 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvisioning global urban development with satellite imagery and generative AI
Mar 27, 2026Urban development has been a defining force in human history, shaping cities for centuries. However, past studies mostly analyze such development as predictive tasks, failing to reflect its generative nature. Therefore, this study designs a multimodal generative AI framework to envision sustainable urban development at a global scale. By integrating prompts and geospatial controls, our framework can generate high-fidelity, diverse, and realistic urban satellite imagery across the 500 largest metropolitan areas worldwide. It enables users to specify urban development goals, creating new images that align with them while offering diverse scenarios whose appearance can be controlled with text prompts and geospatial constraints. It also facilitates urban redevelopment practices by learning from the surrounding environment. Beyond visual synthesis, we find that it encodes and interprets latent representations of urban form for global cross-city learning, successfully transferring styles of urban environments across a global spatial network. The latent representations can also enhance downstream prediction tasks such as carbon emission prediction. Further, human expert evaluation confirms that our generated urban images are comparable to real urban images. Overall, this study presents innovative approaches for accelerated urban planning and supports scenario-based planning processes for worldwide cities.
Generative AI for Urban Design: A Stepwise Approach Integrating Human Expertise with Multimodal Diffusion Models
May 30, 2025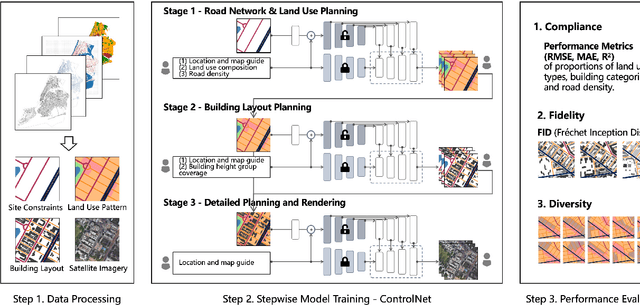
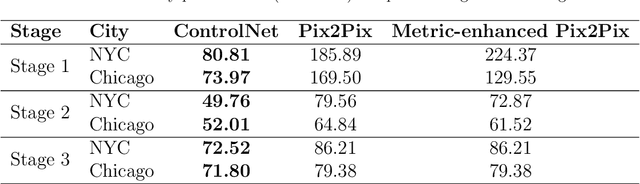
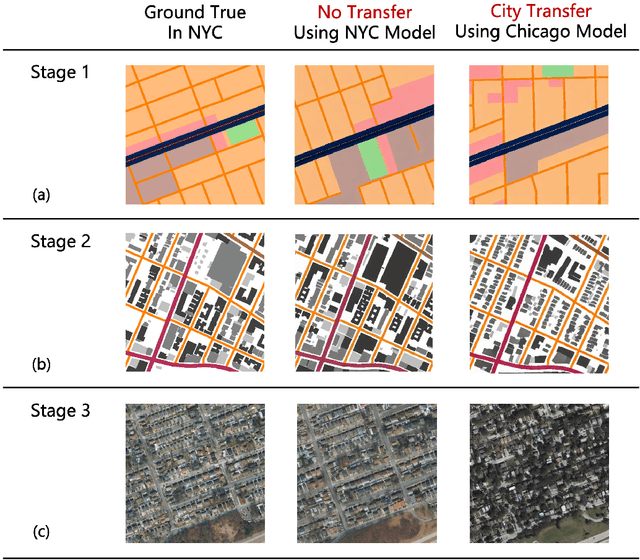
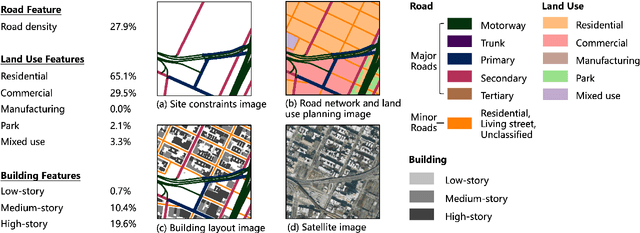
Urban design is a multifaceted process that demands careful consideration of site-specific constraints and collaboration among diverse professionals and stakeholders. The advent of generative artificial intelligence (GenAI) offers transformative potential by improving the efficiency of design generation and facilitating the communication of design ideas. However, most existing approaches are not well integrated with human design workflows. They often follow end-to-end pipelines with limited control, overlooking the iterative nature of real-world design. This study proposes a stepwise generative urban design framework that integrates multimodal diffusion models with human expertise to enable more adaptive and controllable design processes. Instead of generating design outcomes in a single end-to-end process, the framework divides the process into three key stages aligned with established urban design workflows: (1) road network and land use planning, (2) building layout planning, and (3) detailed planning and rendering. At each stage, multimodal diffusion models generate preliminary designs based on textual prompts and image-based constraints, which can then be reviewed and refined by human designers. We design an evaluation framework to assess the fidelity, compliance, and diversity of the generated designs. Experiments using data from Chicago and New York City demonstrate that our framework outperforms baseline models and end-to-end approaches across all three dimensions. This study underscores the benefits of multimodal diffusion models and stepwise generation in preserving human control and facilitating iterative refinements, laying the groundwork for human-AI interaction in urban design solutions.
