 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges in Multi-centric Generalization: Phase and Step Recognition in Roux-en-Y Gastric Bypass Surgery
Dec 18, 2023Most studies on surgical activity recognition utilizing Artificial intelligence (AI) have focused mainly on recognizing one type of activity from small and mono-centric surgical video datasets. It remains speculative whether those models would generalize to other centers. In this work, we introduce a large multi-centric multi-activity dataset consisting of 140 videos (MultiBypass140) of laparoscopic Roux-en-Y gastric bypass (LRYGB) surgeries performed at two medical centers: the University Hospital of Strasbourg (StrasBypass70) and Inselspital, Bern University Hospital (BernBypass70). The dataset has been fully annotated with phases and steps. Furthermore, we assess the generalizability and benchmark different deep learning models in 7 experimental studies: 1) Training and evaluation on BernBypass70; 2) Training and evaluation on StrasBypass70; 3) Training and evaluation on the MultiBypass140; 4) Training on BernBypass70, evaluation on StrasBypass70; 5) Training on StrasBypass70, evaluation on BernBypass70; Training on MultiBypass140, evaluation 6) on BernBypass70 and 7) on StrasBypass70. The model's performance is markedly influenced by the training data. The worst results were obtained in experiments 4) and 5) confirming the limited generalization capabilities of models trained on mono-centric data. The use of multi-centric training data, experiments 6) and 7), improves the generalization capabilities of the models, bringing them beyond the level of independent mono-centric training and validation (experiments 1) and 2)). MultiBypass140 shows considerable variation in surgical technique and workflow of LRYGB procedures between centers. Therefore, generalization experiments demonstrate a remarkable difference in model performance. These results highlight the importance of multi-centric datasets for AI model generalization to account for variance in surgical technique and workflows.
Weakly Supervised Temporal Convolutional Networks for Fine-grained Surgical Activity Recognition
Feb 21, 2023



Automatic recognition of fine-grained surgical activities, called steps, is a challenging but crucial task for intelligent intra-operative computer assistance. The development of current vision-based activity recognition methods relies heavily on a high volume of manually annotated data. This data is difficult and time-consuming to generate and requires domain-specific knowledge. In this work, we propose to use coarser and easier-to-annotate activity labels, namely phases, as weak supervision to learn step recognition with fewer step annotated videos. We introduce a step-phase dependency loss to exploit the weak supervision signal. We then employ a Single-Stage Temporal Convolutional Network (SS-TCN) with a ResNet-50 backbone, trained in an end-to-end fashion from weakly annotated videos, for temporal activity segmentation and recognition. We extensively evaluate and show the effectiveness of the proposed method on a large video dataset consisting of 40 laparoscopic gastric bypass procedures and the public benchmark CATARACTS containing 50 cataract surgeries.
Dissecting Self-Supervised Learning Methods for Surgical Computer Vision
Jul 01, 2022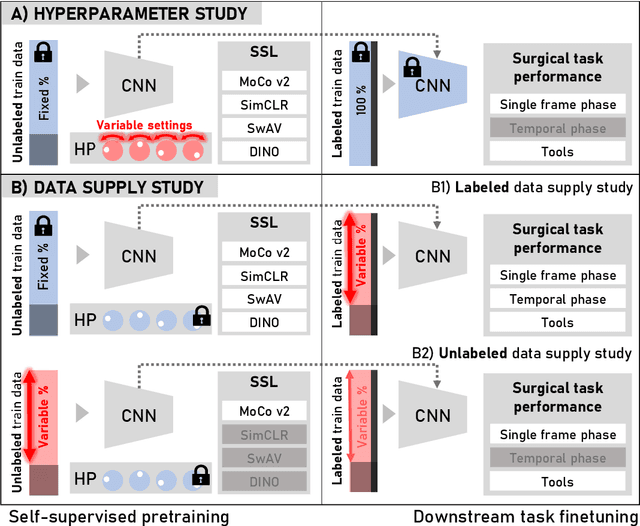
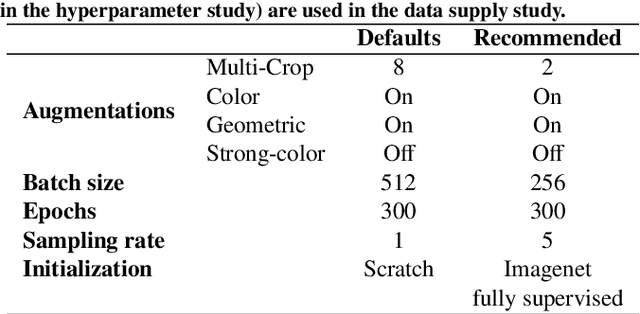
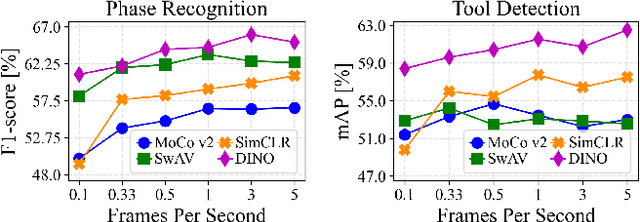
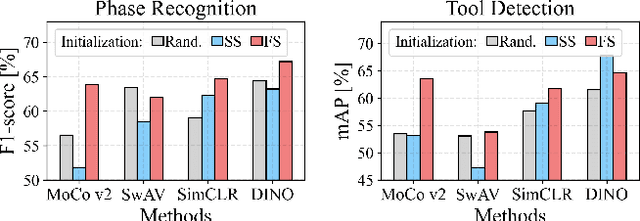
The field of surgical computer vision has undergone considerable breakthroughs in recent years with the rising popularity of deep neural network-based methods. However, standard fully-supervised approaches for training such models require vast amounts of annotated data, imposing a prohibitively high cost; especially in the clinical domain. Self-Supervised Learning (SSL) methods, which have begun to gain traction in the general computer vision community, represent a potential solution to these annotation costs, allowing to learn useful representations from only unlabeled data. Still, the effectiveness of SSL methods in more complex and impactful domains, such as medicine and surgery, remains limited and unexplored. In this work, we address this critical need by investigating four state-of-the-art SSL methods (MoCo v2, SimCLR, DINO, SwAV) in the context of surgical computer vision. We present an extensive analysis of the performance of these methods on the Cholec80 dataset for two fundamental and popular tasks in surgical context understanding, phase recognition and tool presence detection. We examine their parameterization, then their behavior with respect to training data quantities in semi-supervised settings. Correct transfer of these methods to surgery, as described and conducted in this work, leads to substantial performance gains over generic uses of SSL - up to 7% on phase recognition and 20% on tool presence detection - as well as state-of-the-art semi-supervised phase recognition approaches by up to 14%. The code will be made available at https://github.com/CAMMA-public/SelfSupSurg.
