 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Context-oriented Decomposition for Task-aware Low-rank Adaptation with Less Forgetting and Faster Convergence
Jun 16, 2025



Conventional low-rank adaptation methods build adapters without considering data context, leading to sub-optimal fine-tuning performance and severe forgetting of inherent world knowledge. In this paper, we propose context-oriented decomposition adaptation (CorDA), a novel method that initializes adapters in a task-aware manner. Concretely, we develop context-oriented singular value decomposition, where we collect covariance matrices of input activations for each linear layer using sampled data from the target task, and apply SVD to the product of weight matrix and its corresponding covariance matrix. By doing so, the task-specific capability is compacted into the principal components. Thanks to the task awareness, our method enables two optional adaptation modes, knowledge-preserved mode (KPM) and instruction-previewed mode (IPM), providing flexibility to choose between freezing the principal components to preserve their associated knowledge or adapting them to better learn a new task. We further develop CorDA++ by deriving a metric that reflects the compactness of task-specific principal components, and then introducing dynamic covariance selection and dynamic rank allocation strategies based on the same metric. The two strategies provide each layer with the most representative covariance matrix and a proper rank allocation. Experimental results show that CorDA++ outperforms CorDA by a significant margin. CorDA++ in KPM not only achieves better fine-tuning performance than LoRA, but also mitigates the forgetting of pre-trained knowledge in both large language models and vision language models. For IPM, our method exhibits faster convergence, \emph{e.g.,} 4.5x speedup over QLoRA, and improves adaptation performance in various scenarios, outperforming strong baseline methods. Our method has been integrated into the PEFT library developed by Hugging Face.
Optimizing Singular Spectrum for Large Language Model Compression
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable capabilities, yet prohibitive parameter complexity often hinders their deployment. Existing singular value decomposition (SVD) based compression methods simply deem singular values as importance scores of decomposed components. However, this importance ordered by singular values does not necessarily correlate with the performance of a downstream task. In this work, we introduce SoCo (Singular spectrum optimization for large language model Compression), a novel compression framework that learns to rescale the decomposed components of SVD in a data-driven manner. Concretely, we employ a learnable diagonal matrix to assign importance scores for singular spectrum and develop a three-stage training process that progressively refines these scores from initial coarse compression to fine-grained sparsification-thereby striking an effective balance between aggressive model compression and performance preservation. Thanks to the learnable singular spectrum, SoCo adaptively prunes components according to the sparsified importance scores, rather than relying on the fixed order of singular values. More importantly, the remaining components with amplified importance scores can compensate for the loss of the pruned ones. Experimental evaluations across multiple LLMs and benchmarks demonstrate that SoCo surpasses the state-of-the-art methods in model compression.
Empowering Visual Creativity: A Vision-Language Assistant to Image Editing Recommendations
May 31, 2024



Advances in text-based image generation and editing have revolutionized content creation, enabling users to create impressive content from imaginative text prompts. However, existing methods are not designed to work well with the oversimplified prompts that are often encountered in typical scenarios when users start their editing with only vague or abstract purposes in mind. Those scenarios demand elaborate ideation efforts from the users to bridge the gap between such vague starting points and the detailed creative ideas needed to depict the desired results. In this paper, we introduce the task of Image Editing Recommendation (IER). This task aims to automatically generate diverse creative editing instructions from an input image and a simple prompt representing the users' under-specified editing purpose. To this end, we introduce Creativity-Vision Language Assistant~(Creativity-VLA), a multimodal framework designed specifically for edit-instruction generation. We train Creativity-VLA on our edit-instruction dataset specifically curated for IER. We further enhance our model with a novel 'token-for-localization' mechanism, enabling it to support both global and local editing operations. Our experimental results demonstrate the effectiveness of \ours{} in suggesting instructions that not only contain engaging creative elements but also maintain high relevance to both the input image and the user's initial hint.
