 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightPAFF: A Two-Stage Distillation Framework for Pre-training and Fine-tuning
Apr 27, 2020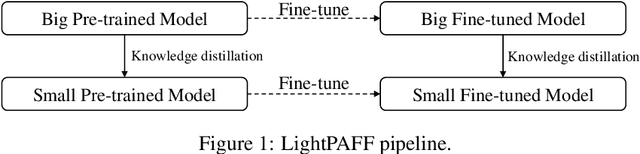
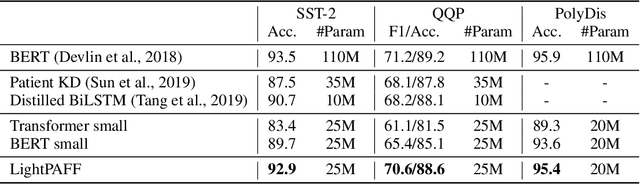

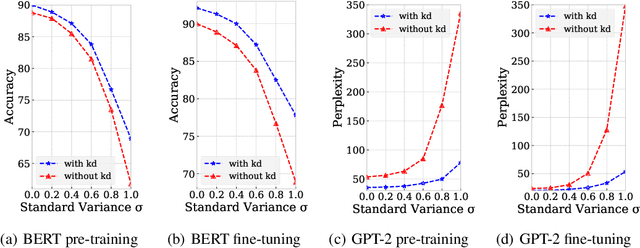
While pre-training and fine-tuning, e.g., BERT~\citep{devlin2018bert}, GPT-2~\citep{radford2019language}, have achieved great success in language understanding and generation tasks, the pre-trained models are usually too big for online deployment in terms of both memory cost and inference speed, which hinders them from practical online usage. In this paper, we propose LightPAFF, a Lightweight Pre-training And Fine-tuning Framework that leverages two-stage knowledge distillation to transfer knowledge from a big teacher model to a lightweight student model in both pre-training and fine-tuning stages. In this way the lightweight model can achieve similar accuracy as the big teacher model, but with much fewer parameters and thus faster online inference speed. LightPAFF can support different pre-training methods (such as BERT, GPT-2 and MASS~\citep{song2019mass}) and be applied to many downstream tasks. Experiments on three language understanding tasks, three language modeling tasks and three sequence to sequence generation tasks demonstrate that while achieving similar accuracy with the big BERT, GPT-2 and MASS models, LightPAFF reduces the model size by nearly 5x and improves online inference speed by 5x-7x.
MPNet: Masked and Permuted Pre-training for Language Understanding
Apr 20, 2020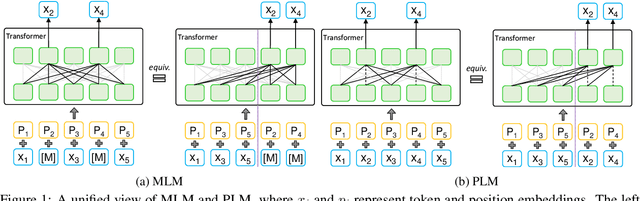

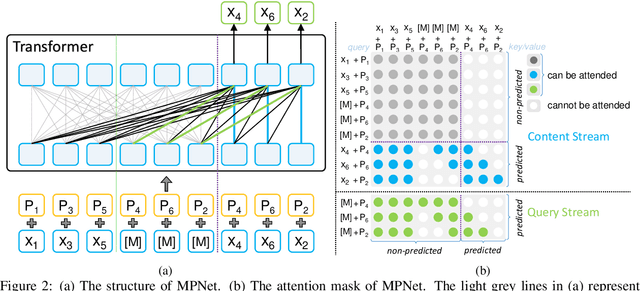
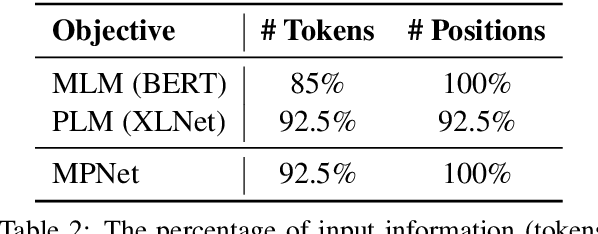
BERT adopts masked language modeling (MLM) for pre-training and is one of the most successful pre-training models. Since BERT neglects dependency among predicted tokens, XLNet introduces permuted language modeling (PLM) for pre-training to address this problem. We argue that XLNet does not leverage the full position information of a sentence and thus suffers from position discrepancy between pre-training and fine-tuning. In this paper, we propose MPNet, a novel pre-training method that inherits the advantages of BERT and XLNet and avoids their limitations. MPNet