 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow-Based Policy for Online Reinforcement Learning
Jun 15, 2025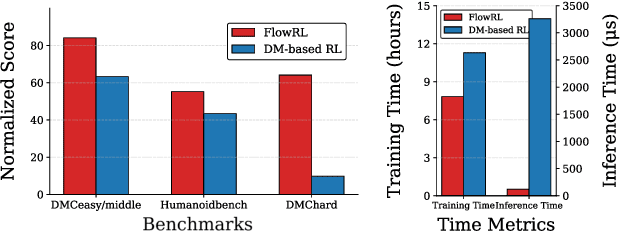



We present \textbf{FlowRL}, a novel framework for online reinforcement learning that integrates flow-based policy representation with Wasserstein-2-regularized optimization. We argue that in addition to training signals, enhancing the expressiveness of the policy class is crucial for the performance gains in RL. Flow-based generative models offer such potential, excelling at capturing complex, multimodal action distributions. However, their direct application in online RL is challenging due to a fundamental objective mismatch: standard flow training optimizes for static data imitation, while RL requires value-based policy optimization through a dynamic buffer, leading to difficult optimization landscapes. FlowRL first models policies via a state-dependent velocity field, generating actions through deterministic ODE integration from noise. We derive a constrained policy search objective that jointly maximizes Q through the flow policy while bounding the Wasserstein-2 distance to a behavior-optimal policy implicitly derived from the replay buffer. This formulation effectively aligns the flow optimization with the RL objective, enabling efficient and value-aware policy learning despite the complexity of the policy class. Empirical evaluations on DMControl and Humanoidbench demonstrate that FlowRL achieves competitive performance in online reinforcement learning benchmarks.
Chain-of-Action: Trajectory Autoregressive Modeling for Robotic Manipulation
Jun 11, 2025We present Chain-of-Action (CoA), a novel visuo-motor policy paradigm built upon Trajectory Autoregressive Modeling. Unlike conventional approaches that predict next step action(s) forward, CoA generates an entire trajectory by explicit backward reasoning with task-specific goals through an action-level Chain-of-Thought (CoT) process. This process is unified within a single autoregressive structure: (1) the first token corresponds to a stable keyframe action that encodes the task-specific goals; and (2) subsequent action tokens are generated autoregressively, conditioned on the initial keyframe and previously predicted actions. This backward action reasoning enforces a global-to-local structure, allowing each local action to be tightly constrained by the final goal. To further realize the action reasoning structure, CoA incorporates four complementary designs: continuous action token representation; dynamic stopping for variable-length trajectory generation; reverse temporal ensemble; and multi-token prediction to balance action chunk modeling with global structure. As a result, CoA gives strong spatial generalization capabilities while preserving the flexibility and simplicity of a visuo-motor policy. Empirically, we observe CoA achieves the state-of-the-art performance across 60 RLBench tasks and 8 real-world manipulation tasks.
BridgeVLA: Input-Output Alignment for Efficient 3D Manipulation Learning with Vision-Language Models
Jun 09, 2025Recently, leveraging pre-trained vision-language models (VLMs) for building vision-language-action (VLA) models has emerged as a promising approach to effective robot manipulation learning. However, only few methods incorporate 3D signals into VLMs for action prediction, and they do not fully leverage the spatial structure inherent in 3D data, leading to low sample efficiency. In this paper, we introduce BridgeVLA, a novel 3D VLA model that (1) projects 3D inputs to multiple 2D images, ensuring input alignment with the VLM backbone, and (2) utilizes 2D heatmaps for action prediction, unifying the input and output spaces within a consistent 2D image space. In addition, we propose a scalable pre-training method that equips the VLM backbone with the capability to predict 2D heatmaps before downstream policy learning. Extensive experiments show the proposed method is able to learn 3D manipulation efficiently and effectively. BridgeVLA outperforms state-of-the-art baseline methods across three simulation benchmarks. In RLBench, it improves the average success rate from 81.4% to 88.2%. In COLOSSEUM, it demonstrates significantly better performance in challenging generalization settings, boosting the average success rate from 56.7% to 64.0%. In GemBench, it surpasses all the comparing baseline methods in terms of average success rate. In real-robot experiments, BridgeVLA outperforms a state-of-the-art baseline method by 32% on average. It generalizes robustly in multiple out-of-distribution settings, including visual disturbances and unseen instructions. Remarkably, it is able to achieve a success rate of 96.8% on 10+ tasks with only 3 trajectories per task, highlighting its extraordinary sample efficiency. Project Website:https://bridgevla.github.io/
Robotic Policy Learning via Human-assisted Action Preference Optimization
Jun 08, 2025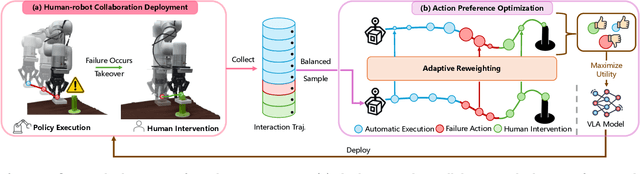



