 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Layerwise Perturbation: Unifying Off-Policy Corrections for LLM RL
Mar 19, 2026Off-policy problems such as policy staleness and training-inference mismatch, has become a major bottleneck for training stability and further exploration for LLM RL. To enhance inference efficiency, the distribution gap between the inference and updated policy grows, leading to heavy-tailed importance ratios. Heavy-tailed ratios arise when the policy is locally sharp, which further inflates sharp gradients and can push updates outside the trust region. To address this, we propose Adaptive Layerwise Perturbation(ALP) by injecting small learnable perturbations into input hidden states of each layer during updates, which is used as the numerator of the importance ratio against the unchanged inference policy in the objective. Intuitively, by adding controlled noise to intermediate representations, ALP prevents the updated policy from deviating too sharply from the inference policy, and enlarges the policy family to cover the inference policy family with mismatch noises. Hence, the flattened distribution can naturally tighten the updated and inference policy gap and reduce the tail of importance ratios, thus maintaining training stability. This is further validated empirically. Experiments on single-turn math and multi-turn tool-integrated reasoning tasks show that ALP not only improves final performance, but also avoid blow up of importance ratio tail and KL spikes during iterative training, along with boosted exploration. Ablations show that representation-level perturbations across all layers are most effective, substantially outperforming partial-layer and logits-only variants.
DA-Mamba: Learning Domain-Aware State Space Model for Global-Local Alignment in Domain Adaptive Object Detection
Mar 19, 2026Domain Adaptive Object Detection (DAOD) aims to transfer detectors from a labeled source domain to an unlabeled target domain. Existing DAOD methods employ multi-granularity feature alignment to learn domain-invariant representations. However, the local connectivity of their CNN-based backbone and detection head restricts alignment to local regions, failing to extract global domain-invariant features. Although transformer-based DAOD methods capture global dependencies via attention mechanisms, their quadratic computational cost hinders practical deployment. To solve this, we propose DA-Mamba, a hybrid CNN-State Space Models (SSMs) architecture that combines the efficiency of CNNs with the linear-time long-range modeling capability of State Space Models (SSMs) to capture both global and local domain-invariant features. Specifically, we introduce two novel modules: Image-Aware SSM (IA-SSM) and Object-Aware SSM (OA-SSM). IA-SSM is integrated into the backbone to enhance global domain awareness, enabling image-level global and local alignment. OA-SSM is inserted into the detection head to model spatial and semantic dependencies among objects, enhancing instance-level alignment. Comprehensive experiments demonstrate that the proposed method can efficiently improve the cross-domain performance of the object detector.
QiMeng: Fully Automated Hardware and Software Design for Processor Chip
Jun 05, 2025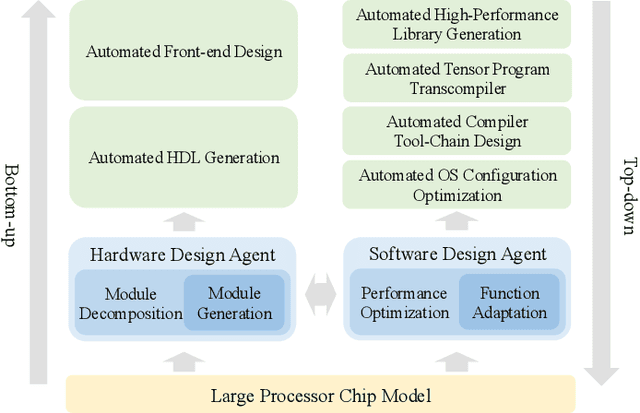
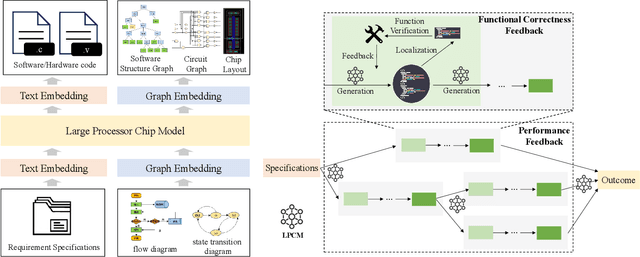
