this paper for universal RS image comprehension. In EarthGPT, three key techniques are developed including a visual-enhanced perception mechanism, a cross-modal mutual comprehension approach, and a unified instruction tuning method for multi-sensor multi-task in the RS domain. More importantly, a dataset named MMRS-1M featuring large-scale multi-sensor multi-modal RS instruction-following is constructed, comprising over 1M image-text pairs based on 34 existing diverse RS datasets and including multi-sensor images such as optical, synthetic aperture radar (SAR), and infrared. The MMRS-1M dataset addresses the drawback of MLLMs on RS expert knowledge and stimulates the development of MLLMs in the RS domain. Extensive experiments are conducted, demonstrating the EarthGPT's superior performance in various RS visual interpretation tasks compared with the other specialist models and MLLMs, proving the effectiveness of the proposed EarthGPT and offering a versatile paradigm for open-set reasoning tasks.
PipeNet: Question Answering with Semantic Pruning over Knowledge Graphs
Jan 31, 2024



It is well acknowledged that incorporating explicit knowledge graphs (KGs) can benefit question answering. Existing approaches typically follow a grounding-reasoning pipeline in which entity nodes are first grounded for the query (question and candidate answers), and then a reasoning module reasons over the matched multi-hop subgraph for answer prediction. Although the pipeline largely alleviates the issue of extracting essential information from giant KGs, efficiency is still an open challenge when scaling up hops in grounding the subgraphs. In this paper, we target at finding semantically related entity nodes in the subgraph to improve the efficiency of graph reasoning with KG. We propose a grounding-pruning-reasoning pipeline to prune noisy nodes, remarkably reducing the computation cost and memory usage while also obtaining decent subgraph representation. In detail, the pruning module first scores concept nodes based on the dependency distance between matched spans and then prunes the nodes according to score ranks. To facilitate the evaluation of pruned subgraphs, we also propose a graph attention network (GAT) based module to reason with the subgraph data. Experimental results on CommonsenseQA and OpenBookQA demonstrate the effectiveness of our method.
The Surprising Harmfulness of Benign Overfitting for Adversarial Robustness
Jan 25, 2024
Recent empirical and theoretical studies have established the generalization capabilities of large machine learning models that are trained to (approximately or exactly) fit noisy data. In this work, we prove a surprising result that even if the ground truth itself is robust to adversarial examples, and the benignly overfitted model is benign in terms of the ``standard'' out-of-sample risk objective, this benign overfitting process can be harmful when out-of-sample data are subject to adversarial manipulation. More specifically, our main results contain two parts: (i) the min-norm estimator in overparameterized linear model always leads to adversarial vulnerability in the ``benign overfitting'' setting; (ii) we verify an asymptotic trade-off result between the standard risk and the ``adversarial'' risk of every ridge regression estimator, implying that under suitable conditions these two items cannot both be small at the same time by any single choice of the ridge regularization parameter. Furthermore, under the lazy training regime, we demonstrate parallel results on two-layer neural tangent kernel (NTK) model, which align with empirical observations in deep neural networks. Our finding provides theoretical insights into the puzzling phenomenon observed in practice, where the true target function (e.g., human) is robust against adverasrial attack, while beginly overfitted neural networks lead to models that are not robust.
General Flow as Foundation Affordance for Scalable Robot Learning
Jan 21, 2024



We address the challenge of acquiring real-world manipulation skills with a scalable framework.Inspired by the success of large-scale auto-regressive prediction in Large Language Models (LLMs), we hold the belief that identifying an appropriate prediction target capable of leveraging large-scale datasets is crucial for achieving efficient and universal learning. Therefore, we propose to utilize flow, which represents the future trajectories of 3D points on objects of interest, as an ideal prediction target in robot learning. To exploit scalable data resources, we turn our attention to cross-embodiment datasets. We develop, for the first time, a language-conditioned prediction model directly from large-scale RGBD human video datasets. Our predicted flow offers actionable geometric and physics guidance, thus facilitating stable zero-shot skill transfer in real-world scenarios.We deploy our method with a policy based on closed-loop flow prediction. Remarkably, without any additional training, our method achieves an impressive 81% success rate in human-to-robot skill transfer, covering 18 tasks in 6 scenes. Our framework features the following benefits: (1) scalability: leveraging cross-embodiment data resources; (2) universality: multiple object categories, including rigid, articulated, and soft bodies; (3) stable skill transfer: providing actionable guidance with a small inference domain-gap. These lead to a new pathway towards scalable general robot learning. Data, code, and model weights will be made publicly available.
MLLM-Protector: Ensuring MLLM's Safety without Hurting Performance
Jan 17, 2024



The deployment of multimodal large language models (MLLMs) has brought forth a unique vulnerability: susceptibility to malicious attacks through visual inputs. We delve into the novel challenge of defending MLLMs against such attacks. We discovered that images act as a "foreign language" that is not considered during alignment, which can make MLLMs prone to producing harmful responses. Unfortunately, unlike the discrete tokens considered in text-based LLMs, the continuous nature of image signals presents significant alignment challenges, which poses difficulty to thoroughly cover the possible scenarios. This vulnerability is exacerbated by the fact that open-source MLLMs are predominantly fine-tuned on limited image-text pairs that is much less than the extensive text-based pretraining corpus, which makes the MLLMs more prone to catastrophic forgetting of their original abilities during explicit alignment tuning. To tackle these challenges, we introduce MLLM-Protector, a plug-and-play strategy combining a lightweight harm detector and a response detoxifier. The harm detector's role is to identify potentially harmful outputs from the MLLM, while the detoxifier corrects these outputs to ensure the response stipulates to the safety standards. This approach effectively mitigates the risks posed by malicious visual inputs without compromising the model's overall performance. Our results demonstrate that MLLM-Protector offers a robust solution to a previously unaddressed aspect of MLLM security.
Faster Sampling without Isoperimetry via Diffusion-based Monte Carlo
Jan 12, 2024



To sample from a general target distribution $p_*\propto e^{-f_*}$ beyond the isoperimetric condition, Huang et al. (2023) proposed to perform sampling through reverse diffusion, giving rise to Diffusion-based Monte Carlo (DMC). Specifically, DMC follows the reverse SDE of a diffusion process that transforms the target distribution to the standard Gaussian, utilizing a non-parametric score estimation. However, the original DMC algorithm encountered high gradient complexity, resulting in an exponential dependency on the error tolerance $\epsilon$ of the obtained samples. In this paper, we demonstrate that the high complexity of DMC originates from its redundant design of score estimation, and proposed a more efficient algorithm, called RS-DMC, based on a novel recursive score estimation method. In particular, we first divide the entire diffusion process into multiple segments and then formulate the score estimation step (at any time step) as a series of interconnected mean estimation and sampling subproblems accordingly, which are correlated in a recursive manner. Importantly, we show that with a proper design of the segment decomposition, all sampling subproblems will only need to tackle a strongly log-concave distribution, which can be very efficient to solve using the Langevin-based samplers with a provably rapid convergence rate. As a result, we prove that the gradient complexity of RS-DMC only has a quasi-polynomial dependency on $\epsilon$, which significantly improves exponential gradient complexity in Huang et al. (2023). Furthermore, under commonly used dissipative conditions, our algorithm is provably much faster than the popular Langevin-based algorithms. Our algorithm design and theoretical framework illuminate a novel direction for addressing sampling problems, which could be of broader applicability in the community.