LoFLAT: Local Feature Matching using Focused Linear Attention Transformer
Oct 30, 2024Local feature matching is an essential technique in image matching and plays a critical role in a wide range of vision-based applications. However, existing Transformer-based detector-free local feature matching methods encounter challenges due to the quadratic computational complexity of attention mechanisms, especially at high resolutions. However, while existing Transformer-based detector-free local feature matching methods have reduced computational costs using linear attention mechanisms, they still struggle to capture detailed local interactions, which affects the accuracy and robustness of precise local correspondences. In order to enhance representations of attention mechanisms while preserving low computational complexity, we propose the LoFLAT, a novel Local Feature matching using Focused Linear Attention Transformer in this paper. Our LoFLAT consists of three main modules: the Feature Extraction Module, the Feature Transformer Module, and the Matching Module. Specifically, the Feature Extraction Module firstly uses ResNet and a Feature Pyramid Network to extract hierarchical features. The Feature Transformer Module further employs the Focused Linear Attention to refine attention distribution with a focused mapping function and to enhance feature diversity with a depth-wise convolution. Finally, the Matching Module predicts accurate and robust matches through a coarse-to-fine strategy. Extensive experimental evaluations demonstrate that the proposed LoFLAT outperforms the LoFTR method in terms of both efficiency and accuracy.
Transferable Attack for Semantic Segmentation
Aug 21, 2023



We analysis performance of semantic segmentation models wrt. adversarial attacks, and observe that the adversarial examples generated from a source model fail to attack the target models. i.e The conventional attack methods, such as PGD and FGSM, do not transfer well to target models, making it necessary to study the transferable attacks, especially transferable attacks for semantic segmentation. We find two main factors to achieve transferable attack. Firstly, the attack should come with effective data augmentation and translation-invariant features to deal with unseen models. Secondly, stabilized optimization strategies are needed to find the optimal attack direction. Based on the above observations, we propose an ensemble attack for semantic segmentation to achieve more effective attacks with higher transferability. The source code and experimental results are publicly available via our project page: https://github.com/anucvers/TASS.
Joint Salient Object Detection and Camouflaged Object Detection via Uncertainty-aware Learning
Jul 10, 2023Salient objects attract human attention and usually stand out clearly from their surroundings. In contrast, camouflaged objects share similar colors or textures with the environment. In this case, salient objects are typically non-camouflaged, and camouflaged objects are usually not salient. Due to this inherent contradictory attribute, we introduce an uncertainty-aware learning pipeline to extensively explore the contradictory information of salient object detection (SOD) and camouflaged object detection (COD) via data-level and task-wise contradiction modeling. We first exploit the dataset correlation of these two tasks and claim that the easy samples in the COD dataset can serve as hard samples for SOD to improve the robustness of the SOD model. Based on the assumption that these two models should lead to activation maps highlighting different regions of the same input image, we further introduce a contrastive module with a joint-task contrastive learning framework to explicitly model the contradictory attributes of these two tasks. Different from conventional intra-task contrastive learning for unsupervised representation learning, our contrastive module is designed to model the task-wise correlation, leading to cross-task representation learning. To better understand the two tasks from the perspective of uncertainty, we extensively investigate the uncertainty estimation techniques for modeling the main uncertainties of the two tasks, namely task uncertainty (for SOD) and data uncertainty (for COD), and aiming to effectively estimate the challenging regions for each task to achieve difficulty-aware learning. Experimental results on benchmark datasets demonstrate that our solution leads to both state-of-the-art performance and informative uncertainty estimation.