leverages the dependency among predicted tokens through permuted language modeling (vs. MLM in BERT), and takes auxiliary position information as input to make the model see a full sentence and thus reducing the position discrepancy (vs. PLM in XLNet). We pre-train MPNet on a large-scale dataset (over 160GB text corpora) and fine-tune on a variety of down-streaming tasks (GLUE, SQuAD, etc). Experimental results show that MPNet outperforms MLM and PLM by a large margin, and achieves better results on these tasks compared with previous state-of-the-art pre-trained methods (e.g., BERT, XLNet, RoBERTa) under the same model setting. We release the code and pre-trained model in GitHub\footnote{\url{https://github.com/microsoft/MPNet}}.
Discriminator Contrastive Divergence: Semi-Amortized Generative Modeling by Exploring Energy of the Discriminator
Apr 05, 2020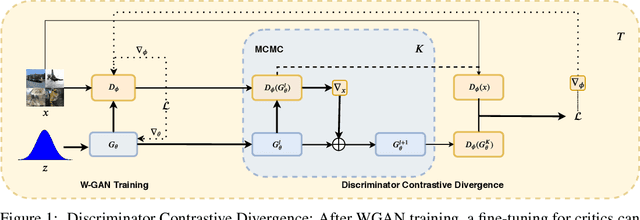
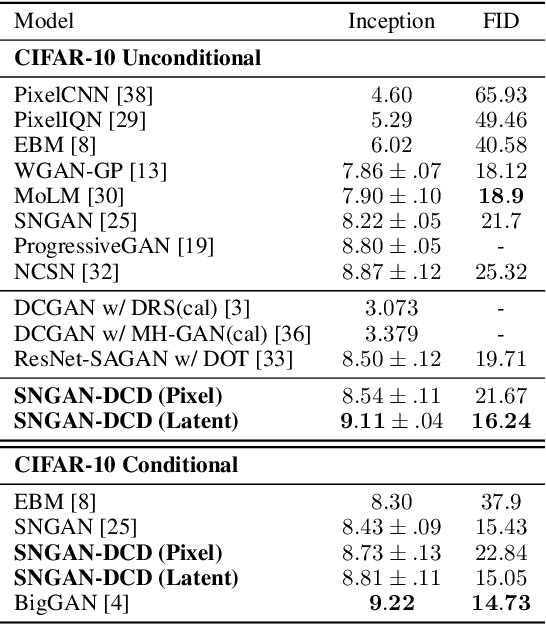
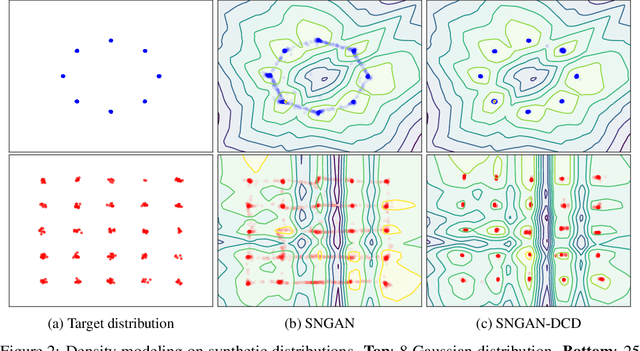
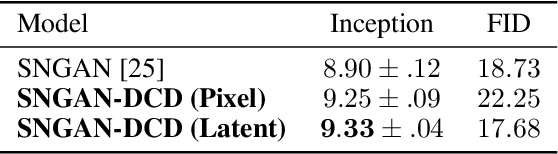
Generative Adversarial Networks (GANs) have shown great promise in modeling high dimensional data. The learning objective of GANs usually minimizes some measure discrepancy, \textit{e.g.}, $f$-divergence~($f$-GANs) or Integral Probability Metric~(Wasserstein GANs). With $f$-divergence as the objective function, the discriminator essentially estimates the density ratio, and the estimated ratio proves useful in further improving the sample quality of the generator. However, how to leverage the information contained in the discriminator of Wasserstein GANs (WGAN) is less explored. In this paper, we introduce the Discriminator Contrastive Divergence, which is well motivated by the property of WGAN's discriminator and the relationship between WGAN and energy-based model. Compared to standard GANs, where the generator is directly utilized to obtain new samples, our method proposes a semi-amortized generation procedure where the samples are produced with the generator's output as an initial state. Then several steps of Langevin dynamics are conducted using the gradient of the discriminator. We demonstrate the benefits of significant improved generation on both synthetic data and several real-world image generation benchmarks.
