 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShop-R1: Rewarding LLMs to Simulate Human Behavior in Online Shopping via Reinforcement Learning
Jul 23, 2025
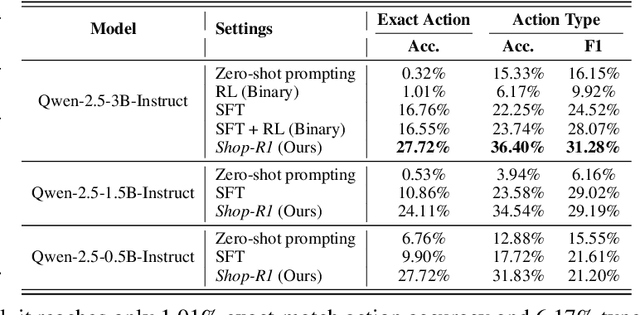
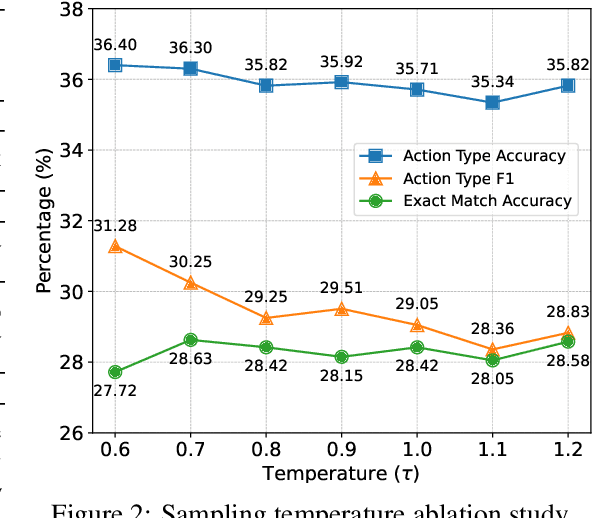
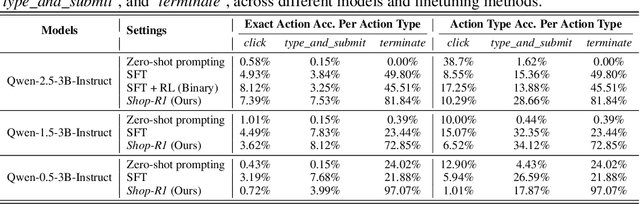
Large Language Models (LLMs) have recently demonstrated strong potential in generating 'believable human-like' behavior in web environments. Prior work has explored augmenting training data with LLM-synthesized rationales and applying supervised fine-tuning (SFT) to enhance reasoning ability, which in turn can improve downstream action prediction. However, the performance of such approaches remains inherently bounded by the reasoning capabilities of the model used to generate the rationales. In this paper, we introduce Shop-R1, a novel reinforcement learning (RL) framework aimed at enhancing the reasoning ability of LLMs for simulation of real human behavior in online shopping environments Specifically, Shop-R1 decomposes the human behavior simulation task into two stages: rationale generation and action prediction, each guided by distinct reward signals. For rationale generation, we leverage internal model signals (e.g., logit distributions) to guide the reasoning process in a self-supervised manner. For action prediction, we propose a hierarchical reward structure with difficulty-aware scaling to prevent reward hacking and enable fine-grained reward assignment. This design evaluates both high-level action types and the correctness of fine-grained sub-action details (attributes and values), rewarding outputs proportionally to their difficulty. Experimental results show that our method achieves a relative improvement of over 65% compared to the baseline.
