 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Semantic Caching for Low-Cost LLM Serving
Apr 21, 2026As Large Language Models (LLMs) become increasingly popular, caching responses so that they can be reused by users with semantically similar queries has become a vital strategy for reducing inference costs and latency. Existing caching frameworks have proposed to decide which query responses to cache by assuming a finite, known universe of discrete queries and learning their serving costs and arrival probabilities. As LLMs' pool of users and queries expands, however, such an assumption becomes increasingly untenable: real-world LLM queries reside in an infinite, continuous embedding space. In this paper, we establish the first rigorous theoretical framework for semantic LLM response caching in continuous query space under uncertainty. To bridge the gap between discrete optimization and continuous representation spaces, we introduce dynamic $ε$-net discretization coupled with Kernel Ridge Regression. This design enables the system to formally quantify estimation uncertainty and generalize partial feedback on LLM query costs across continuous semantic query neighborhoods. We develop both offline learning and online adaptive algorithms optimized to reduce switching costs incurred by changing the cached responses. We prove that our online algorithm achieves a sublinear regret bound against an optimal continuous oracle, which reduces to existing bounds for discrete query models. Extensive empirical evaluations demonstrate that our framework approximates the continuous optimal cache well while also reducing computational and switching overhead compared to existing methods.
Semantic Caching for Low-Cost LLM Serving: From Offline Learning to Online Adaptation
Aug 12, 2025Large Language Models (LLMs) are revolutionizing how users interact with information systems, yet their high inference cost poses serious scalability and sustainability challenges. Caching inference responses, allowing them to be retrieved without another forward pass through the LLM, has emerged as one possible solution. Traditional exact-match caching, however, overlooks the semantic similarity between queries, leading to unnecessary recomputation. Semantic caching addresses this by retrieving responses based on semantic similarity, but introduces a fundamentally different cache eviction problem: one must account for mismatch costs between incoming queries and cached responses. Moreover, key system parameters, such as query arrival probabilities and serving costs, are often unknown and must be learned over time. Existing semantic caching methods are largely ad-hoc, lacking theoretical foundations and unable to adapt to real-world uncertainty. In this paper, we present a principled, learning-based framework for semantic cache eviction under unknown query and cost distributions. We formulate both offline optimization and online learning variants of the problem, and develop provably efficient algorithms with state-of-the-art guarantees. We also evaluate our framework on a synthetic dataset, showing that our proposed algorithms perform matching or superior performance compared with baselines.
A Unified Online-Offline Framework for Co-Branding Campaign Recommendations
May 28, 2025
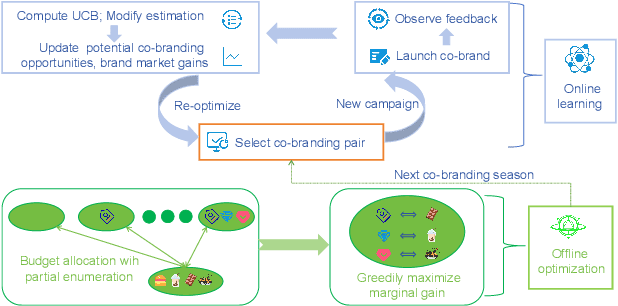


Co-branding has become a vital strategy for businesses aiming to expand market reach within recommendation systems. However, identifying effective cross-industry partnerships remains challenging due to resource imbalances, uncertain brand willingness, and ever-changing market conditions. In this paper, we provide the first systematic study of this problem and propose a unified online-offline framework to enable co-branding recommendations. Our approach begins by constructing a bipartite graph linking ``initiating'' and ``target'' brands to quantify co-branding probabilities and assess market benefits. During the online learning phase, we dynamically update the graph in response to market feedback, while striking a balance between exploring new collaborations for long-term gains and exploiting established partnerships for immediate benefits. To address the high initial co-branding costs, our framework mitigates redundant exploration, thereby enhancing short-term performance while ensuring sustainable strategic growth. In the offline optimization phase, our framework consolidates the interests of multiple sub-brands under the same parent brand to maximize overall returns, avoid excessive investment in single sub-brands, and reduce unnecessary costs associated with over-prioritizing a single sub-brand. We present a theoretical analysis of our approach, establishing a highly nontrivial sublinear regret bound for online learning in the complex co-branding problem, and enhancing the approximation guarantee for the NP-hard offline budget allocation optimization. Experiments on both synthetic and real-world co-branding datasets demonstrate the practical effectiveness of our framework, with at least 12\% improvement.
