 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUI Agents: A Survey
Dec 18, 2024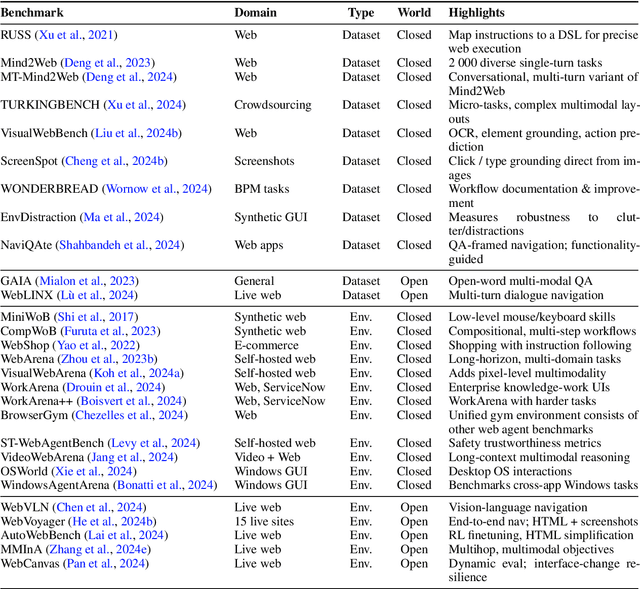
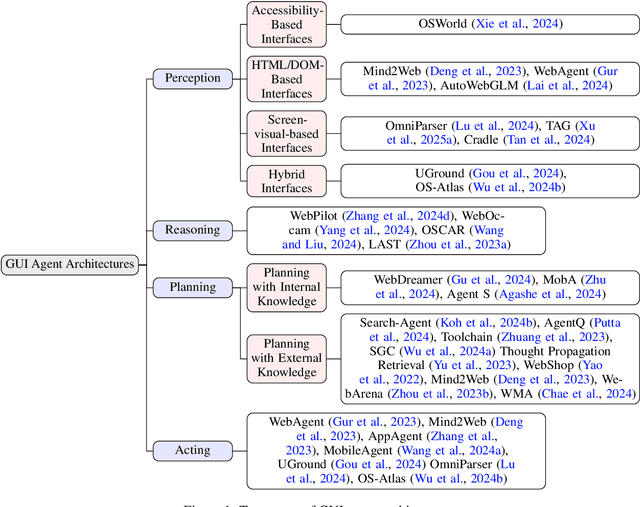

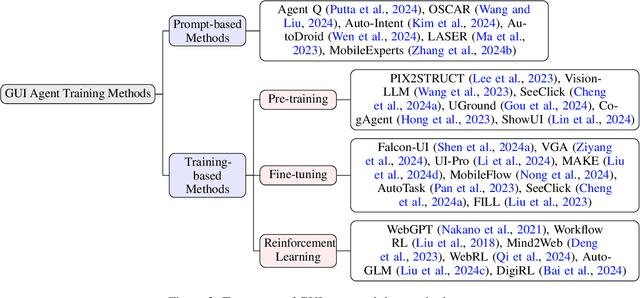
Graphical User Interface (GUI) agents, powered by Large Foundation Models, have emerged as a transformative approach to automating human-computer interaction. These agents autonomously interact with digital systems or software applications via GUIs, emulating human actions such as clicking, typing, and navigating visual elements across diverse platforms. Motivated by the growing interest and fundamental importance of GUI agents, we provide a comprehensive survey that categorizes their benchmarks, evaluation metrics, architectures, and training methods. We propose a unified framework that delineates their perception, reasoning, planning, and acting capabilities. Furthermore, we identify important open challenges and discuss key future directions. Finally, this work serves as a basis for practitioners and researchers to gain an intuitive understanding of current progress, techniques, benchmarks, and critical open problems that remain to be addressed.
Numerical Pruning for Efficient Autoregressive Models
Dec 17, 2024