Establishing a reliable and iteratively refined robotic system is essential for deploying real-world applications. While Vision-Language-Action (VLA) models are widely recognized as the foundation model for such robotic deployment, their dependence on expert demonstrations hinders the crucial capabilities of correction and learning from failures. To mitigate this limitation, we introduce a Human-assisted Action Preference Optimization method named HAPO, designed to correct deployment failures and foster effective adaptation through preference alignment for VLA models. This method begins with a human-robot collaboration framework for reliable failure correction and interaction trajectory collection through human intervention. These human-intervention trajectories are further employed within the action preference optimization process, facilitating VLA models to mitigate failure action occurrences while enhancing corrective action adaptation. Specifically, we propose an adaptive reweighting algorithm to address the issues of irreversible interactions and token probability mismatch when introducing preference optimization into VLA models, facilitating model learning from binary desirability signals derived from interactions. Through combining these modules, our human-assisted action preference optimization method ensures reliable deployment and effective learning from failure for VLA models. The experiments conducted in simulation and real-world scenarios prove superior generalization and robustness of our framework across a variety of manipulation tasks.
Towards Generalist Robot Policies: What Matters in Building Vision-Language-Action Models
Dec 18, 2024
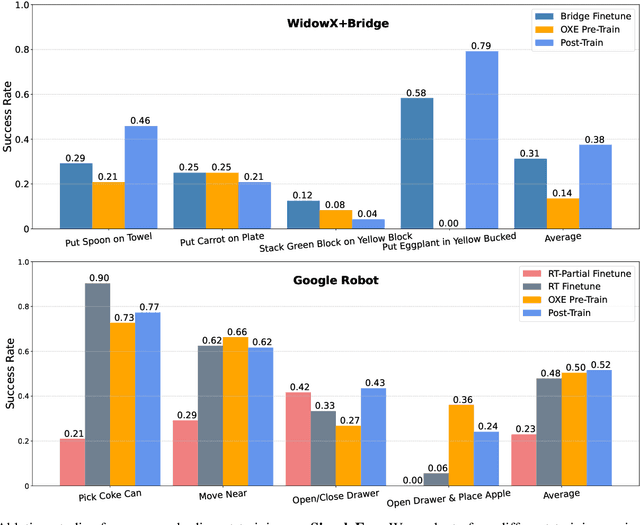

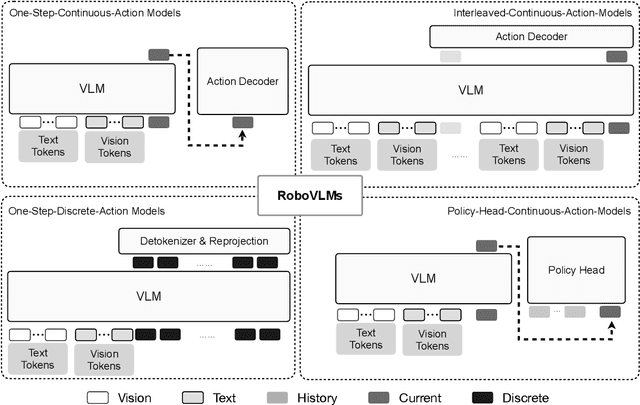
Foundation Vision Language Models (VLMs) exhibit strong capabilities in multi-modal representation learning, comprehension, and reasoning. By injecting action components into the VLMs, Vision-Language-Action Models (VLAs) can be naturally formed and also show promising performance. Existing work has demonstrated the effectiveness and generalization of VLAs in multiple scenarios and tasks. Nevertheless, the transfer from VLMs to VLAs is not trivial since existing VLAs differ in their backbones, action-prediction formulations, data distributions, and training recipes. This leads to a missing piece for a systematic understanding of the design choices of VLAs. In this work, we disclose the key factors that significantly influence the performance of VLA and focus on answering three essential design choices: which backbone to select, how to formulate the VLA architectures, and when to add cross-embodiment data. The obtained results convince us firmly to explain why we need VLA and develop a new family of VLAs, RoboVLMs, which require very few manual designs and achieve a new state-of-the-art performance in three simulation tasks and real-world experiments. Through our extensive experiments, which include over 8 VLM backbones, 4 policy architectures, and over 600 distinct designed experiments, we provide a detailed guidebook for the future design of VLAs. In addition to the study, the highly flexible RoboVLMs framework, which supports easy integrations of new VLMs and free combinations of various design choices, is made public to facilitate future research. We open-source all details, including codes, models, datasets, and toolkits, along with detailed training and evaluation recipes at: robovlms.github.io.
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Oct 08, 2024