Practical Adversarial Attacks on Stochastic Bandits via Fake Data Injection
May 28, 2025Adversarial attacks on stochastic bandits have traditionally relied on some unrealistic assumptions, such as per-round reward manipulation and unbounded perturbations, limiting their relevance to real-world systems. We propose a more practical threat model, Fake Data Injection, which reflects realistic adversarial constraints: the attacker can inject only a limited number of bounded fake feedback samples into the learner's history, simulating legitimate interactions. We design efficient attack strategies under this model, explicitly addressing both magnitude constraints (on reward values) and temporal constraints (on when and how often data can be injected). Our theoretical analysis shows that these attacks can mislead both Upper Confidence Bound (UCB) and Thompson Sampling algorithms into selecting a target arm in nearly all rounds while incurring only sublinear attack cost. Experiments on synthetic and real-world datasets validate the effectiveness of our strategies, revealing significant vulnerabilities in widely used stochastic bandit algorithms under practical adversarial scenarios.
Fusing Reward and Dueling Feedback in Stochastic Bandits
Apr 22, 2025This paper investigates the fusion of absolute (reward) and relative (dueling) feedback in stochastic bandits, where both feedback types are gathered in each decision round. We derive a regret lower bound, demonstrating that an efficient algorithm may incur only the smaller among the reward and dueling-based regret for each individual arm. We propose two fusion approaches: (1) a simple elimination fusion algorithm that leverages both feedback types to explore all arms and unifies collected information by sharing a common candidate arm set, and (2) a decomposition fusion algorithm that selects the more effective feedback to explore the corresponding arms and randomly assigns one feedback type for exploration and the other for exploitation in each round. The elimination fusion experiences a suboptimal multiplicative term of the number of arms in regret due to the intrinsic suboptimality of dueling elimination. In contrast, the decomposition fusion achieves regret matching the lower bound up to a constant under a common assumption. Extensive experiments confirm the efficacy of our algorithms and theoretical results.
Tin-Tin: Towards Tiny Learning on Tiny Devices with Integer-based Neural Network Training
Apr 13, 2025Recent advancements in machine learning (ML) have enabled its deployment on resource-constrained edge devices, fostering innovative applications such as intelligent environmental sensing. However, these devices, particularly microcontrollers (MCUs), face substantial challenges due to limited memory, computing capabilities, and the absence of dedicated floating-point units (FPUs). These constraints hinder the deployment of complex ML models, especially those requiring lifelong learning capabilities. To address these challenges, we propose Tin-Tin, an integer-based on-device training framework designed specifically for low-power MCUs. Tin-Tin introduces novel integer rescaling techniques to efficiently manage dynamic ranges and facilitate efficient weight updates using integer data types. Unlike existing methods optimized for devices with FPUs, GPUs, or FPGAs, Tin-Tin addresses the unique demands of tiny MCUs, prioritizing energy efficiency and optimized memory utilization. We validate the effectiveness of Tin-Tin through end-to-end application examples on real-world tiny devices, demonstrating its potential to support energy-efficient and sustainable ML applications on edge platforms.