Suphx: Mastering Mahjong with Deep Reinforcement Learning
Apr 01, 2020
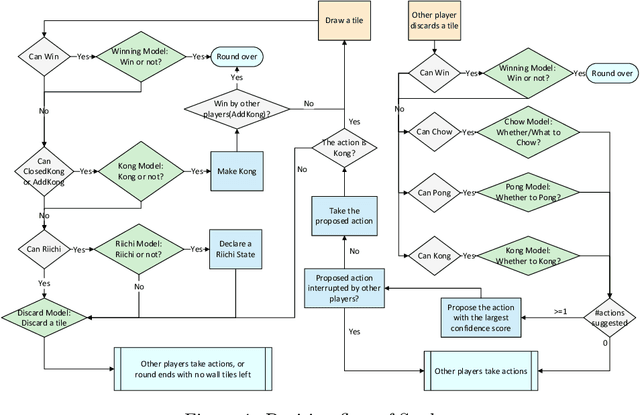
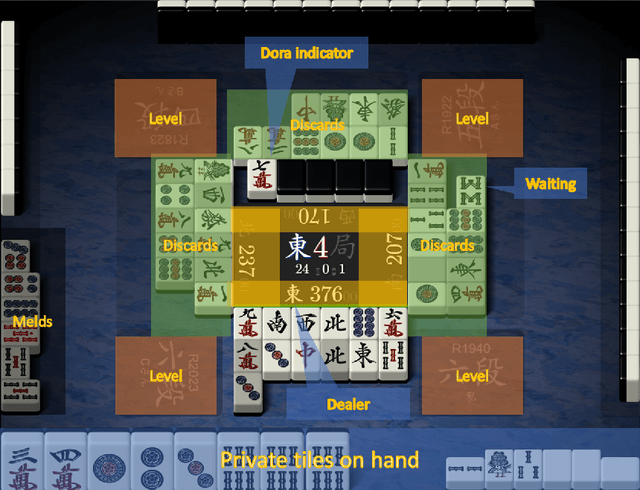

Artificial Intelligence (AI) has achieved great success in many domains, and game AI is widely regarded as its beachhead since the dawn of AI. In recent years, studies on game AI have gradually evolved from relatively simple environments (e.g., perfect-information games such as Go, chess, shogi or two-player imperfect-information games such as heads-up Texas hold'em) to more complex ones (e.g., multi-player imperfect-information games such as multi-player Texas hold'em and StartCraft II). Mahjong is a popular multi-player imperfect-information game worldwide but very challenging for AI research due to its complex playing/scoring rules and rich hidden information. We design an AI for Mahjong, named Suphx, based on deep reinforcement learning with some newly introduced techniques including global reward prediction, oracle guiding, and run-time policy adaptation. Suphx has demonstrated stronger performance than most top human players in terms of stable rank and is rated above 99.99% of all the officially ranked human players in the Tenhou platform. This is the first time that a computer program outperforms most top human players in Mahjong.