OPeRA: A Dataset of Observation, Persona, Rationale, and Action for Evaluating LLMs on Human Online Shopping Behavior Simulation
Jun 05, 2025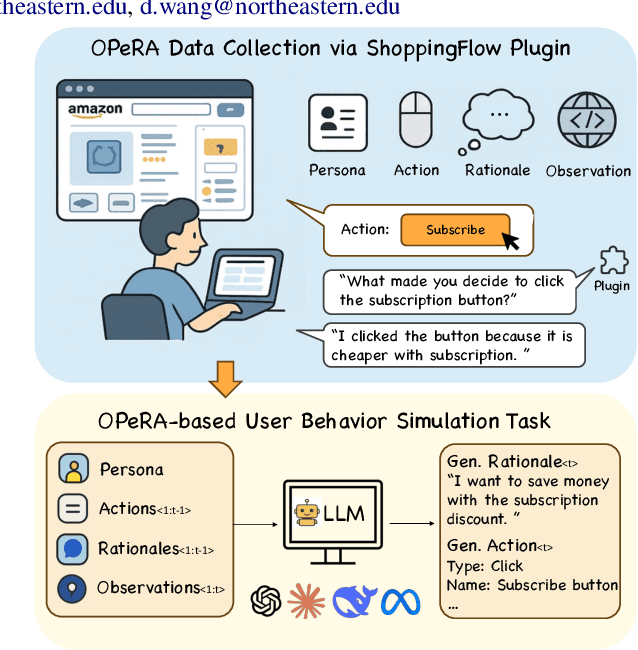
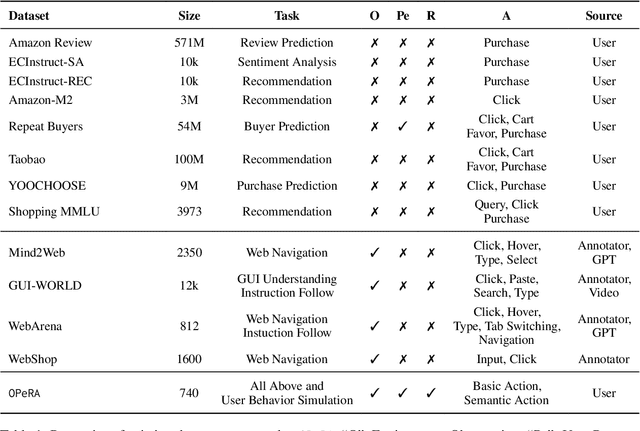
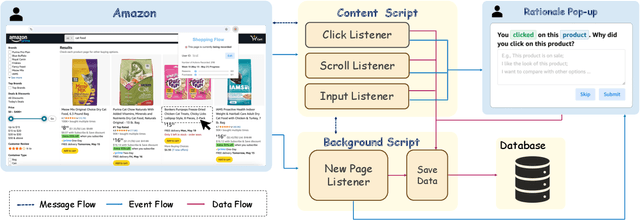
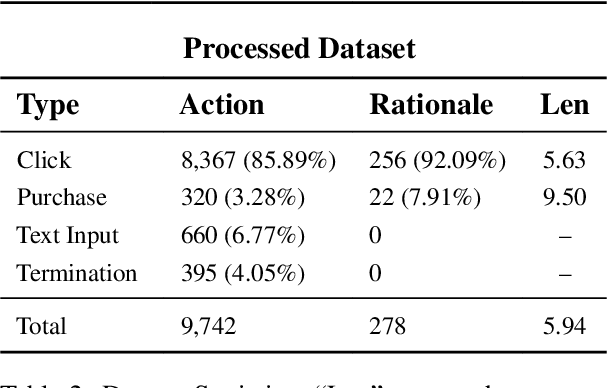
Can large language models (LLMs) accurately simulate the next web action of a specific user? While LLMs have shown promising capabilities in generating ``believable'' human behaviors, evaluating their ability to mimic real user behaviors remains an open challenge, largely due to the lack of high-quality, publicly available datasets that capture both the observable actions and the internal reasoning of an actual human user. To address this gap, we introduce OPERA, a novel dataset of Observation, Persona, Rationale, and Action collected from real human participants during online shopping sessions. OPERA is the first public dataset that comprehensively captures: user personas, browser observations, fine-grained web actions, and self-reported just-in-time rationales. We developed both an online questionnaire and a custom browser plugin to gather this dataset with high fidelity. Using OPERA, we establish the first benchmark to evaluate how well current LLMs can predict a specific user's next action and rationale with a given persona and <observation, action, rationale> history. This dataset lays the groundwork for future research into LLM agents that aim to act as personalized digital twins for human.
Hybrid Learning for Cold-Start-Aware Microservice Scheduling in Dynamic Edge Environments
May 28, 2025With the rapid growth of IoT devices and their diverse workloads, container-based microservices deployed at edge nodes have become a lightweight and scalable solution. However, existing microservice scheduling algorithms often assume static resource availability, which is unrealistic when multiple containers are assigned to an edge node. Besides, containers suffer from cold-start inefficiencies during early-stage training in currently popular reinforcement learning (RL) algorithms. In this paper, we propose a hybrid learning framework that combines offline imitation learning (IL) with online Soft Actor-Critic (SAC) optimization to enable a cold-start-aware microservice scheduling with dynamic allocation for computing resources. We first formulate a delay-and-energy-aware scheduling problem and construct a rule-based expert to generate demonstration data for behavior cloning. Then, a GRU-enhanced policy network is designed in the policy network to extract the correlation among multiple decisions by separately encoding slow-evolving node states and fast-changing microservice features, and an action selection mechanism is given to speed up the convergence. Extensive experiments show that our method significantly accelerates convergence and achieves superior final performance. Compared with baselines, our algorithm improves the total objective by $50\%$ and convergence speed by $70\%$, and demonstrates the highest stability and robustness across various edge configurations.