Generalizable Entity Grounding via Assistance of Large Language Model
Feb 04, 2024In this work, we propose a novel approach to densely ground visual entities from a long caption. We leverage a large multimodal model (LMM) to extract semantic nouns, a class-agnostic segmentation model to generate entity-level segmentation, and the proposed multi-modal feature fusion module to associate each semantic noun with its corresponding segmentation mask. Additionally, we introduce a strategy of encoding entity segmentation masks into a colormap, enabling the preservation of fine-grained predictions from features of high-resolution masks. This approach allows us to extract visual features from low-resolution images using the CLIP vision encoder in the LMM, which is more computationally efficient than existing approaches that use an additional encoder for high-resolution images. Our comprehensive experiments demonstrate the superiority of our method, outperforming state-of-the-art techniques on three tasks, including panoptic narrative grounding, referring expression segmentation, and panoptic segmentation.
Rethinking Evaluation Metrics of Open-Vocabulary Segmentaion
Nov 06, 2023



In this paper, we highlight a problem of evaluation metrics adopted in the open-vocabulary segmentation. That is, the evaluation process still heavily relies on closed-set metrics on zero-shot or cross-dataset pipelines without considering the similarity between predicted and ground truth categories. To tackle this issue, we first survey eleven similarity measurements between two categorical words using WordNet linguistics statistics, text embedding, and language models by comprehensive quantitative analysis and user study. Built upon those explored measurements, we designed novel evaluation metrics, namely Open mIoU, Open AP, and Open PQ, tailored for three open-vocabulary segmentation tasks. We benchmarked the proposed evaluation metrics on 12 open-vocabulary methods of three segmentation tasks. Even though the relative subjectivity of similarity distance, we demonstrate that our metrics can still well evaluate the open ability of the existing open-vocabulary segmentation methods. We hope that our work can bring with the community new thinking about how to evaluate the open ability of models. The evaluation code is released in github.
Fine-Grained Entity Segmentation
Nov 12, 2022



In dense image segmentation tasks (e.g., semantic, panoptic), existing methods can hardly generalize well to unseen image domains, predefined classes, and image resolution & quality variations. Motivated by these observations, we construct a large-scale entity segmentation dataset to explore fine-grained entity segmentation, with a strong focus on open-world and high-quality dense segmentation. The dataset contains images spanning diverse image domains and resolutions, along with high-quality mask annotations for training and testing. Given the high-quality and -resolution nature of the dataset, we propose CropFormer for high-quality segmentation, which can improve mask prediction using high-res image crops that provide more fine-grained image details than the full image. CropFormer is the first query-based Transformer architecture that can effectively ensemble mask predictions from multiple image crops, by learning queries that can associate the same entities across the full image and its crop. With CropFormer, we achieve a significant AP gain of $1.9$ on the challenging fine-grained entity segmentation task. The dataset and code will be released at http://luqi.info/entityv2.github.io/.