A Revisit to the Normalized Eight-Point Algorithm and A Self-Supervised Deep Solution
Apr 21, 2023The Normalized Eight-Point algorithm has been widely viewed as the cornerstone in two-view geometry computation, where the seminal Hartley's normalization greatly improves the performance of the direct linear transformation (DLT) algorithm. A natural question is, whether there exists and how to find other normalization methods that may further improve the performance as per each input sample. In this paper, we provide a novel perspective and make two contributions towards this fundamental problem: 1) We revisit the normalized eight-point algorithm and make a theoretical contribution by showing the existence of different and better normalization algorithms; 2) We present a deep convolutional neural network with a self-supervised learning strategy to the normalization. Given eight pairs of correspondences, our network directly predicts the normalization matrices, thus learning to normalize each input sample. Our learning-based normalization module could be integrated with both traditional (e.g., RANSAC) and deep learning framework (affording good interpretability) with minimal efforts. Extensive experiments on both synthetic and real images show the effectiveness of our proposed approach.
Learning a Task-specific Descriptor for Robust Matching of 3D Point Clouds
Oct 26, 2022



Existing learning-based point feature descriptors are usually task-agnostic, which pursue describing the individual 3D point clouds as accurate as possible. However, the matching task aims at describing the corresponding points consistently across different 3D point clouds. Therefore these too accurate features may play a counterproductive role due to the inconsistent point feature representations of correspondences caused by the unpredictable noise, partiality, deformation, \etc, in the local geometry. In this paper, we propose to learn a robust task-specific feature descriptor to consistently describe the correct point correspondence under interference. Born with an Encoder and a Dynamic Fusion module, our method EDFNet develops from two aspects. First, we augment the matchability of correspondences by utilizing their repetitive local structure. To this end, a special encoder is designed to exploit two input point clouds jointly for each point descriptor. It not only captures the local geometry of each point in the current point cloud by convolution, but also exploits the repetitive structure from paired point cloud by Transformer. Second, we propose a dynamical fusion module to jointly use different scale features. There is an inevitable struggle between robustness and discriminativeness of the single scale feature. Specifically, the small scale feature is robust since little interference exists in this small receptive field. But it is not sufficiently discriminative as there are many repetitive local structures within a point cloud. Thus the resultant descriptors will lead to many incorrect matches. In contrast, the large scale feature is more discriminative by integrating more neighborhood information. ...