FedHL: Federated Learning for Heterogeneous Low-Rank Adaptation via Unbiased Aggregation
May 24, 2025



Federated Learning (FL) facilitates the fine-tuning of Foundation Models (FMs) using distributed data sources, with Low-Rank Adaptation (LoRA) gaining popularity due to its low communication costs and strong performance. While recent work acknowledges the benefits of heterogeneous LoRA in FL and introduces flexible algorithms to support its implementation, our theoretical analysis reveals a critical gap: existing methods lack formal convergence guarantees due to parameter truncation and biased gradient updates. Specifically, adapting client-specific LoRA ranks necessitates truncating global parameters, which introduces inherent truncation errors and leads to subsequent inaccurate gradient updates that accumulate over training rounds, ultimately degrading performance. To address the above issues, we propose \textbf{FedHL}, a simple yet effective \textbf{Fed}erated Learning framework tailored for \textbf{H}eterogeneous \textbf{L}oRA. By leveraging the full-rank global model as a calibrated aggregation basis, FedHL eliminates the direct truncation bias from initial alignment with client-specific ranks. Furthermore, we derive the theoretically optimal aggregation weights by minimizing the gradient drift term in the convergence upper bound. Our analysis shows that FedHL guarantees $\mathcal{O}(1/\sqrt{T})$ convergence rate, and experiments on multiple real-world datasets demonstrate a 1-3\% improvement over several state-of-the-art methods.
AFCL: Analytic Federated Continual Learning for Spatio-Temporal Invariance of Non-IID Data
May 18, 2025Federated Continual Learning (FCL) enables distributed clients to collaboratively train a global model from online task streams in dynamic real-world scenarios. However, existing FCL methods face challenges of both spatial data heterogeneity among distributed clients and temporal data heterogeneity across online tasks. Such data heterogeneity significantly degrades the model performance with severe spatial-temporal catastrophic forgetting of local and past knowledge. In this paper, we identify that the root cause of this issue lies in the inherent vulnerability and sensitivity of gradients to non-IID data. To fundamentally address this issue, we propose a gradient-free method, named Analytic Federated Continual Learning (AFCL), by deriving analytical (i.e., closed-form) solutions from frozen extracted features. In local training, our AFCL enables single-epoch learning with only a lightweight forward-propagation process for each client. In global aggregation, the server can recursively and efficiently update the global model with single-round aggregation. Theoretical analyses validate that our AFCL achieves spatio-temporal invariance of non-IID data. This ideal property implies that, regardless of how heterogeneous the data are distributed across local clients and online tasks, the aggregated model of our AFCL remains invariant and identical to that of centralized joint learning. Extensive experiments show the consistent superiority of our AFCL over state-of-the-art baselines across various benchmark datasets and settings.
InfoPO: On Mutual Information Maximization for Large Language Model Alignment
May 13, 2025We study the post-training of large language models (LLMs) with human preference data. Recently, direct preference optimization and its variants have shown considerable promise in aligning language models, eliminating the need for reward models and online sampling. Despite these benefits, these methods rely on explicit assumptions about the Bradley-Terry (BT) model, which makes them prone to overfitting and results in suboptimal performance, particularly on reasoning-heavy tasks. To address these challenges, we propose a principled preference fine-tuning algorithm called InfoPO, which effectively and efficiently aligns large language models using preference data. InfoPO eliminates the reliance on the BT model and prevents the likelihood of the chosen response from decreasing. Extensive experiments confirm that InfoPO consistently outperforms established baselines on widely used open benchmarks, particularly in reasoning tasks.
Rec-R1: Bridging Generative Large Language Models and User-Centric Recommendation Systems via Reinforcement Learning
Mar 31, 2025



We propose Rec-R1, a general reinforcement learning framework that bridges large language models (LLMs) with recommendation systems through closed-loop optimization. Unlike prompting and supervised fine-tuning (SFT), Rec-R1 directly optimizes LLM generation using feedback from a fixed black-box recommendation model, without relying on synthetic SFT data from proprietary models such as GPT-4o. This avoids the substantial cost and effort required for data distillation. To verify the effectiveness of Rec-R1, we evaluate it on two representative tasks: product search and sequential recommendation. Experimental results demonstrate that Rec-R1 not only consistently outperforms prompting- and SFT-based methods, but also achieves significant gains over strong discriminative baselines, even when used with simple retrievers such as BM25. Moreover, Rec-R1 preserves the general-purpose capabilities of the LLM, unlike SFT, which often impairs instruction-following and reasoning. These findings suggest Rec-R1 as a promising foundation for continual task-specific adaptation without catastrophic forgetting.