EfficientNeRF: Efficient Neural Radiance Fields
Jun 02, 2022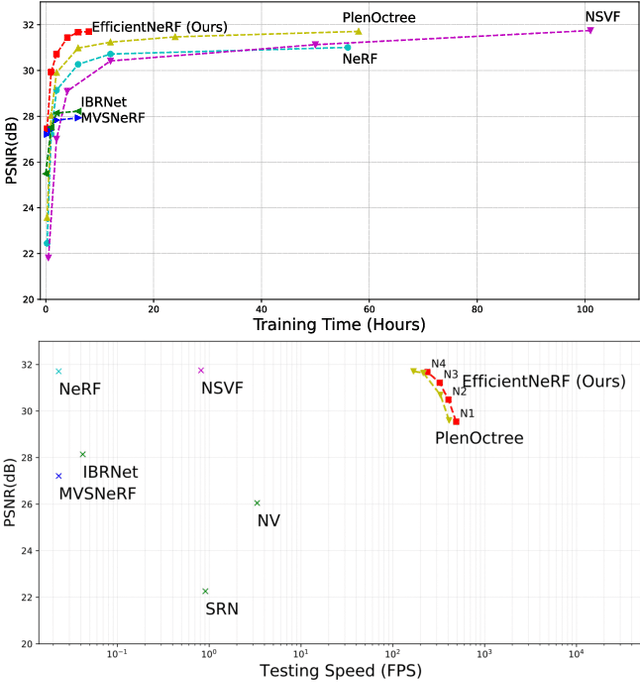

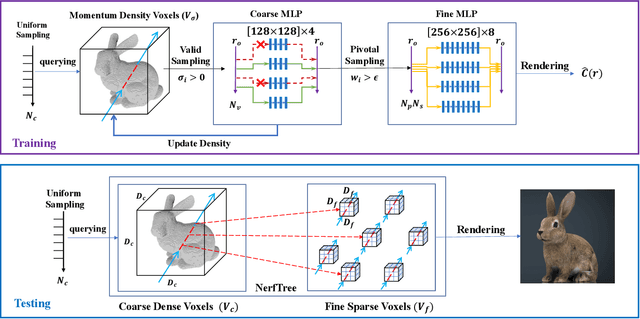
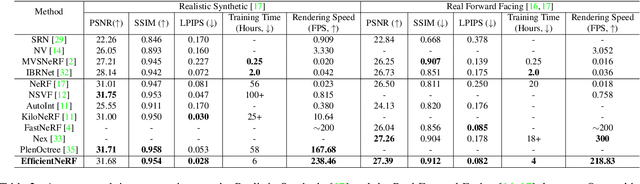
Neural Radiance Fields (NeRF) has been wildly applied to various tasks for its high-quality representation of 3D scenes. It takes long per-scene training time and per-image testing time. In this paper, we present EfficientNeRF as an efficient NeRF-based method to represent 3D scene and synthesize novel-view images. Although several ways exist to accelerate the training or testing process, it is still difficult to much reduce time for both phases simultaneously. We analyze the density and weight distribution of the sampled points then propose valid and pivotal sampling at the coarse and fine stage, respectively, to significantly improve sampling efficiency. In addition, we design a novel data structure to cache the whole scene during testing to accelerate the rendering speed. Overall, our method can reduce over 88\% of training time, reach rendering speed of over 200 FPS, while still achieving competitive accuracy. Experiments prove that our method promotes the practicality of NeRF in the real world and enables many applications.
High Quality Segmentation for Ultra High-resolution Images
Dec 26, 2021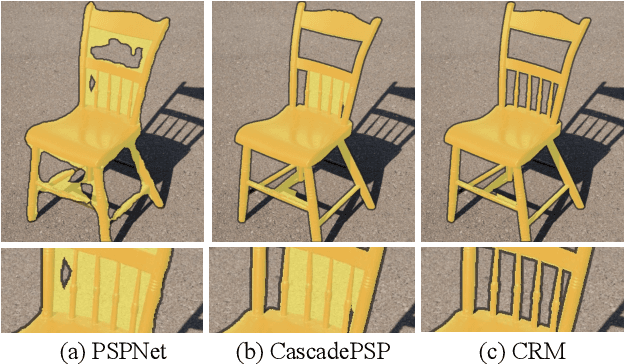
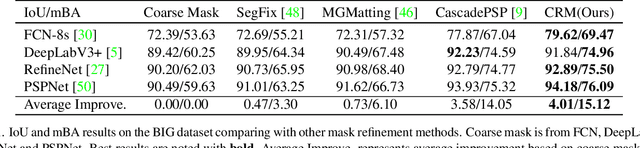
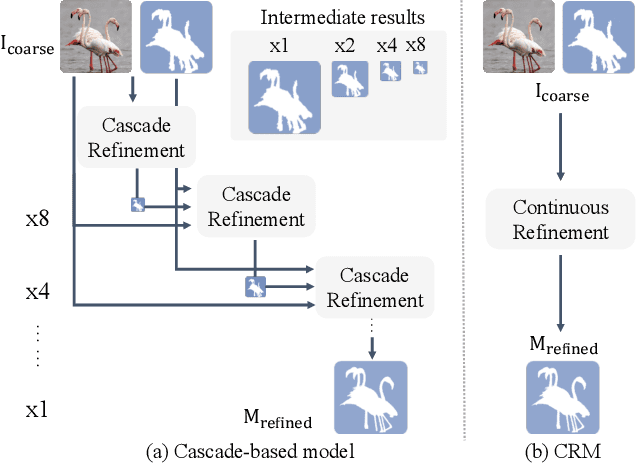
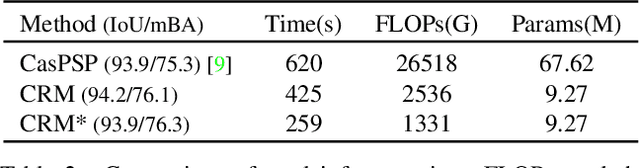
To segment 4K or 6K ultra high-resolution images needs extra computation consideration in image segmentation. Common strategies, such as down-sampling, patch cropping, and cascade model, cannot address well the balance issue between accuracy and computation cost. Motivated by the fact that humans distinguish among objects continuously from coarse to precise levels, we propose the Continuous Refinement Model~(CRM) for the ultra high-resolution