Context-Aware Video Reconstruction for Rolling Shutter Cameras
May 25, 2022
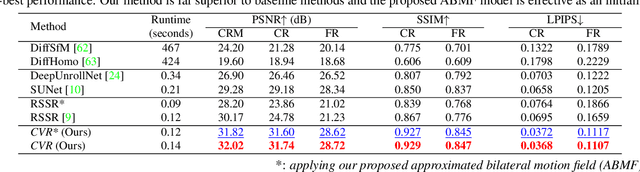
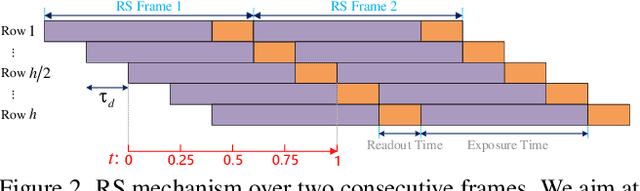
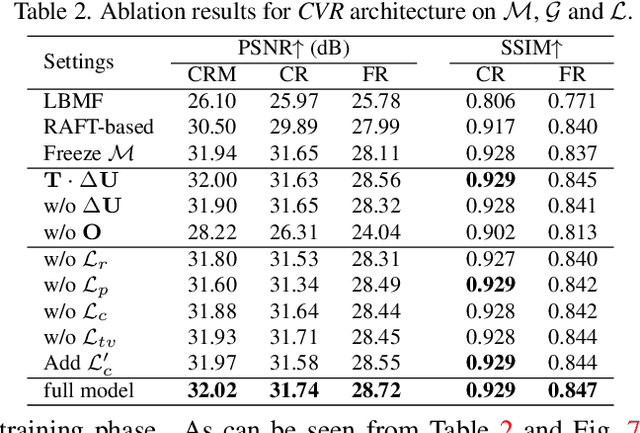
With the ubiquity of rolling shutter (RS) cameras, it is becoming increasingly attractive to recover the latent global shutter (GS) video from two consecutive RS frames, which also places a higher demand on realism. Existing solutions, using deep neural networks or optimization, achieve promising performance. However, these methods generate intermediate GS frames through image warping based on the RS model, which inevitably result in black holes and noticeable motion artifacts. In this paper, we alleviate these issues by proposing a context-aware GS video reconstruction architecture. It facilitates the advantages such as occlusion reasoning, motion compensation, and temporal abstraction. Specifically, we first estimate the bilateral motion field so that the pixels of the two RS frames are warped to a common GS frame accordingly. Then, a refinement scheme is proposed to guide the GS frame synthesis along with bilateral occlusion masks to produce high-fidelity GS video frames at arbitrary times. Furthermore, we derive an approximated bilateral motion field model, which can serve as an alternative to provide a simple but effective GS frame initialization for related tasks. Experiments on synthetic and real data show that our approach achieves superior performance over state-of-the-art methods in terms of objective metrics and subjective visual quality. Code is available at \url{https://github.com/GitCVfb/CVR}.
VRNet: Learning the Rectified Virtual Corresponding Points for 3D Point Cloud Registration
Mar 24, 2022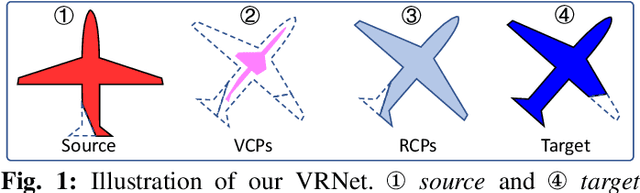
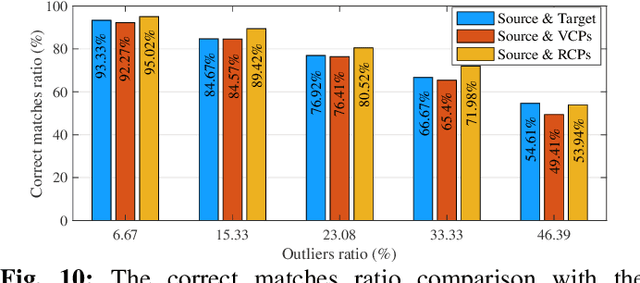

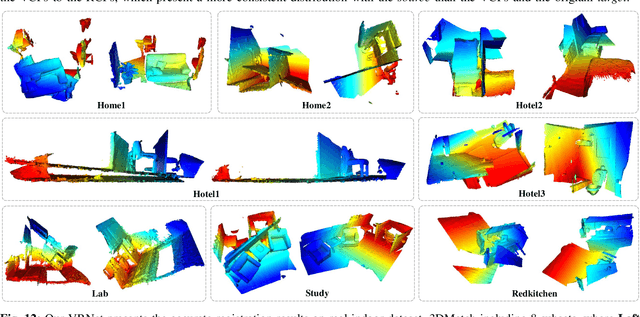
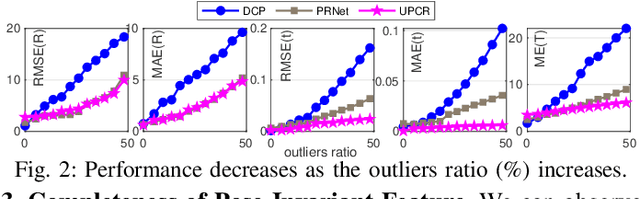
3D point cloud registration is fragile to outliers, which are labeled as the points without corresponding points. To handle this problem, a widely adopted strategy is to estimate the relative pose based only on some accurate correspondences, which is achieved by building correspondences on the identified inliers or by selecting reliable ones. However, these approaches are usually complicated and time-consuming. By contrast, the virtual point-based methods learn the virtual corresponding points (VCPs) for all source points uniformly without distinguishing the outliers and the inliers. Although this strategy is time-efficient, the learned VCPs usually exhibit serious collapse degeneration due to insufficient supervision and the inherent distribution limitation. In this