Semi-Supervised Neural Architecture Search
Mar 09, 2020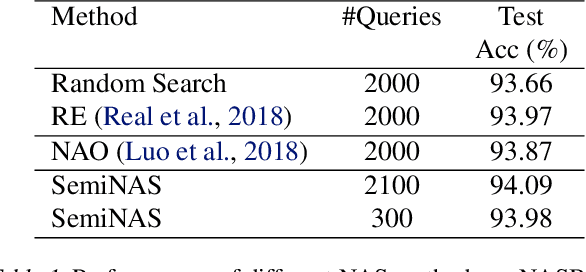
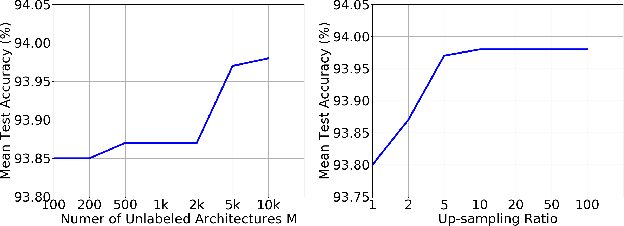
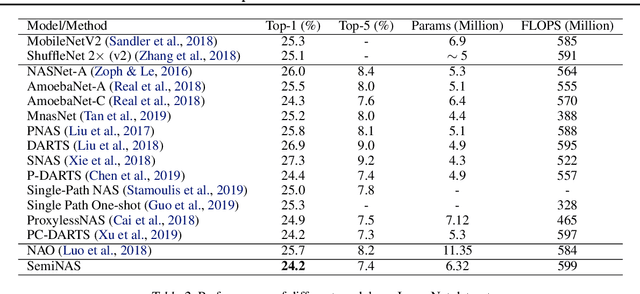
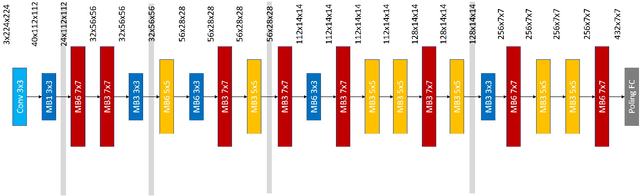
Neural architecture search (NAS) relies on a good controller to generate better architectures or predict the accuracy of given architectures. However, training the controller requires both abundant and high-quality pairs of architectures and their accuracy, while it is costly to evaluate an architecture and obtain its accuracy. In this paper, we propose SemiNAS, a semi-supervised NAS approach that leverages numerous unlabeled architectures (without evaluation and thus nearly no cost) to improve the controller. Specifically, SemiNAS 1) trains an initial controller with a small set of architecture-accuracy data pairs; 2) uses the trained controller to predict the accuracy of large amount of architectures~(without evaluation); and 3) adds the generated data pairs to the original data to further improve the controller. SemiNAS has two advantages: 1) It reduces the computational cost under the same accuracy guarantee. 2) It achieves higher accuracy under the same computational cost. On NASBench-101 benchmark dataset, it discovers a top 0.01% architecture after evaluating roughly 300 architectures, with only 1/7 computational cost compared with regularized evolution and gradient-based methods. On ImageNet, it achieves a state-of-the-art top-1 error rate of $23.5\%$ (under the mobile setting) using 4 GPU-days for search. We further apply it to LJSpeech text to speech task and it achieves 97% intelligibility rate in the low-resource setting and 15% test error rate in the robustness setting, with 9%, 7% improvements over the baseline respectively. Our code is available at https://github.com/renqianluo/SemiNAS.