Transformers have emerged as the leading architecture in deep learning, proving to be versatile and highly effective across diverse domains beyond language and image processing. However, their impressive performance often incurs high computational costs due to their substantial model size. This paper focuses on compressing decoder-only transformer-based autoregressive models through structural weight pruning to improve the model efficiency while preserving performance for both language and image generation tasks. Specifically, we propose a training-free pruning method that calculates a numerical score with Newton's method for the Attention and MLP modules, respectively. Besides, we further propose another compensation algorithm to recover the pruned model for better performance. To verify the effectiveness of our method, we provide both theoretical support and extensive experiments. Our experiments show that our method achieves state-of-the-art performance with reduced memory usage and faster generation speeds on GPUs.
Personalized Multimodal Large Language Models: A Survey
Dec 03, 2024Multimodal Large Language Models (MLLMs) have become increasingly important due to their state-of-the-art performance and ability to integrate multiple data modalities, such as text, images, and audio, to perform complex tasks with high accuracy. This paper presents a comprehensive survey on personalized multimodal large language models, focusing on their architecture, training methods, and applications. We propose an intuitive taxonomy for categorizing the techniques used to personalize MLLMs to individual users, and discuss the techniques accordingly. Furthermore, we discuss how such techniques can be combined or adapted when appropriate, highlighting their advantages and underlying rationale. We also provide a succinct summary of personalization tasks investigated in existing research, along with the evaluation metrics commonly used. Additionally, we summarize the datasets that are useful for benchmarking personalized MLLMs. Finally, we outline critical open challenges. This survey aims to serve as a valuable resource for researchers and practitioners seeking to understand and advance the development of personalized multimodal large language models.
Optimizing Data Delivery: Insights from User Preferences on Visuals, Tables, and Text
Nov 12, 2024In this work, we research user preferences to see a chart, table, or text given a question asked by the user. This enables us to understand when it is best to show a chart, table, or text to the user for the specific question. For this, we conduct a user study where users are shown a question and asked what they would prefer to see and used the data to establish that a user's personal traits does influence the data outputs that they prefer. Understanding how user characteristics impact a user's preferences is critical to creating data tools with a better user experience. Additionally, we investigate to what degree an LLM can be used to replicate a user's preference with and without user preference data. Overall, these findings have significant implications pertaining to the development of data tools and the replication of human preferences using LLMs. Furthermore, this work demonstrates the potential use of LLMs to replicate user preference data which has major implications for future user modeling and personalization research.
CodeLutra: Boosting LLM Code Generation via Preference-Guided Refinement
Nov 07, 2024



Large Language Models (LLMs) have significantly advanced code generation but often require substantial resources and tend to over-generalize, limiting their efficiency for specific tasks. Fine-tuning smaller, open-source LLMs presents a viable alternative; however, it typically lags behind cutting-edge models due to supervised fine-tuning's reliance solely on correct code examples, which restricts the model's ability to learn from its own mistakes and adapt to diverse programming challenges. To bridge this gap, we introduce CodeLutra, a novel framework that enhances low-performing LLMs by leveraging both successful and failed code generation attempts. Unlike conventional fine-tuning, CodeLutra employs an iterative preference learning mechanism to compare correct and incorrect solutions as well as maximize the likelihood of correct codes. Through continuous iterative refinement, CodeLutra enables smaller LLMs to match or surpass GPT-4's performance in various code generation tasks without relying on vast external datasets or larger auxiliary models. On a challenging data analysis task, using just 500 samples improved Llama-3-8B's accuracy from 28.2% to 48.6%, approaching GPT-4's performance. These results highlight CodeLutra's potential to close the gap between open-source and closed-source models, making it a promising approach in the field of code generation.
LoRA-Contextualizing Adaptation of Large Multimodal Models for Long Document Understanding
Nov 02, 2024Large multimodal models (LMMs) have recently shown great progress in text-rich image understanding, yet they still struggle with complex, multi-page, visually-rich documents. Traditional methods using document parsers for retrieval-augmented generation suffer from performance and efficiency limitations, while directly presenting all pages to LMMs leads to inefficiencies, especially with lengthy documents. In this work, we present a novel framework named LoRA-Contextualizing Adaptation of Large multimodal models (LoCAL), which broadens the capabilities of any LMM to support long-document understanding. We demonstrate that LMMs can effectively serve as multimodal retrievers, fetching relevant pages to answer user questions based on these pages. LoCAL is implemented with two specific LMM adapters: one for evidence page retrieval and another for question answering. Empirical results show state-of-the-art performance on public benchmarks, demonstrating the effectiveness of LoCAL.
OCEAN: Offline Chain-of-thought Evaluation and Alignment in Large Language Models
Oct 31, 2024



