 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Policy Learning via Human-assisted Action Preference Optimization
Jun 08, 2025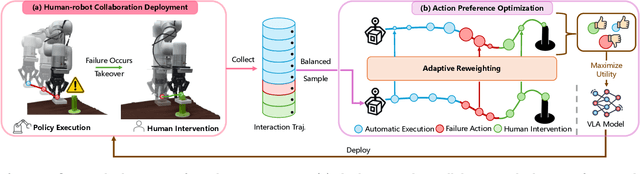



Establishing a reliable and iteratively refined robotic system is essential for deploying real-world applications. While Vision-Language-Action (VLA) models are widely recognized as the foundation model for such robotic deployment, their dependence on expert demonstrations hinders the crucial capabilities of correction and learning from failures. To mitigate this limitation, we introduce a Human-assisted Action Preference Optimization method named HAPO, designed to correct deployment failures and foster effective adaptation through preference alignment for VLA models. This method begins with a human-robot collaboration framework for reliable failure correction and interaction trajectory collection through human intervention. These human-intervention trajectories are further employed within the action preference optimization process, facilitating VLA models to mitigate failure action occurrences while enhancing corrective action adaptation. Specifically, we propose an adaptive reweighting algorithm to address the issues of irreversible interactions and token probability mismatch when introducing preference optimization into VLA models, facilitating model learning from binary desirability signals derived from interactions. Through combining these modules, our human-assisted action preference optimization method ensures reliable deployment and effective learning from failure for VLA models. The experiments conducted in simulation and real-world scenarios prove superior generalization and robustness of our framework across a variety of manipulation tasks.