We present GR-2, a state-of-the-art generalist robot agent for versatile and generalizable robot manipulation. GR-2 is first pre-trained on a vast number of Internet videos to capture the dynamics of the world. This large-scale pre-training, involving 38 million video clips and over 50 billion tokens, equips GR-2 with the ability to generalize across a wide range of robotic tasks and environments during subsequent policy learning. Following this, GR-2 is fine-tuned for both video generation and action prediction using robot trajectories. It exhibits impressive multi-task learning capabilities, achieving an average success rate of 97.7% across more than 100 tasks. Moreover, GR-2 demonstrates exceptional generalization to new, previously unseen scenarios, including novel backgrounds, environments, objects, and tasks. Notably, GR-2 scales effectively with model size, underscoring its potential for continued growth and application. Project page: \url{https://gr2-manipulation.github.io}.
World Model-based Perception for Visual Legged Locomotion
Sep 25, 2024



Legged locomotion over various terrains is challenging and requires precise perception of the robot and its surroundings from both proprioception and vision. However, learning directly from high-dimensional visual input is often data-inefficient and intricate. To address this issue, traditional methods attempt to learn a teacher policy with access to privileged information first and then learn a student policy to imitate the teacher's behavior with visual input. Despite some progress, this imitation framework prevents the student policy from achieving optimal performance due to the information gap between inputs. Furthermore, the learning process is unnatural since animals intuitively learn to traverse different terrains based on their understanding of the world without privileged knowledge. Inspired by this natural ability, we propose a simple yet effective method, World Model-based Perception (WMP), which builds a world model of the environment and learns a policy based on the world model. We illustrate that though completely trained in simulation, the world model can make accurate predictions of real-world trajectories, thus providing informative signals for the policy controller. Extensive simulated and real-world experiments demonstrate that WMP outperforms state-of-the-art baselines in traversability and robustness. Videos and Code are available at: https://wmp-loco.github.io/.
GR-MG: Leveraging Partially Annotated Data via Multi-Modal Goal Conditioned Policy
Aug 26, 2024The robotics community has consistently aimed to achieve generalizable robot manipulation with flexible natural language instructions. One of the primary challenges is that obtaining robot data fully annotated with both actions and texts is time-consuming and labor-intensive. However, partially annotated data, such as human activity videos without action labels and robot play data without language labels, is much easier to collect. Can we leverage these data to enhance the generalization capability of robots? In this paper, we propose GR-MG, a novel method which supports conditioning on both a language instruction and a goal image. During training, GR-MG samples goal images from trajectories and conditions on both the text and the goal image or solely on the image when text is unavailable. During inference, where only the text is provided, GR-MG generates the goal image via a diffusion-based image-editing model and condition on both the text and the generated image. This approach enables GR-MG to leverage large amounts of partially annotated data while still using language to flexibly specify tasks. To generate accurate goal images, we propose a novel progress-guided goal image generation model which injects task progress information into the generation process, significantly improving the fidelity and the performance. In simulation experiments, GR-MG improves the average number of tasks completed in a row of 5 from 3.35 to 4.04. In real-robot experiments, GR-MG is able to perform 47 different tasks and improves the success rate from 62.5% to 75.0% and 42.4% to 57.6% in simple and generalization settings, respectively. Code and checkpoints will be available at the project page: https://gr-mg.github.io/.
IRASim: Learning Interactive Real-Robot Action Simulators
Jun 20, 2024



Scalable robot learning in the real world is limited by the cost and safety issues of real robots. In addition, rolling out robot trajectories in the real world can be time-consuming and labor-intensive. In this paper, we propose to learn an interactive real-robot action simulator as an alternative. We introduce a novel method, IRASim, which leverages the power of generative models to generate extremely realistic videos of a robot arm that executes a given action trajectory, starting from an initial given frame. To validate the effectiveness of our method, we create a new benchmark, IRASim Benchmark, based on three real-robot datasets and perform extensive experiments on the benchmark. Results show that IRASim outperforms all the baseline methods and is more preferable in human evaluations. We hope that IRASim can serve as an effective and scalable approach to enhance robot learning in the real world. To promote research for generative real-robot action simulators, we open-source code, benchmark, and checkpoints at https: //gen-irasim.github.io.
SInViG: A Self-Evolving Interactive Visual Agent for Human-Robot Interaction
Feb 20, 2024



Linguistic ambiguity is ubiquitous in our daily lives. Previous works adopted interaction between robots and humans for language disambiguation. Nevertheless, when interactive robots are deployed in daily environments, there are significant challenges for natural human-robot interaction, stemming from complex and unpredictable visual inputs, open-ended interaction, and diverse user demands. In this paper, we present SInViG, which is a self-evolving interactive visual agent for human-robot interaction based on natural languages, aiming to resolve language ambiguity, if any, through multi-turn visual-language dialogues. It continuously and automatically learns from unlabeled images and large language models, without human intervention, to be more robust against visual and linguistic complexity. Benefiting from self-evolving, it sets new state-of-the-art on several interactive visual grounding benchmarks. Moreover, our human-robot interaction experiments show that the evolved models consistently acquire more and more preferences from human users. Besides, we also deployed our model on a Franka robot for interactive manipulation tasks. Results demonstrate that our model can follow diverse user instructions and interact naturally with humans in natural language, despite the complexity and disturbance of the environment.