paper, we propose to exploit the best of both worlds and present a novel robust 3D point cloud registration framework. We follow the idea of the virtual point-based methods but learn a new type of virtual points called rectified virtual corresponding points (RCPs), which are defined as the point set with the same shape as the source and with the same pose as the target. Hence, a pair of consistent point clouds, i.e. source and RCPs, is formed by rectifying VCPs to RCPs (VRNet), through which reliable correspondences between source and RCPs can be accurately obtained. Since the relative pose between source and RCPs is the same as the relative pose between source and target, the input point clouds can be registered naturally. Specifically, we first construct the initial VCPs by using an estimated soft matching matrix to perform a weighted average on the target points. Then, we design a correction-walk module to learn an offset to rectify VCPs to RCPs, which effectively breaks the distribution limitation of VCPs. Finally, we develop a hybrid loss function to enforce the shape and geometry structure consistency ...
A Representation Separation Perspective to Correspondences-free Unsupervised 3D Point Cloud Registration
Mar 24, 2022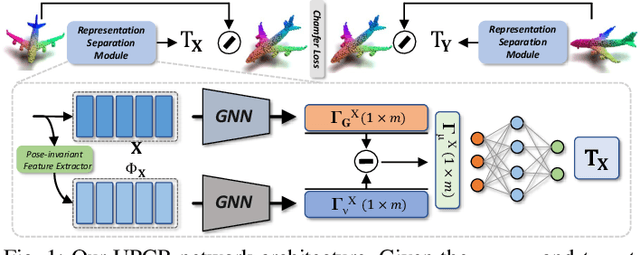
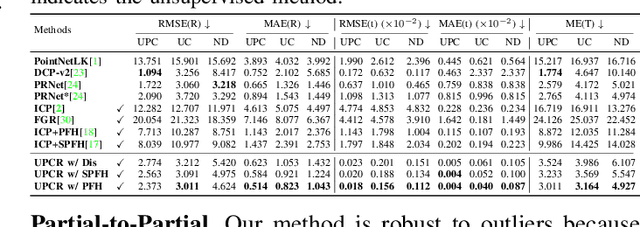
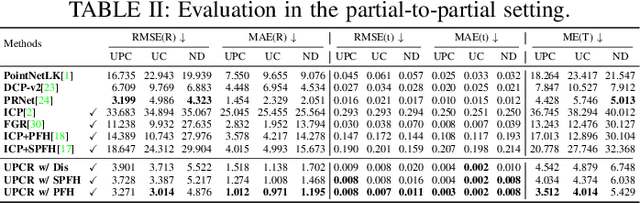
3D point cloud registration in remote sensing field has been greatly advanced by deep learning based methods, where the rigid transformation is either directly regressed from the two point clouds (correspondences-free approaches) or computed from the learned correspondences (correspondences-based approaches). Existing correspondences-free methods generally learn the holistic representation of the entire point cloud, which is fragile for partial and noisy point clouds. In this paper, we propose a correspondences-free unsupervised point cloud registration (UPCR) method from the representation separation perspective. First, we model the input point cloud as a combination of pose-invariant representation and pose-related representation. Second, the pose-related representation is used to learn the relative pose wrt a "latent canonical shape" for the source and target point clouds respectively. Third, the rigid transformation is obtained from the above two learned relative poses. Our method not only filters out the disturbance in pose-invariant representation but also is robust to partial-to-partial point clouds or noise. Experiments on benchmark datasets demonstrate that our unsupervised method achieves comparable if not better performance than state-of-the-art supervised registration methods.