Incorporating BERT into Neural Machine Translation
Feb 17, 2020
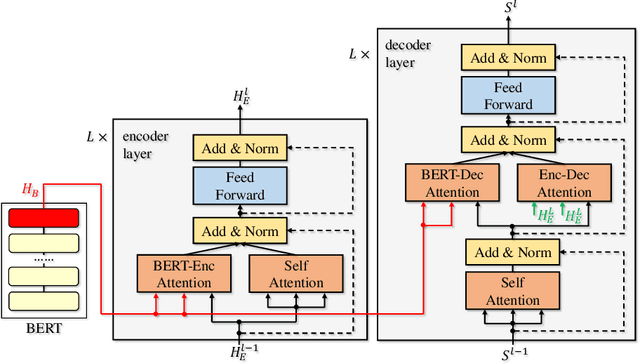
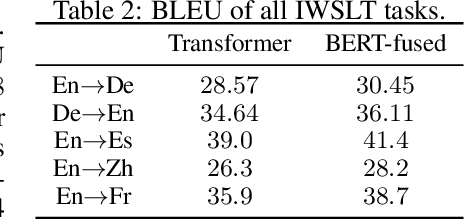
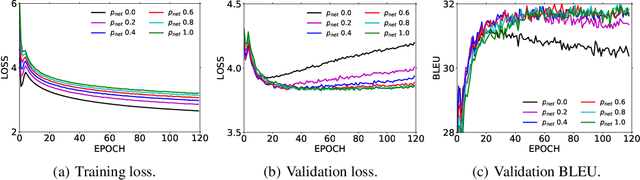
The recently proposed BERT has shown great power on a variety of natural language understanding tasks, such as text classification, reading comprehension, etc. However, how to effectively apply BERT to neural machine translation (NMT) lacks enough exploration. While BERT is more commonly used as fine-tuning instead of contextual embedding for downstream language understanding tasks, in NMT, our preliminary exploration of using BERT as contextual embedding is better than using for fine-tuning. This motivates us to think how to better leverage BERT for NMT along this direction. We propose a new algorithm named BERT-fused model, in which we first use BERT to extract representations for an input sequence, and then the representations are fused with each layer of the encoder and decoder of the NMT model through attention mechanisms. We conduct experiments on supervised (including sentence-level and document-level translations), semi-supervised and unsupervised machine translation, and achieve state-of-the-art results on seven benchmark datasets. Our code is available at \url{https://github.com/bert-nmt/bert-nmt}.
On Layer Normalization in the Transformer Architecture
Feb 12, 2020

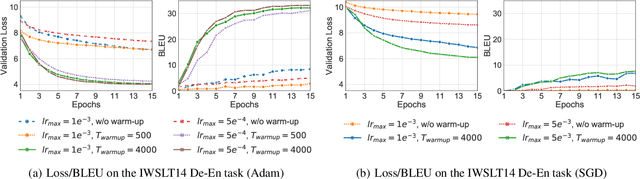

The Transformer is widely used in natural language processing tasks. To train a Transformer however, one usually needs a carefully designed learning rate warm-up stage, which is shown to be crucial to the final performance but will slow down the optimization and bring more hyper-parameter tunings. In this paper, we first study theoretically why the learning rate warm-up stage is essential and show that the location of layer normalization matters. Specifically, we prove with mean field theory that at initialization, for the original-designed Post-LN Transformer, which places the layer normalization between the residual blocks, the expected gradients of the parameters near the output layer are large. Therefore, using a large learning rate on those gradients makes the training unstable. The warm-up stage is practically helpful for avoiding this problem. On the other hand, our theory also shows that if the layer normalization is put inside the residual blocks (recently proposed as Pre-LN Transformer), the gradients are well-behaved at initialization. This motivates us to remove the warm-up stage for the training of Pre-LN Transformers. We show in our experiments that Pre-LN Transformers without the warm-up stage can reach comparable results with baselines while requiring significantly less training time and hyper-parameter tuning on a wide range of applications.
