 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Primitives are a Spatial Language for VLMs
May 12, 2026Vision-language models (VLMs) exhibit a striking paradox: they can generate executable code that reconstructs a 3D scene from geometric primitives with correct object counts, classes, and approximate positions, yet the same models fail at simpler spatial questions on the same image. We show that 3D geometric primitives (cubes, spheres, cylinders, expressed in executable code) serve as a powerful intermediate representation for spatial understanding, and exploit this through three contributions. First, we introduce \textbf{\textsc{SpatialBabel}}, a benchmark evaluating fourteen VLMs on primitive-based 3D scene reconstruction across six \emph{scene-code languages} (programming languages and declarative formats for 3D primitive scenes), revealing that a single model's object-detection F1 can vary by up to $5.7\times$ across languages. Second, we propose \textbf{Code-CoT} (Code Chain-of-Thought), a training-free inference strategy that routes spatial reasoning through primitive-based code generation. Code-CoT lifts the SpatialBabel-QA-Score by up to $+6.4$\% on primitive scenes and real-photo CV-Bench-3D accuracy by $+5.0$\% for VLMs with strong coding capabilities. Third, we propose \textbf{S$^{3}$-FT} (Self-Supervised Spatial Fine-Tuning), which self-supervisedly distills primitive spatial knowledge into general visual reasoning by parsing the model's own Three.js primitive-reconstructions into structured annotations and fine-tuning on the result, with \emph{no human labels and no teacher model}. Training on primitive images alone, S$^3$-FT improves Qwen3-VL-8B by $+4.6$ to $+8.6$\% on SpatialBabel-Primitive-QA, $+9.7$\% on CV-Bench-2D, and $+17$\% on HallusionBench; the recipe transfers across model families. These results establish geometric primitives in code as both a diagnostic and a transferable spatial vocabulary for VLMs. We will release all artifacts upon publication.
See, Think, Act: Online Shopper Behavior Simulation with VLM Agents
Oct 22, 2025LLMs have recently demonstrated strong potential in simulating online shopper behavior. Prior work has improved action prediction by applying SFT on action traces with LLM-generated rationales, and by leveraging RL to further enhance reasoning capabilities. Despite these advances, current approaches rely on text-based inputs and overlook the essential role of visual perception in shaping human decision-making during web GUI interactions. In this paper, we investigate the integration of visual information, specifically webpage screenshots, into behavior simulation via VLMs, leveraging OPeRA dataset. By grounding agent decision-making in both textual and visual modalities, we aim to narrow the gap between synthetic agents and real-world users, thereby enabling more cognitively aligned simulations of online shopping behavior. Specifically, we employ SFT for joint action prediction and rationale generation, conditioning on the full interaction context, which comprises action history, past HTML observations, and the current webpage screenshot. To further enhance reasoning capabilities, we integrate RL with a hierarchical reward structure, scaled by a difficulty-aware factor that prioritizes challenging decision points. Empirically, our studies show that incorporating visual grounding yields substantial gains: the combination of text and image inputs improves exact match accuracy by more than 6% over text-only inputs. These results indicate that multi-modal grounding not only boosts predictive accuracy but also enhances simulation fidelity in visually complex environments, which captures nuances of human attention and decision-making that text-only agents often miss. Finally, we revisit the design space of behavior simulation frameworks, identify key methodological limitations, and propose future research directions toward building efficient and effective human behavior simulators.