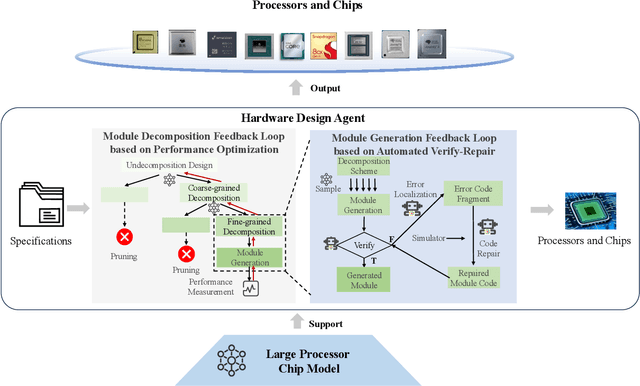
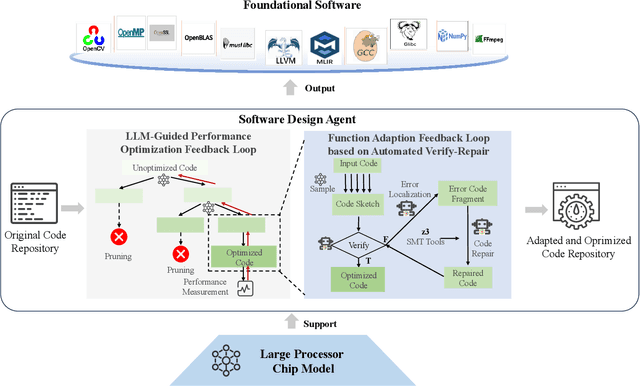
Processor chip design technology serves as a key frontier driving breakthroughs in computer science and related fields. With the rapid advancement of information technology, conventional design paradigms face three major challenges: the physical constraints of fabrication technologies, the escalating demands for design resources, and the increasing diversity of ecosystems. Automated processor chip design has emerged as a transformative solution to address these challenges. While recent breakthroughs in Artificial Intelligence (AI), particularly Large Language Models (LLMs) techniques, have opened new possibilities for fully automated processor chip design, substantial challenges remain in establishing domain-specific LLMs for processor chip design. In this paper, we propose QiMeng, a novel system for fully automated hardware and software design of processor chips. QiMeng comprises three hierarchical layers. In the bottom-layer, we construct a domain-specific Large Processor Chip Model (LPCM) that introduces novel designs in architecture, training, and inference, to address key challenges such as knowledge representation gap, data scarcity, correctness assurance, and enormous solution space. In the middle-layer, leveraging the LPCM's knowledge representation and inference capabilities, we develop the Hardware Design Agent and the Software Design Agent to automate the design of hardware and software for processor chips. Currently, several components of QiMeng have been completed and successfully applied in various top-layer applications, demonstrating significant advantages and providing a feasible solution for efficient, fully automated hardware/software design of processor chips. Future research will focus on integrating all components and performing iterative top-down and bottom-up design processes to establish a comprehensive QiMeng system.
Towards Better Generalization via Distributional Input Projection Network
Jun 05, 2025As overparameterized models become increasingly prevalent, training loss alone offers limited insight into generalization performance. While smoothness has been linked to improved generalization across various settings, directly enforcing smoothness in neural networks remains challenging. To address this, we introduce Distributional Input Projection Networks (DIPNet), a novel framework that projects inputs into learnable distributions at each layer. This distributional representation induces a smoother loss landscape with respect to the input, promoting better generalization. We provide theoretical analysis showing that DIPNet reduces both local smoothness measures and the Lipschitz constant of the network, contributing to improved generalization performance. Empirically, we validate DIPNet across a wide range of architectures and tasks, including Vision Transformers (ViTs), Large Language Models (LLMs), ResNet and MLPs. Our method consistently enhances test performance under standard settings, adversarial attacks, out-of-distribution inputs, and reasoning benchmarks. We demonstrate that the proposed input projection strategy can be seamlessly integrated into existing models, providing a general and effective approach for boosting generalization performance in modern deep learning.