Multi-Task Temporal Convolutional Networks for Joint Recognition of Surgical Phases and Steps in Gastric Bypass Procedures
Feb 24, 2021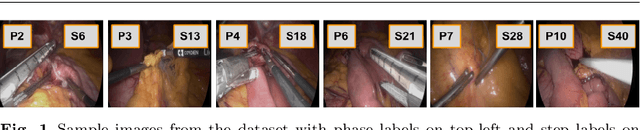
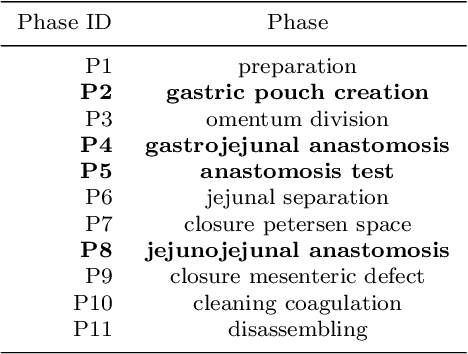
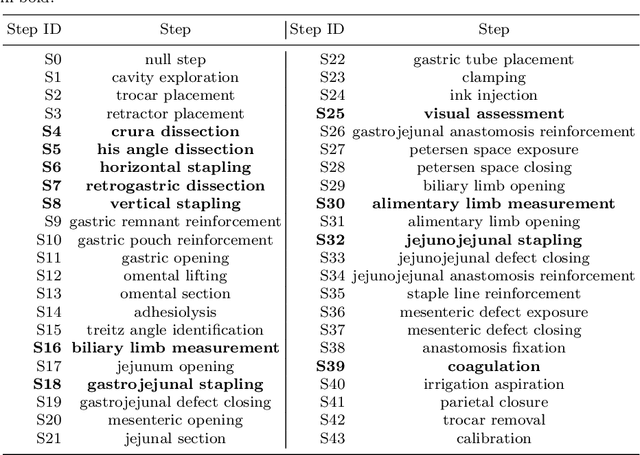
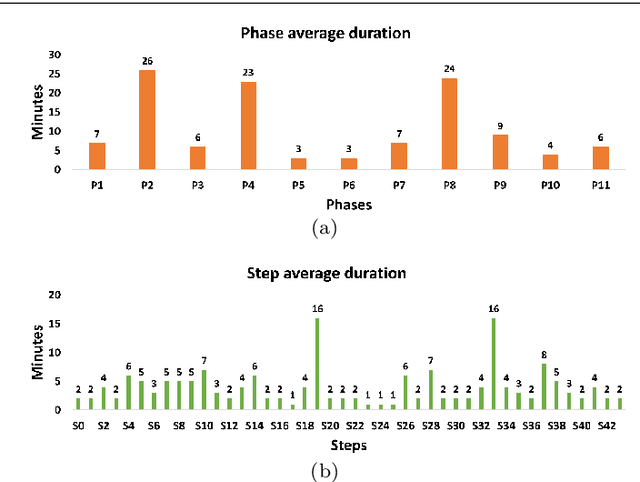
Purpose: Automatic segmentation and classification of surgical activity is crucial for providing advanced support in computer-assisted interventions and autonomous functionalities in robot-assisted surgeries. Prior works have focused on recognizing either coarse activities, such as phases, or fine-grained activities, such as gestures. This work aims at jointly recognizing two complementary levels of granularity directly from videos, namely phases and steps. Method: We introduce two correlated surgical activities, phases and steps, for the laparoscopic gastric bypass procedure. We propose a Multi-task Multi-Stage Temporal Convolutional Network (MTMS-TCN) along with a multi-task Convolutional Neural Network (CNN) training setup to jointly predict the phases and steps and benefit from their complementarity to better evaluate the execution of the procedure. We evaluate the proposed method on a large video dataset consisting of 40 surgical procedures (Bypass40). Results: We present experimental results from several baseline models for both phase and step recognition on the Bypass40 dataset. The proposed MTMS-TCN method outperforms in both phase and step recognition by 1-2% in accuracy, precision and recall, compared to single-task methods. Furthermore, for step recognition, MTMS-TCN achieves a superior performance of 3-6% compared to LSTM based models in accuracy, precision, and recall. Conclusion: In this work, we present a multi-task multi-stage temporal convolutional network for surgical activity recognition, which shows improved results compared to single-task models on the Bypass40 gastric bypass dataset with multi-level annotations. The proposed method shows that the joint modeling of phases and steps is beneficial to improve the overall recognition of each type of activity.