Heterogeneous Multi-Agent Bandits with Parsimonious Hints
Feb 22, 2025



We study a hinted heterogeneous multi-agent multi-armed bandits problem (HMA2B), where agents can query low-cost observations (hints) in addition to pulling arms. In this framework, each of the $M$ agents has a unique reward distribution over $K$ arms, and in $T$ rounds, they can observe the reward of the arm they pull only if no other agent pulls that arm. The goal is to maximize the total utility by querying the minimal necessary hints without pulling arms, achieving time-independent regret. We study HMA2B in both centralized and decentralized setups. Our main centralized algorithm, GP-HCLA, which is an extension of HCLA, uses a central decision-maker for arm-pulling and hint queries, achieving $O(M^4K)$ regret with $O(MK\log T)$ adaptive hints. In decentralized setups, we propose two algorithms, HD-ETC and EBHD-ETC, that allow agents to choose actions independently through collision-based communication and query hints uniformly until stopping, yielding $O(M^3K^2)$ regret with $O(M^3K\log T)$ hints, where the former requires knowledge of the minimum gap and the latter does not. Finally, we establish lower bounds to prove the optimality of our results and verify them through numerical simulations.
Offline Learning for Combinatorial Multi-armed Bandits
Jan 31, 2025



The combinatorial multi-armed bandit (CMAB) is a fundamental sequential decision-making framework, extensively studied over the past decade. However, existing work primarily focuses on the online setting, overlooking the substantial costs of online interactions and the readily available offline datasets. To overcome these limitations, we introduce Off-CMAB, the first offline learning framework for CMAB. Central to our framework is the combinatorial lower confidence bound (CLCB) algorithm, which combines pessimistic reward estimations with combinatorial solvers. To characterize the quality of offline datasets, we propose two novel data coverage conditions and prove that, under these conditions, CLCB achieves a near-optimal suboptimality gap, matching the theoretical lower bound up to a logarithmic factor. We validate Off-CMAB through practical applications, including learning to rank, large language model (LLM) caching, and social influence maximization, showing its ability to handle nonlinear reward functions, general feedback models, and out-of-distribution action samples that excludes optimal or even feasible actions. Extensive experiments on synthetic and real-world datasets further highlight the superior performance of CLCB.
Multi-Agent Stochastic Bandits Robust to Adversarial Corruptions
Nov 12, 2024We study the problem of multi-agent multi-armed bandits with adversarial corruption in a heterogeneous setting, where each agent accesses a subset of arms. The adversary can corrupt the reward observations for all agents. Agents share these corrupted rewards with each other, and the objective is to maximize the cumulative total reward of all agents (and not be misled by the adversary). We propose a multi-agent cooperative learning algorithm that is robust to adversarial corruptions. For this newly devised algorithm, we demonstrate that an adversary with an unknown corruption budget $C$ only incurs an additive $O((L / L_{\min}) C)$ term to the standard regret of the model in non-corruption settings, where $L$ is the total number of agents, and $L_{\min}$ is the minimum number of agents with mutual access to an arm. As a side-product, our algorithm also improves the state-of-the-art regret bounds when reducing to both the single-agent and homogeneous multi-agent scenarios, tightening multiplicative $K$ (the number of arms) and $L$ (the number of agents) factors, respectively.
Combinatorial Multivariant Multi-Armed Bandits with Applications to Episodic Reinforcement Learning and Beyond
Jun 03, 2024We introduce a novel framework of combinatorial multi-armed bandits (CMAB) with multivariant and probabilistically triggering arms (CMAB-MT), where the outcome of each arm is a $d$-dimensional multivariant random variable and the feedback follows a general arm triggering process. Compared with existing CMAB works, CMAB-MT not only enhances the modeling power but also allows improved results by leveraging distinct statistical properties for multivariant random variables. For CMAB-MT, we propose a general 1-norm multivariant and triggering probability-modulated smoothness condition, and an optimistic CUCB-MT algorithm built upon this condition. Our framework can include many important problems as applications, such as episodic reinforcement learning (RL) and probabilistic maximum coverage for goods distribution, all of which meet the above smoothness condition and achieve matching or improved regret bounds compared to existing works. Through our new framework, we build the first connection between the episodic RL and CMAB literature, by offering a new angle to solve the episodic RL through the lens of CMAB, which may encourage more interactions between these two important directions.