Offline evaluation of LLMs is crucial in understanding their capacities, though current methods remain underexplored in existing research. In this work, we focus on the offline evaluation of the chain-of-thought capabilities and show how to optimize LLMs based on the proposed evaluation method. To enable offline feedback with rich knowledge and reasoning paths, we use knowledge graphs (e.g., Wikidata5m) to provide feedback on the generated chain of thoughts. Due to the heterogeneity between LLM reasoning and KG structures, direct interaction and feedback from KGs on LLM behavior are challenging, as they require accurate entity linking and grounding of LLM-generated chains of thought in the KG. To address the above challenge, we propose an offline chain-of-thought evaluation framework, OCEAN, which models chain-of-thought reasoning in LLMs as an MDP and evaluate the policy's alignment with KG preference modeling. To overcome the reasoning heterogeneity and grounding problems, we leverage on-policy KG exploration and RL to model a KG policy that generates token-level likelihood distributions for LLM-generated chain-of-thought reasoning paths, simulating KG reasoning preference. Then we incorporate the knowledge-graph feedback on the validity and alignment of the generated reasoning paths into inverse propensity scores and propose KG-IPS estimator. Theoretically, we prove the unbiasedness of the proposed KG-IPS estimator and provide a lower bound on its variance. With the off-policy evaluated value function, we can directly enable off-policy optimization to further enhance chain-of-thought alignment. Our empirical study shows that OCEAN can be efficiently optimized for generating chain-of-thought reasoning paths with higher estimated values without affecting LLMs' general abilities in downstream tasks or their internal knowledge.
Personalization of Large Language Models: A Survey
Oct 29, 2024Personalization of Large Language Models (LLMs) has recently become increasingly important with a wide range of applications. Despite the importance and recent progress, most existing works on personalized LLMs have focused either entirely on (a) personalized text generation or (b) leveraging LLMs for personalization-related downstream applications, such as recommendation systems. In this work, we bridge the gap between these two separate main directions for the first time by introducing a taxonomy for personalized LLM usage and summarizing the key differences and challenges. We provide a formalization of the foundations of personalized LLMs that consolidates and expands notions of personalization of LLMs, defining and discussing novel facets of personalization, usage, and desiderata of personalized LLMs. We then unify the literature across these diverse fields and usage scenarios by proposing systematic taxonomies for the granularity of personalization, personalization techniques, datasets, evaluation methods, and applications of personalized LLMs. Finally, we highlight challenges and important open problems that remain to be addressed. By unifying and surveying recent research using the proposed taxonomies, we aim to provide a clear guide to the existing literature and different facets of personalization in LLMs, empowering both researchers and practitioners.
Survey of User Interface Design and Interaction Techniques in Generative AI Applications
Oct 28, 2024



The applications of generative AI have become extremely impressive, and the interplay between users and AI is even more so. Current human-AI interaction literature has taken a broad look at how humans interact with generative AI, but it lacks specificity regarding the user interface designs and patterns used to create these applications. Therefore, we present a survey that comprehensively presents taxonomies of how a human interacts with AI and the user interaction patterns designed to meet the needs of a variety of relevant use cases. We focus primarily on user-guided interactions, surveying interactions that are initiated by the user and do not include any implicit signals given by the user. With this survey, we aim to create a compendium of different user-interaction patterns that can be used as a reference for designers and developers alike. In doing so, we also strive to lower the entry barrier for those attempting to learn more about the design of generative AI applications.
A Survey of Small Language Models
Oct 25, 2024


Small Language Models (SLMs) have become increasingly important due to their efficiency and performance to perform various language tasks with minimal computational resources, making them ideal for various settings including on-device, mobile, edge devices, among many others. In this article, we present a comprehensive survey on SLMs, focusing on their architectures, training techniques, and model compression techniques. We propose a novel taxonomy for categorizing the methods used to optimize SLMs, including model compression, pruning, and quantization techniques. We summarize the benchmark datasets that are useful for benchmarking SLMs along with the evaluation metrics commonly used. Additionally, we highlight key open challenges that remain to be addressed. Our survey aims to serve as a valuable resource for researchers and practitioners interested in developing and deploying small yet efficient language models.