Shop-R1: Rewarding LLMs to Simulate Human Behavior in Online Shopping via Reinforcement Learning
Jul 23, 2025
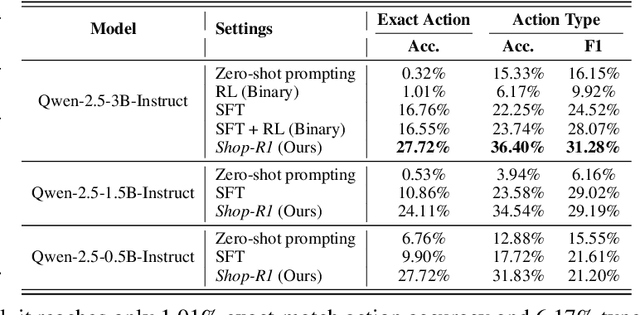
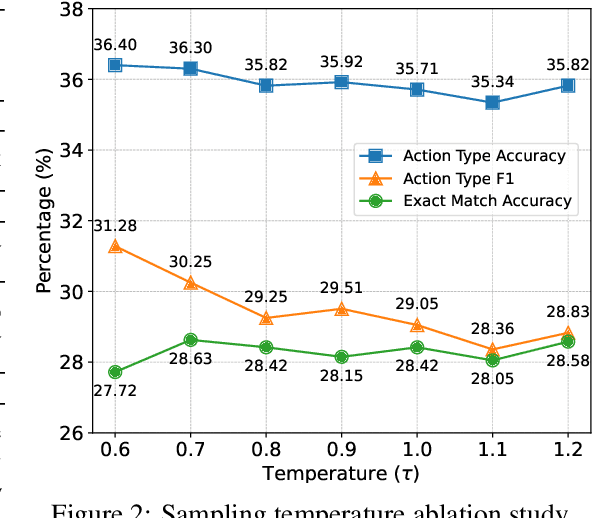
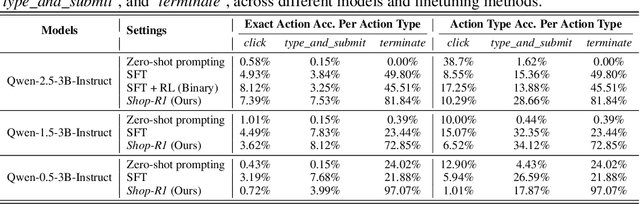
Large Language Models (LLMs) have recently demonstrated strong potential in generating 'believable human-like' behavior in web environments. Prior work has explored augmenting training data with LLM-synthesized rationales and applying supervised fine-tuning (SFT) to enhance reasoning ability, which in turn can improve downstream action prediction. However, the performance of such approaches remains inherently bounded by the reasoning capabilities of the model used to generate the rationales. In this paper, we introduce Shop-R1, a novel reinforcement learning (RL) framework aimed at enhancing the reasoning ability of LLMs for simulation of real human behavior in online shopping environments Specifically, Shop-R1 decomposes the human behavior simulation task into two stages: rationale generation and action prediction, each guided by distinct reward signals. For rationale generation, we leverage internal model signals (e.g., logit distributions) to guide the reasoning process in a self-supervised manner. For action prediction, we propose a hierarchical reward structure with difficulty-aware scaling to prevent reward hacking and enable fine-grained reward assignment. This design evaluates both high-level action types and the correctness of fine-grained sub-action details (attributes and values), rewarding outputs proportionally to their difficulty. Experimental results show that our method achieves a relative improvement of over 65% compared to the baseline.
InfoPO: On Mutual Information Maximization for Large Language Model Alignment
May 13, 2025We study the post-training of large language models (LLMs) with human preference data. Recently, direct preference optimization and its variants have shown considerable promise in aligning language models, eliminating the need for reward models and online sampling. Despite these benefits, these methods rely on explicit assumptions about the Bradley-Terry (BT) model, which makes them prone to overfitting and results in suboptimal performance, particularly on reasoning-heavy tasks. To address these challenges, we propose a principled preference fine-tuning algorithm called InfoPO, which effectively and efficiently aligns large language models using preference data. InfoPO eliminates the reliance on the BT model and prevents the likelihood of the chosen response from decreasing. Extensive experiments confirm that InfoPO consistently outperforms established baselines on widely used open benchmarks, particularly in reasoning tasks.
GraphStorm: all-in-one graph machine learning framework for industry applications
Jun 10, 2024



Graph machine learning (GML) is effective in many business applications. However, making GML easy to use and applicable to industry applications with massive datasets remain challenging. We developed GraphStorm, which provides an end-to-end solution for scalable graph construction, graph model training and inference. GraphStorm has the following desirable properties: (a) Easy to use: it can perform graph construction and model training and inference with just a single command; (b) Expert-friendly: GraphStorm contains many advanced GML modeling techniques to handle complex graph data and improve model performance; (c) Scalable: every component in GraphStorm can operate on graphs with billions of nodes and can scale model training and inference to different hardware without changing any code. GraphStorm has been used and deployed for over a dozen billion-scale industry applications after its release in May 2023. It is open-sourced in Github: https://github.com/awslabs/graphstorm.