segmentation refinement task. CRM continuously aligns the feature map with the refinement target and aggregates features to reconstruct these images' details. Besides, our CRM shows its significant generalization ability to fill the resolution gap between low-resolution training images and ultra high-resolution testing ones. We present quantitative performance evaluation and visualization to show that our proposed method is fast and effective on image segmentation refinement. Code will be released at https://github.com/dvlab-research/Entity.
PDO-e$\text{S}^\text{2}$CNNs: Partial Differential Operator Based Equivariant Spherical CNNs
Apr 08, 2021
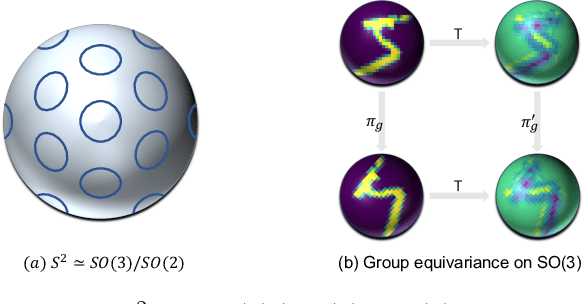
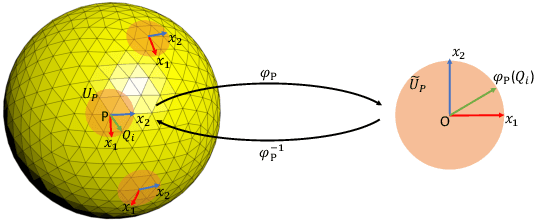
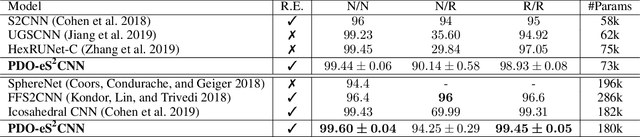
Spherical signals exist in many applications, e.g., planetary data, LiDAR scans and digitalization of 3D objects, calling for models that can process spherical data effectively. It does not perform well when simply projecting spherical data into the 2D plane and then using planar convolution neural networks (CNNs), because of the distortion from projection and ineffective translation equivariance. Actually, good principles of designing spherical CNNs are avoiding distortions and converting the shift equivariance property in planar CNNs to rotation equivariance in the spherical domain. In this work, we use partial differential operators (PDOs) to design a spherical equivariant CNN, PDO-e$\text{S}^\text{2}$CNN, which is exactly rotation equivariant in the continuous domain. We then discretize PDO-e$\text{S}^\text{2}$CNNs, and analyze the equivariance error resulted from discretization. This is the first time that the equivariance error is theoretically analyzed in the spherical domain. In experiments, PDO-e$\text{S}^\text{2}$CNNs show greater parameter efficiency and outperform other spherical CNNs significantly on several tasks.