A Study of Multilingual Neural Machine Translation
Dec 25, 2019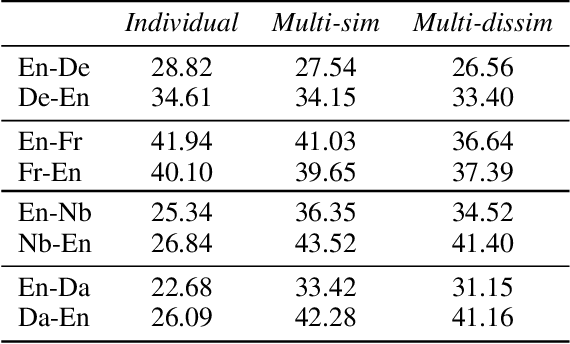
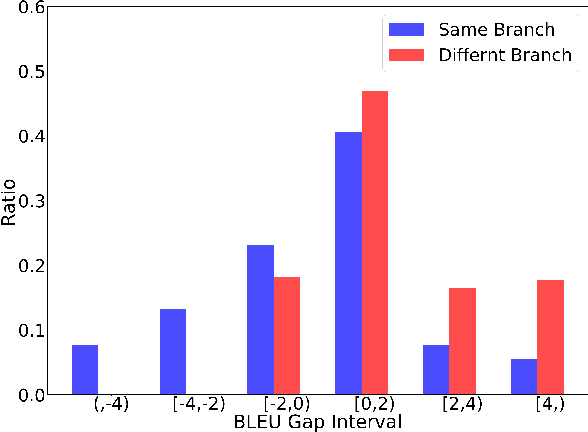
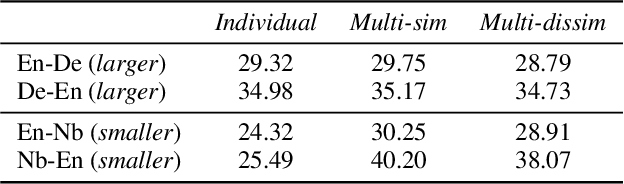
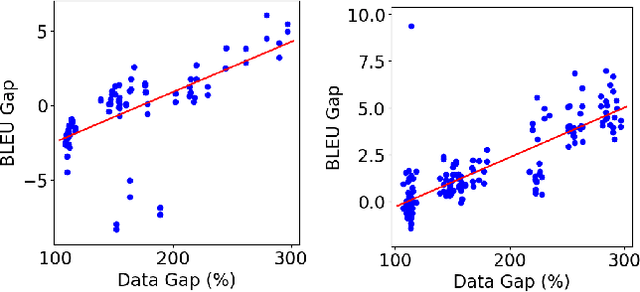
Multilingual neural machine translation (NMT) has recently been investigated from different aspects (e.g., pivot translation, zero-shot translation, fine-tuning, or training from scratch) and in different settings (e.g., rich resource and low resource, one-to-many, and many-to-one translation). This paper concentrates on a deep understanding of multilingual NMT and conducts a comprehensive study on a multilingual dataset with more than 20 languages. Our results show that (1) low-resource language pairs benefit much from multilingual training, while rich-resource language pairs may get hurt under limited model capacity and training with similar languages benefits more than dissimilar languages; (2) fine-tuning performs better than training from scratch in the one-to-many setting while training from scratch performs better in the many-to-one setting; (3) the bottom layers of the encoder and top layers of the decoder capture more language-specific information, and just fine-tuning these parts can achieve good accuracy for low-resource language pairs; (4) direct translation is better than pivot translation when the source language is similar to the target language (e.g., in the same language branch), even when the size of direct training data is much smaller; (5) given a fixed training data budget, it is better to introduce more languages into multilingual training for zero-shot translation.