Optimizing Chain-of-Thought Reasoners via Gradient Variance Minimization in Rejection Sampling and RL
May 05, 2025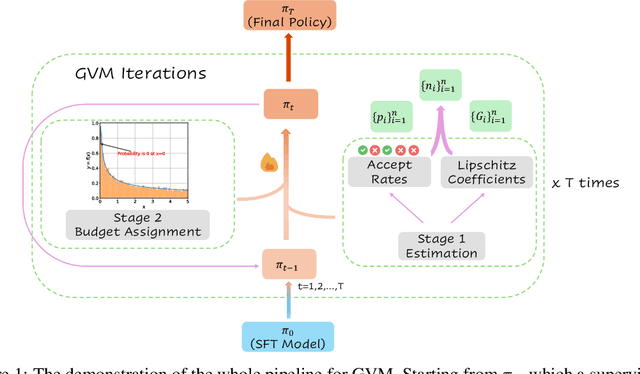
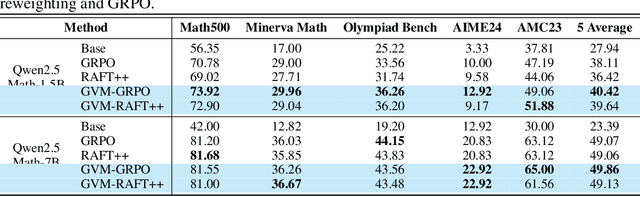
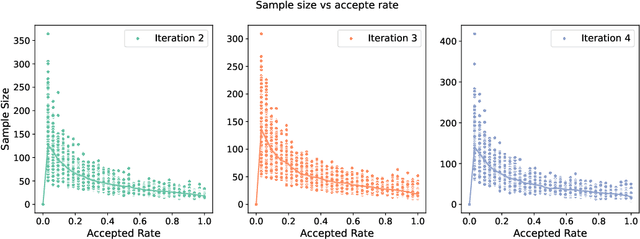
Chain-of-thought (CoT) reasoning in large language models (LLMs) can be formalized as a latent variable problem, where the model needs to generate intermediate reasoning steps. While prior approaches such as iterative reward-ranked fine-tuning (RAFT) have relied on such formulations, they typically apply uniform inference budgets across prompts, which fails to account for variability in difficulty and convergence behavior. This work identifies the main bottleneck in CoT training as inefficient stochastic gradient estimation due to static sampling strategies. We propose GVM-RAFT, a prompt-specific Dynamic Sample Allocation Strategy designed to minimize stochastic gradient variance under a computational budget constraint. The method dynamically allocates computational resources by monitoring prompt acceptance rates and stochastic gradient norms, ensuring that the resulting gradient variance is minimized. Our theoretical analysis shows that the proposed dynamic sampling strategy leads to accelerated convergence guarantees under suitable conditions. Experiments on mathematical reasoning show that GVM-RAFT achieves a 2-4x speedup and considerable accuracy improvements over vanilla RAFT. The proposed dynamic sampling strategy is general and can be incorporated into other reinforcement learning algorithms, such as GRPO, leading to similar improvements in convergence and test accuracy. Our code is available at https://github.com/RLHFlow/GVM.
QiMeng-Xpiler: Transcompiling Tensor Programs for Deep Learning Systems with a Neural-Symbolic Approach
May 04, 2025Heterogeneous deep learning systems (DLS) such as GPUs and ASICs have been widely deployed in industrial data centers, which requires to develop multiple low-level tensor programs for different platforms. An attractive solution to relieve the programming burden is to transcompile the legacy code of one platform to others. However, current transcompilation techniques struggle with either tremendous manual efforts or functional incorrectness, rendering "Write Once, Run Anywhere" of tensor programs an open question. We propose a novel transcompiler, i.e., QiMeng-Xpiler, for automatically translating tensor programs across DLS via both large language models (LLMs) and symbolic program synthesis, i.e., neural-symbolic synthesis. The key insight is leveraging the powerful code generation ability of LLM to make costly search-based symbolic synthesis computationally tractable. Concretely, we propose multiple LLM-assisted compilation passes via pre-defined meta-prompts for program transformation. During each program transformation, efficient symbolic program synthesis is employed to repair incorrect code snippets with a limited scale. To attain high performance, we propose a hierarchical auto-tuning approach to systematically explore both the parameters and sequences of transformation passes. Experiments on 4 DLS with distinct programming interfaces, i.e., Intel DL Boost with VNNI, NVIDIA GPU with CUDA, AMD MI with HIP, and Cambricon MLU with BANG, demonstrate that QiMeng-Xpiler correctly translates different tensor programs at the accuracy of 95% on average, and the performance of translated programs achieves up to 2.0x over vendor-provided manually-optimized libraries. As a result, the programming productivity of DLS is improved by up to 96.0x via transcompiling legacy tensor programs.