Spatial Pyramid Based Graph Reasoning for Semantic Segmentation
Mar 23, 2020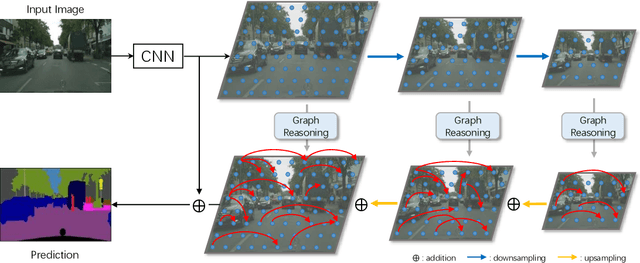
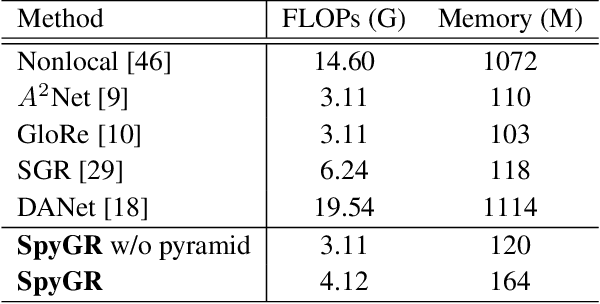
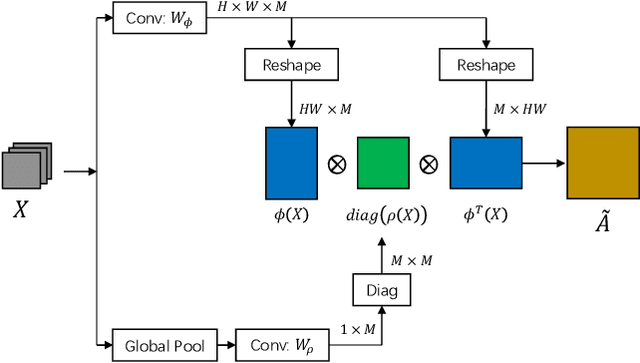
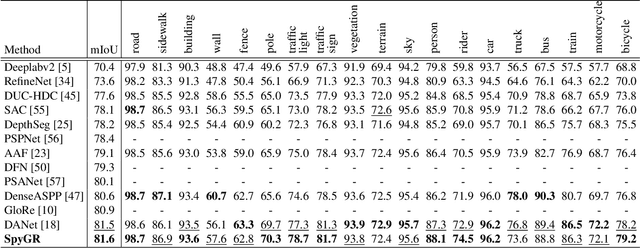
The convolution operation suffers from a limited receptive filed, while global modeling is fundamental to dense prediction tasks, such as semantic segmentation. In this paper, we apply graph convolution into the semantic segmentation task and propose an improved Laplacian. The graph reasoning is directly performed in the original feature space organized as a spatial pyramid. Different from existing methods, our Laplacian is data-dependent and we introduce an attention diagonal matrix to learn a better distance metric. It gets rid of projecting and re-projecting processes, which makes our proposed method a light-weight module that can be easily plugged into current computer vision architectures. More importantly, performing graph reasoning directly in the feature space retains spatial relationships and makes spatial pyramid possible to explore multiple long-range contextual patterns from different scales. Experiments on Cityscapes, COCO Stuff, PASCAL Context and PASCAL VOC demonstrate the effectiveness of our proposed methods on semantic segmentation. We achieve comparable performance with advantages in computational and memory overhead.