Gradient Perturbation is Underrated for Differentially Private Convex Optimization
Nov 26, 2019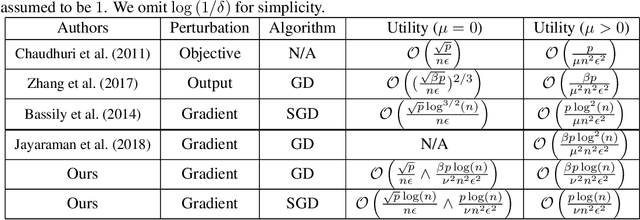
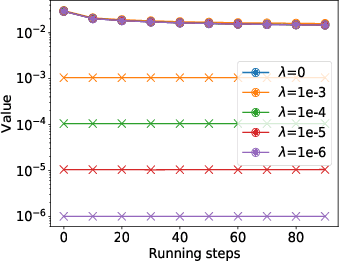
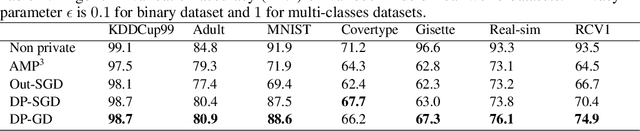
Gradient perturbation, widely used for differentially private optimization, injects noise at every iterative update to guarantee differential privacy. Previous work first determines the noise level that can satisfy the privacy requirement and then analyzes the utility of noisy gradient updates as in non-private case. In this paper, we explore how the privacy noise affects the optimization property. We show that for differentially private convex optimization, the utility guarantee of both DP-GD and DP-SGD is determined by an \emph{expected curvature} rather than the minimum curvature. The \emph{expected curvature} represents the average curvature over the optimization path, which is usually much larger than the minimum curvature and hence can help us achieve a significantly improved utility guarantee. By using the \emph{expected curvature}, our theory justifies the advantage of gradient perturbation over other perturbation methods and closes the gap between theory and practice. Extensive experiments on real world datasets corroborate our theoretical findings.
Fine-Tuning by Curriculum Learning for Non-Autoregressive Neural Machine Translation
Nov 21, 2019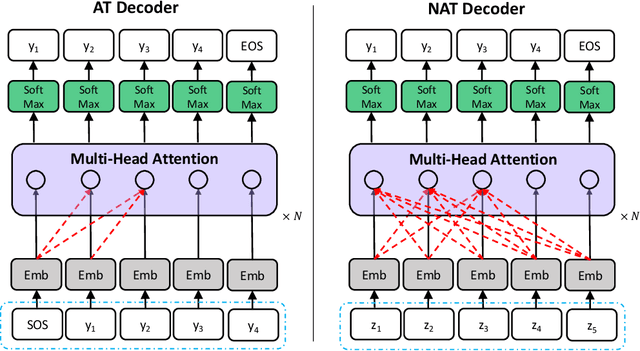

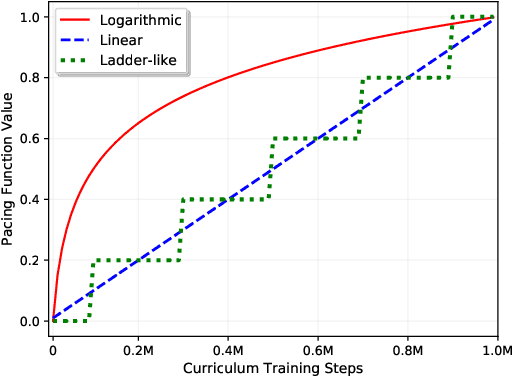
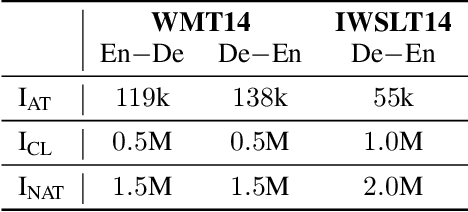
Non-autoregressive translation (NAT) models remove the dependence on previous target tokens and generate all target tokens in parallel, resulting in significant inference speedup but at the cost of inferior translation accuracy compared to autoregressive translation (AT) models. Considering that AT models have higher accuracy and are easier to train than NAT models, and both of them share the same model configurations, a natural idea to improve the accuracy of NAT models is to transfer a well-trained AT model to an NAT model through fine-tuning. However, since AT and NAT models differ greatly in training strategy, straightforward fine-tuning does not work well. In this work, we introduce curriculum learning into fine-tuning for NAT. Specifically, we design a curriculum in the fine-tuning process to progressively switch the training from autoregressive generation to non-autoregressive generation. Experiments on four benchmark translation datasets show that the proposed method achieves good improvement (more than $1$ BLEU score) over previous NAT baselines in terms of translation accuracy, and greatly speed up (more than $10$ times) the inference process over AT baselines.