Empowering Edge Intelligence: A Comprehensive Survey on On-Device AI Models
Mar 08, 2025



The rapid advancement of artificial intelligence (AI) technologies has led to an increasing deployment of AI models on edge and terminal devices, driven by the proliferation of the Internet of Things (IoT) and the need for real-time data processing. This survey comprehensively explores the current state, technical challenges, and future trends of on-device AI models. We define on-device AI models as those designed to perform local data processing and inference, emphasizing their characteristics such as real-time performance, resource constraints, and enhanced data privacy. The survey is structured around key themes, including the fundamental concepts of AI models, application scenarios across various domains, and the technical challenges faced in edge environments. We also discuss optimization and implementation strategies, such as data preprocessing, model compression, and hardware acceleration, which are essential for effective deployment. Furthermore, we examine the impact of emerging technologies, including edge computing and foundation models, on the evolution of on-device AI models. By providing a structured overview of the challenges, solutions, and future directions, this survey aims to facilitate further research and application of on-device AI, ultimately contributing to the advancement of intelligent systems in everyday life.
STNMamba: Mamba-based Spatial-Temporal Normality Learning for Video Anomaly Detection
Dec 28, 2024Video anomaly detection (VAD) has been extensively researched due to its potential for intelligent video systems. However, most existing methods based on CNNs and transformers still suffer from substantial computational burdens and have room for improvement in learning spatial-temporal normality. Recently, Mamba has shown great potential for modeling long-range dependencies with linear complexity, providing an effective solution to the above dilemma. To this end, we propose a lightweight and effective Mamba-based network named STNMamba, which incorporates carefully designed Mamba modules to enhance the learning of spatial-temporal normality. Firstly, we develop a dual-encoder architecture, where the spatial encoder equipped with Multi-Scale Vision Space State Blocks (MS-VSSB) extracts multi-scale appearance features, and the temporal encoder employs Channel-Aware Vision Space State Blocks (CA-VSSB) to capture significant motion patterns. Secondly, a Spatial-Temporal Interaction Module (STIM) is introduced to integrate spatial and temporal information across multiple levels, enabling effective modeling of intrinsic spatial-temporal consistency. Within this module, the Spatial-Temporal Fusion Block (STFB) is proposed to fuse the spatial and temporal features into a unified feature space, and the memory bank is utilized to store spatial-temporal prototypes of normal patterns, restricting the model's ability to represent anomalies. Extensive experiments on three benchmark datasets demonstrate that our STNMamba achieves competitive performance with fewer parameters and lower computational costs than existing methods.
Accelerating AIGC Services with Latent Action Diffusion Scheduling in Edge Networks
Dec 24, 2024



Artificial Intelligence Generated Content (AIGC) has gained significant popularity for creating diverse content. Current AIGC models primarily focus on content quality within a centralized framework, resulting in a high service delay and negative user experiences. However, not only does the workload of an AIGC task depend on the AIGC model's complexity rather than the amount of data, but the large model and its multi-layer encoder structure also result in a huge demand for computational and memory resources. These unique characteristics pose new challenges in its modeling, deployment, and scheduling at edge networks. Thus, we model an offloading problem among edges for providing real AIGC services and propose LAD-TS, a novel Latent Action Diffusion-based Task Scheduling method that orchestrates multiple edge servers for expedited AIGC services. The LAD-TS generates a near-optimal offloading decision by leveraging the diffusion model's conditional generation capability and the reinforcement learning's environment interaction ability, thereby minimizing the service delays under multiple resource constraints. Meanwhile, a latent action diffusion strategy is designed to guide decision generation by utilizing historical action probability, enabling rapid achievement of near-optimal decisions. Furthermore, we develop DEdgeAI, a prototype edge system with a refined AIGC model deployment to implement and evaluate our LAD-TS method. DEdgeAI provides a real AIGC service for users, demonstrating up to 29.18% shorter service delays than the current five representative AIGC platforms. We release our open-source code at https://github.com/ChangfuXu/DEdgeAI/.