Object-Level Verbalized Confidence Calibration in Vision-Language Models via Semantic Perturbation
Apr 21, 2025



Vision-language models (VLMs) excel in various multimodal tasks but frequently suffer from poor calibration, resulting in misalignment between their verbalized confidence and response correctness. This miscalibration undermines user trust, especially when models confidently provide incorrect or fabricated information. In this work, we propose a novel Confidence Calibration through Semantic Perturbation (CSP) framework to improve the calibration of verbalized confidence for VLMs in response to object-centric queries. We first introduce a perturbed dataset where Gaussian noise is applied to the key object regions to simulate visual uncertainty at different confidence levels, establishing an explicit mapping between visual ambiguity and confidence levels. We further enhance calibration through a two-stage training process combining supervised fine-tuning on the perturbed dataset with subsequent preference optimization. Extensive experiments on popular benchmarks demonstrate that our method significantly improves the alignment between verbalized confidence and response correctness while maintaining or enhancing overall task performance. These results highlight the potential of semantic perturbation as a practical tool for improving the reliability and interpretability of VLMs.
Efficient Model Editing with Task Vector Bases: A Theoretical Framework and Scalable Approach
Feb 03, 2025



Task vectors, which are derived from the difference between pre-trained and fine-tuned model weights, enable flexible task adaptation and model merging through arithmetic operations such as addition and negation. However, existing approaches often rely on heuristics with limited theoretical support, often leading to performance gaps comparing to direct task fine tuning. Meanwhile, although it is easy to manipulate saved task vectors with arithmetic for different purposes, such compositional flexibility demands high memory usage, especially when dealing with a huge number of tasks, limiting scalability. This work addresses these issues with a theoretically grounded framework that explains task vector arithmetic and introduces the task vector bases framework. Building upon existing task arithmetic literature, our method significantly reduces the memory cost for downstream arithmetic with little effort, while achieving competitive performance and maintaining compositional advantage, providing a practical solution for large-scale task arithmetic.
DA-Ada: Learning Domain-Aware Adapter for Domain Adaptive Object Detection
Oct 11, 2024



Domain adaptive object detection (DAOD) aims to generalize detectors trained on an annotated source domain to an unlabelled target domain. As the visual-language models (VLMs) can provide essential general knowledge on unseen images, freezing the visual encoder and inserting a domain-agnostic adapter can learn domain-invariant knowledge for DAOD. However, the domain-agnostic adapter is inevitably biased to the source domain. It discards some beneficial knowledge discriminative on the unlabelled domain, i.e., domain-specific knowledge of the target domain. To solve the issue, we propose a novel Domain-Aware Adapter (DA-Ada) tailored for the DAOD task. The key point is exploiting domain-specific knowledge between the essential general knowledge and domain-invariant knowledge. DA-Ada consists of the Domain-Invariant Adapter (DIA) for learning domain-invariant knowledge and the Domain-Specific Adapter (DSA) for injecting the domain-specific knowledge from the information discarded by the visual encoder. Comprehensive experiments over multiple DAOD tasks show that DA-Ada can efficiently infer a domain-aware visual encoder for boosting domain adaptive object detection. Our code is available at https://github.com/Therock90421/DA-Ada.
SPDiffusion: Semantic Protection Diffusion for Multi-concept Text-to-image Generation
Sep 02, 2024



Recent text-to-image models have achieved remarkable success in generating high-quality images. However, when tasked with multi-concept generation which creates images containing multiple characters or objects, existing methods often suffer from attribute confusion, resulting in severe text-image inconsistency. We found that attribute confusion occurs when a certain region of the latent features attend to multiple or incorrect prompt tokens. In this work, we propose novel Semantic Protection Diffusion (SPDiffusion) to protect the semantics of regions from the influence of irrelevant tokens, eliminating the confusion of non-corresponding attributes. In the SPDiffusion framework, we design a Semantic Protection Mask (SP-Mask) to represent the relevance of the regions and the tokens, and propose a Semantic Protection Cross-Attention (SP-Attn) to shield the influence of irrelevant tokens on specific regions in the generation process. To evaluate our method, we created a diverse multi-concept benchmark, and SPDiffusion achieves state-of-the-art results on this benchmark, proving its effectiveness. Our method can be combined with many other application methods or backbones, such as ControlNet, Story Diffusion, PhotoMaker and PixArt-alpha to enhance their multi-concept capabilities, demonstrating strong compatibility and scalability.